






6
Nov
VQ的又一技巧:给编码表加一个线性变换
By 苏剑林 | 2024-11-06 | 58086位读者 |在《VQ的旋转技巧:梯度直通估计的一般推广》中,我们介绍了VQ(Vector Quantization)的Rotation Trick,它的思想是通过推广VQ的STE(Straight-Through Estimator)来为VQ设计更好的梯度,从而缓解VQ的编码表坍缩、编码表利用率低等问题。
无独有偶,昨天发布在arXiv上的论文《Addressing Representation Collapse in Vector Quantized Models with One Linear Layer》提出了改善VQ的另一个技巧:给编码表加一个线性变换。这个技巧单纯改变了编码表的参数化方式,不改变VQ背后的理论框架,但实测效果非常优异,称得上是简单有效的经典案例。
基础 #
由于在《VQ-VAE的简明介绍:量子化自编码器》、《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》等文章中我们已经多次介绍了VQ和VQ-VAE了,所以这里不再娓娓道来,直接给出普通AE和VQ-VAE的数学形式:
\begin{align}
\text{AE:}&\qquad z = encoder(x),\quad \hat{x}=decoder(z),\quad \mathcal{L}=\Vert x - \hat{x}\Vert^2 \\[12pt]
\text{VQ-VAE:}&\qquad\left\{\begin{aligned}
z =&\, encoder(x)\\[5pt]
z_q =&\, z + \text{sg}[q - z],\quad q = \mathop{\text{argmin}}_{e\in\{e_1,e_2,\cdots,e_K\}} \Vert z - e\Vert\\
\hat{x} =&\, decoder(z_q)\\[5pt]
\mathcal{L} =&\, \Vert x - \hat{x}\Vert^2 + \beta\Vert q - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[q]\Vert^2
\end{aligned}\right.\label{eq:vqvae}
\end{align}
再次强调老生常谈的一点:VQ-VAE不是VAE,它只是一个加上了VQ的AE,没有VAE的生成能力。而VQ则是将任意向量映射为编码表中与它最邻近的向量的操作,这个操作本身具有不可导的特性,所以通过STE来为encoder设计了梯度,并且新增了$\beta,\gamma$这两项损失,来为编码表提供梯度,同时也起到规整encoder表征的作用。
改动 #
论文将自己所提方法称为SimVQ,但没有解释Sim是什么含义,笔者猜测Sim是Simple的缩写,因为SimVQ的改动确实太Simple了:
\begin{equation}
\text{SimVQ-VAE:}\qquad\left\{\begin{aligned}
z =&\, encoder(x)\\[5pt]
z_q =&\, z + \text{sg}[q\color{red}{W} - z],\quad q = \mathop{\text{argmin}}_{e\in\{e_1,e_2,\cdots,e_K\}} \Vert z - e\color{red}{W}\Vert\\
\hat{x} =&\, decoder(z_q)\\[5pt]
\mathcal{L} =&\, \Vert x - \hat{x}\Vert^2 + \beta\Vert q\color{red}{W} - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[q\color{red}{W}]\Vert^2\end{aligned}\right.
\end{equation}
没错,就只是在编码表多乘了一个矩阵$W$,其他原封不动。
如果原本就是用式$\eqref{eq:vqvae}$训练VQ的,那么SimVQ可以直接简单上;如果原本是用EMA来更新编码表的(即$\beta=0$,然后用另外的滑动平均过程来更新编码表,这是VQ-VAE-2及后续一些模型的做法,在数学上等价于用SGD来优化编码表损失,而其他损失则可以用Adam等非SGD优化器),那么则需要取消这个操作,重新引入$\beta$项来端到端优化。
可能马上有读者质疑:这不就是将编码表的参数化从$E$改为$EW$吗?$EW$可以合并成一个矩阵,等价于一个新的$E$,按道理不改变模型的理论能力?是的,SimVQ对模型能力来说是不变的,但对SGD、Adam来说却是变的,它会改变优化器的学习过程,从而影响学习结果的好坏。
实验 #
进一步思考和分析之前,我们先看看SimVQ的实验效果。SimVQ做了视觉和音频的实验,比较有代表性的是Table 1:
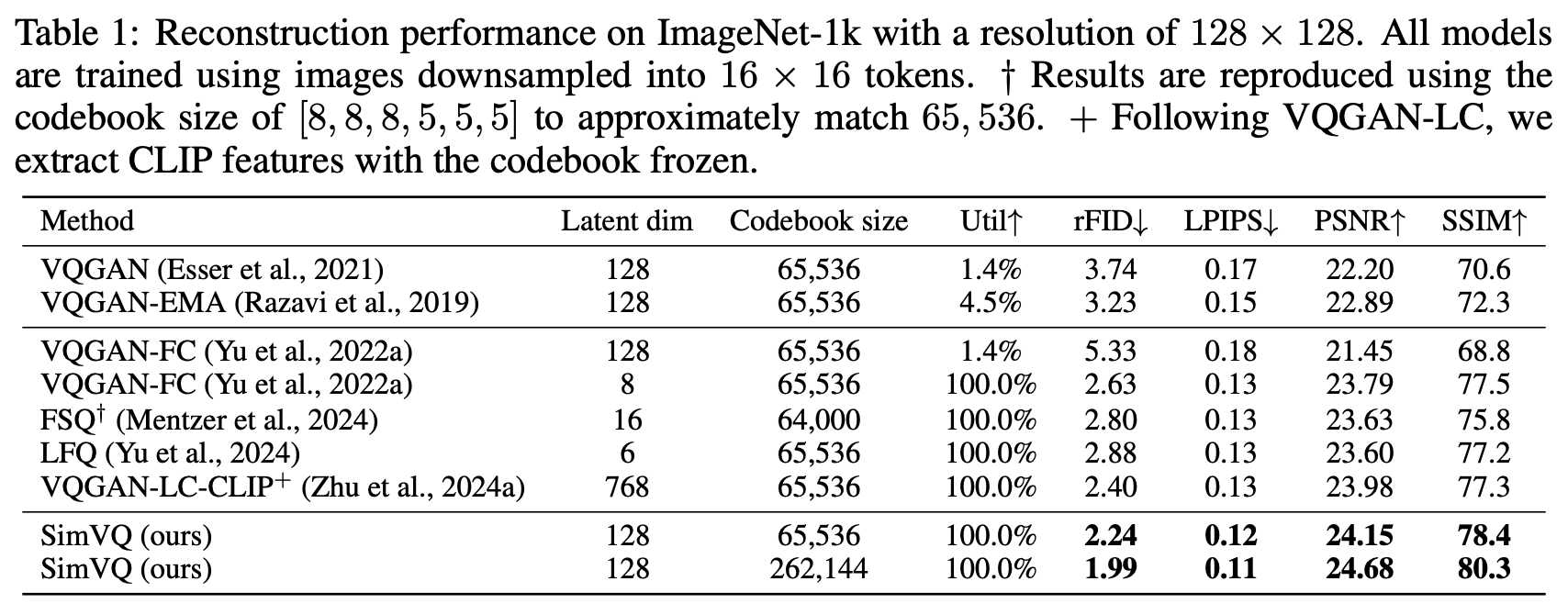
SimVQ的实验效果
根据论文的描述,SimVQ的代码就是在第一行VQGAN的代码上改的,改动就只有往VQ层插入了个线性变换,然后提升就非常显著了,不仅在相同编码表大小下达到了最优的重构质量,还能通过增加编码表大小进一步提高重构质量,这足以体现SimVQ的魅力——简单且有效。
笔者也在自己之前写的VQ-VAE代码上做了尝试,实测显示这个线性变换的加入,明显加速了VQ-VAE的收敛速度,并且最终的重构损失也有所降低。笔者还实验了$W$取对角阵的变体,这时候就相当于每个编码向量都element-wise地与一个参数向量(全一初始化)相乘,结果显示这样的变体也能起到相近的效果,介乎VQ与SimVQ之间。
分析 #
直观来想,VQ对编码表的更新是比较“孤立”的,比如某个样本$z$被VQ为$q$,那么这个样本的梯度就只会影响$q$,不会影响编码表里的其他向量;但SimVQ不同,它不单会更新$q$,还会更新$W$,从几何意义上看,$W$就相当于编码表的基底,一旦更新$W$,那么整个编码表就会更新了。所以说,SimVQ使得整个编码表的“联动”更为密切,从而更有机会找到更优的解,而不是陷入“各自为政”的局部最优。
那为什么SimVQ能提高编码表的利用率呢?这个其实也不难理解。再次根据$W$是编码表基底的解释,如果编码表利用率过低,那么$W$就会出现“各向异性”,即基底偏向于那些被利用起来的编码,可是一旦基底发生这种变化,那么它的线性组合应该也是偏向于被利用起来的编码,从而利用率不会太低。说白了,可学习的基底会自动让自己的利用率变高,从而让整个编码表的利用率都提高起来。
我们也可以从数学公式角度来描述这个过程。假设优化器为SGD,那么VQ中编码$e_i$的更新为
\begin{equation}e_i^{(t+1)} = e_i^{(t)} - \eta\frac{\partial \mathcal{L}}{\partial e_i^{(t)}}\end{equation}
这样如果当前批次中$e_i$没有被选中,那么$\frac{\partial \mathcal{L}}{\partial e_i^{(t)}}$为零,当前编码表就不更新了。但如果$e_i$被参数化为$q_i W$,那么
\begin{equation}\begin{aligned}
q_i^{(t+1)} =&\, q_i^{(t)} - \eta\frac{\partial \mathcal{L}}{\partial q_i^{(t)}} = q_i^{(t)} - \eta \frac{\partial \mathcal{L}}{\partial e_i^{(t)}} W^{(t)}{}^{\top}\\
W^{(t+1)} =&\, W^{(t)} - \eta\frac{\partial \mathcal{L}}{\partial W^{(t)}} = W^{(t)} - \eta \sum_i q_i^{(t)}{}^{\top}\frac{\partial \mathcal{L}}{\partial e_i^{(t)}} \\
e_i^{(t+1)}=&\,q_i^{(t+1)}W^{(t+1)}\approx e_i^{(t)} - \eta\left(\frac{\partial \mathcal{L}}{\partial e_i^{(t)}} W^{(t)}{}^{\top}W^{(t)} + q_i^{(t)}\sum_i q_i^{(t)}{}^{\top}\frac{\partial \mathcal{L}}{\partial e_i^{(t)}}\right)
\end{aligned}\end{equation}
可以看到:
1、$W$是基于全体被选中的编码的梯度之和来更新的,所以它自然会更倾向于高利用率方向;
2、由于$q_i^{(t)}\sum_i q_i^{(t)}{}^{\top}\frac{\partial \mathcal{L}}{\partial e_i^{(t)}}$的存在,不管编码$i$有没有被选中,它的更新都几乎不会为零;
3、$q_i^{(t)}\sum_i q_i^{(t)}{}^{\top}\frac{\partial \mathcal{L}}{\partial e_i^{(t)}}$相当于是高利用率方向的投影,它使得每个编码都往高利用率方向走。
然而,物极必反,如果全体编码都使劲往高利用率方向走,那么反而可能会导致编码表坍缩(codebook collapse),因此SimVQ默认采用了一个很保守的策略:只更新$W$,所有的$q$在随机初始化后就不更新了,这样一来就几乎杜绝了编码表坍缩的可能性。好消息是,在适当的编码维度下,实验显示$q,W$都更新和只更新$W$的表现都差不多,所以读者可以按照自己的偏好选择具体的形式。
延伸 #
抛开VQ的背景,像SimVQ这种引入额外的参数但又在数学上等价,即不改变模型的理论拟合能力,只改变优化过程的动力学的做法,我们称为“过参数化(Overparameterization)”。
过参数化在神经网络中并不鲜见,比如现在模型的主流架构是Pre Norm即$x + f(\text{RMSNorm}(x))$,RMSNorm最后所乘的$\gamma$向量通常都是过参数化的,因为$f$的第一层通常就是线性变换,比如Attention是线性变换投影到Q、K、V,FFN是线性变换来升维,等等,这些模型在推理阶段$\gamma$向量完全可以合并到$f$的线性变换中,但鲜有看到在训练阶段就把$\gamma$去掉的做法。
这是因为不少人认为,深度学习模型之所以“好训”,过参数化有不可忽视的作用,因此贸然去掉已经充分验证的模型的过参数化风险很大。这里的“好训”,主要是指梯度下降这种理论上容易陷入局部最优的方法居然经常可以找到一个实际表现很好的解,这本身就是一件很不可思议的事情。还有《On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization》等工作,表明过参数化隐式地加速了训练,作用类似于SGD中的动量。
最后,VQ本质上可以理解为一种稀疏训练方案,所以SimVQ所带来的启发和改动,也许还能用于其他稀疏训练模型,比如MoE(Mixture of Experts)。当前的MoE训练方案中,Expert之间的更新也是比较独立的,只有被Router选中的Expert才会更新参数,那么是不是有可能像SimVQ一样,所有的Expert后都接一个共享参数的线性变换,用来提高Expert的利用效率?当然MoE本身跟VQ也有很多不同之处,这还只是个猜测。
小结 #
本文介绍了VQ(Vector Quantization)的另一个训练技巧——SimVQ——只在VQ的编码表多加一个线性变换,无需其他改动,就能达到加速收敛、提升编码利用率、降低重构损失等效果,相当简单有效。
转载到请包括本文地址:https://spaces.ac.cn/archives/10519
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 06, 2024). 《VQ的又一技巧:给编码表加一个线性变换 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/10519
@online{kexuefm-10519,
title={VQ的又一技巧:给编码表加一个线性变换},
author={苏剑林},
year={2024},
month={Nov},
url={\url{https://spaces.ac.cn/archives/10519}},
}

November 6th, 2024
感谢苏神对我们工作的的介绍推广,也欢迎大家点个star。https://github.com/youngsheen/SimVQ。博客最后关于moe的猜想和我们不谋而合,在这个project启动之初我们就规划了moe的实验想要解决expert selection collapse的问题,因为vq和moe的框架实在太过相似。但是可惜的是,在我们初步的实验中并未在moe上奏效,再加上计算资源和时间紧张遂放弃了moe的部分。最近随着hunyuan moe的开源,又激起了我重启moe实验的想法haha~
补充一下,在主实验中我们没有优化q而是只优化了w,q从高斯采样完就固定了(虽然消融实验中同时优化qw也能work)。所以某种程度上来说他和vae有一种隐隐约约的联系,或许可以找到一个统一的方案合并vqvae和vae,但我还没想通。苏神怎么看simvq和vae的相似性。
欢迎作者莅临指导!
1、MoE本身问题就比较多,可能还需要细细抽丝剥茧,一时半会确实不好出结果;
2、不过VQ跟MoE的训练技巧还是有明显差距的,MoE的主要目的是要省训练成本,训练期间不用碰到没有被select出来的expert,但VQ还是要跟全体code算距离,才能把q算出来;
3、关于只优化$W$的操作,我在博客也补充上去了,不过个人实测当code dim不大时,只优化$W$的效果貌似不如都优化。
看这个论文的时候感觉方法很巧妙,我以为iclr能得高分呢。点进审稿意见看了下,审稿人也太离谱了,无了个大语。
巧妙,但简单,而顶会的审稿人很难接受简单的东西,或者说,越简单的东西,他们越容易看懂,因此越容易提出各种稀奇古怪(乱七八糟)的问题并打低分。
November 10th, 2024
与 Mixture-of-Subspaces in Low-Rank Adaptation 这篇文章的方法异曲同工
这个联系就有点勉强了。
November 20th, 2024
虽然不做这个方向,但是也去看了一下原文。
从结果来看,我感觉似乎C其实是weight vector,而W其实才是Codebook。C随机初始化后frozen,相当于从原始的one-hot式选择code变成了选择加权系数vector来融合code。
非常棒,前几天我也刚好想到这一点,确实也可以理解为将code的原始编码从高维的one hot改为低维的随机采样,但这只能解释fixed住C的做法了,如果C也可训练,那还是本文的解释更适合一些。
December 10th, 2024
苏老师您好,跟您请教一个基本的问题,很多论文中证明codebook ultization接近100%,请问论文中的码本利用率的计算方式是什么,是统计训练过程中codebook中每一个ei都用到了吗,只要ei被使用过一次也算是有效统计吗?
好像是这样,我没细看,你可能要自己确认一下。
他代码里就是在训练的时候只要用过了就算利用到了,其实我认为应该在验证集中统计,并且每次都从0开始统计。
December 11th, 2024
苏老师好,刚回顾了三篇你写的关于 VQ 的文章,收获很多。我想分享一个回读论文的时候发现一个有意思的点:
我是NLP出身,所以一个很自然的想法是用 Gumble-softmax 解决 argmin/argmax 问题。这是一个比 STE 以及 FSQ 更自然简单的方式实现 end-to-end training。如果加W可以work,我感觉Gumble也应该会可以work的,但是似乎VQVAE论文有提到说:
"Recently a few authors have suggested the use of a new continuous reparemetrisation based on the
so-called Concrete [25] or Gumbel-softmax [19] distribution, which is a continuous distribution and
has a temperature constant that can be annealed during training to converge to a discrete distribution
in the limit. In the beginning of training the variance of the gradients is low but biased, and towards
the end of training the variance becomes high but unbiased. "
这点让我还挺惊讶的。
用Gumbel Softmax去训练VQ-VAE效果确实会变差,这一点我最近也在思考中~
December 14th, 2024
苏老师,看您的博客学的VAE,准备学习扩散模型,看了您的VQVAE,受益匪浅,但是没找到关于VQGAN的文章呀,这是LDM很关键的一步,是我找漏了嘛
VQGAN就是VQVAE加上判别器和对抗Loss,这是很自然的思路,不需要新开一篇博客介绍了。
噢噢噢谢谢苏老师!真的受益匪浅
没有啊,VQGAN里面结合了transformer用作训练的,这一部分是我比较不能理解的地方
ViT不是很普遍了吗
May 19th, 2025
苏神您好!关于 VQ-VAE 的 codebook 优化,有两个问题想请教:
1: 若仅优化投影矩阵 $W$ 而固定 codebook $E$,是否会限制模型的表达能力?直接优化 $E$:可以学习任意的 $N \times d$ 矩阵,表达空间应该更自由,固定 $E$ 仅优化 $W$:可表达的向量是不是受限于 $E$ 的初始选择。
2: 原文采用:
$$ z_q = z + \text{sg}[z_q - z] $$
$$ q = \text{argmin}_{e_i \in E} \| z_q - eW \| $$
能否推广为:
$$ q = \text{argmin}_{e_i \in E} \| z_q - f(e, E) \| $$
其中 $f(e, E)$ 是某种基于全体 codebook 的变换(拍脑袋想,比如注意力),这样也可以让所有的 code 参与更新了,而且也不会有问题 1 里的限制。
1、可能会,看实验吧,但感觉影响不会太大;
2、都可以试,但应该不建议太复杂的,否则成本太大。