






31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 107678位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 83752位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
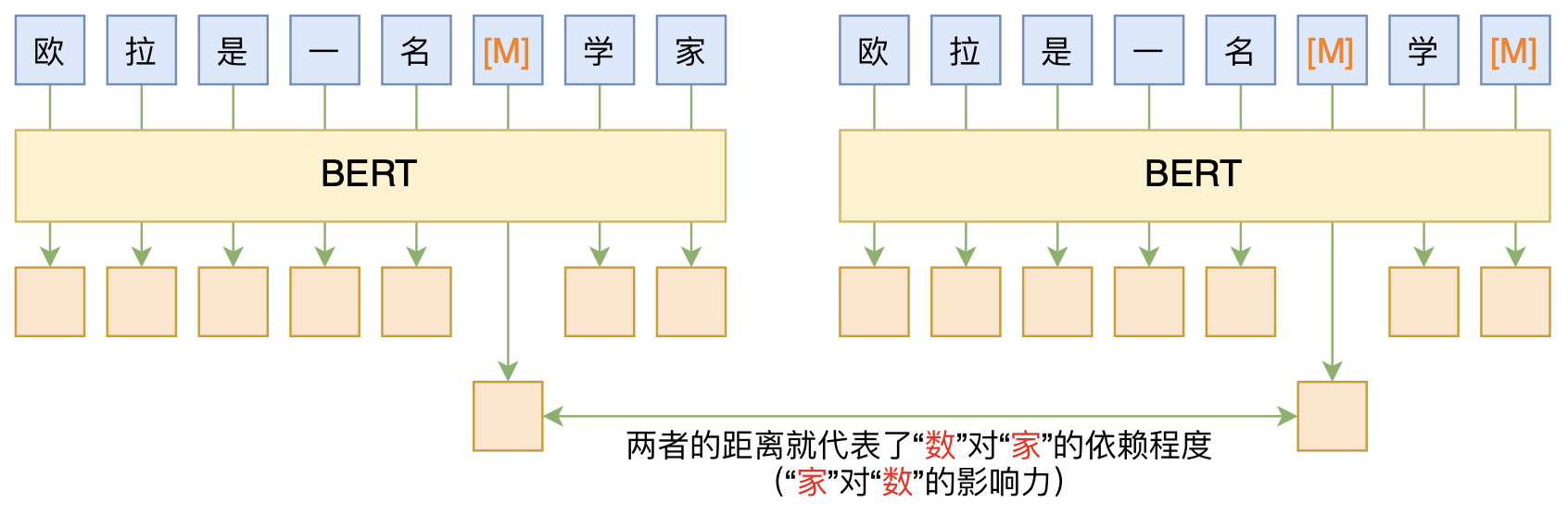
基于BERT的“token-token”相关度计算图示
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 90664位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 152807位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 66281位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
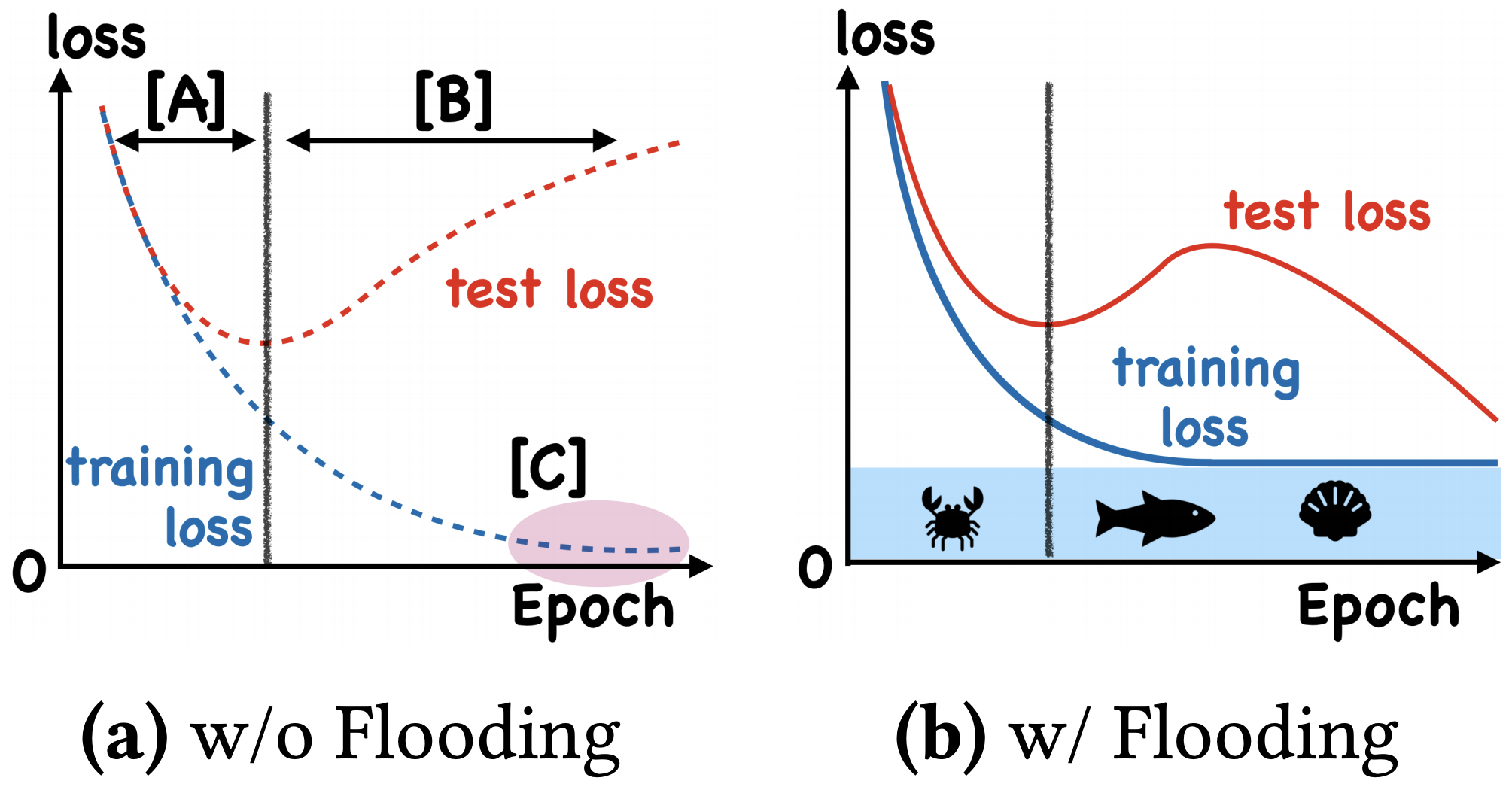
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
16
Apr
搜狐文本匹配:基于条件LayerNorm的多任务baseline
By 苏剑林 | 2021-04-16 | 86961位读者 | 引用前段时间看到了“2021搜狐校园文本匹配算法大赛”,觉得赛题颇有意思,便尝试了一下,不过由于比赛本身只是面向在校学生,所以笔者是不能作为正式参赛人员参赛的,因此把自己的做法开源出来,作为比赛baseline供大家参考。
赛题介绍
顾名思义,比赛的任务是文本匹配,即判断两个文本是否相似,本来是比较常规的任务,但有意思的是它分了多个子任务。具体来说,它分A、B两大类,A类匹配标准宽松一些,B类匹配标准严格一些,然后每个大类下又分为“短短匹配”、“短长匹配”、“长长匹配”3个小类,因此,虽然任务类型相同,但严格来看它是六个不同的子任务。
18
Sep
提速不掉点:基于词颗粒度的中文WoBERT
By 苏剑林 | 2020-09-18 | 109444位读者 | 引用当前,大部分中文预训练模型都是以字为基本单位的,也就是说中文语句会被拆分为一个个字。中文也有一些多颗粒度的语言模型,比如创新工场的ZEN和字节跳动的AMBERT,但这类模型的基本单位还是字,只不过想办法融合了词信息。目前以词为单位的中文预训练模型很少,据笔者所了解到就只有腾讯UER开源了一个以词为颗粒度的BERT模型,但实测效果并不好。
那么,纯粹以词为单位的中文预训练模型效果究竟如何呢?有没有它的存在价值呢?最近,我们预训练并开源了以词为单位的中文BERT模型,称之为WoBERT(Word-based BERT,我的BERT!),实验显示基于词的WoBERT在不少任务上有它独特的优势,比如速度明显的提升,同时效果基本不降甚至也有提升。在此对我们的工作做一个总结。
5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 105475位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
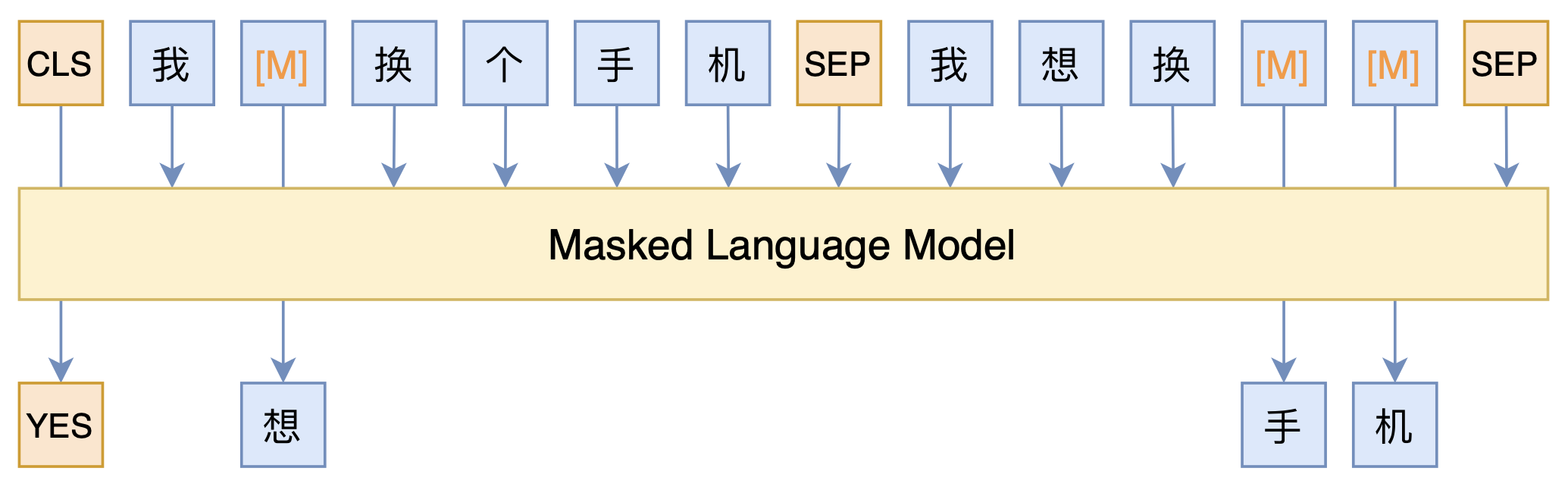
本文模型示意图

最近评论