






5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 151553位读者 |最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
模型概览 #
整个模型的思路,其实就是之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》所介绍的PET(Pattern-Exploiting Training)的变体,用一个MLM模型来完成所有,示意图如下:
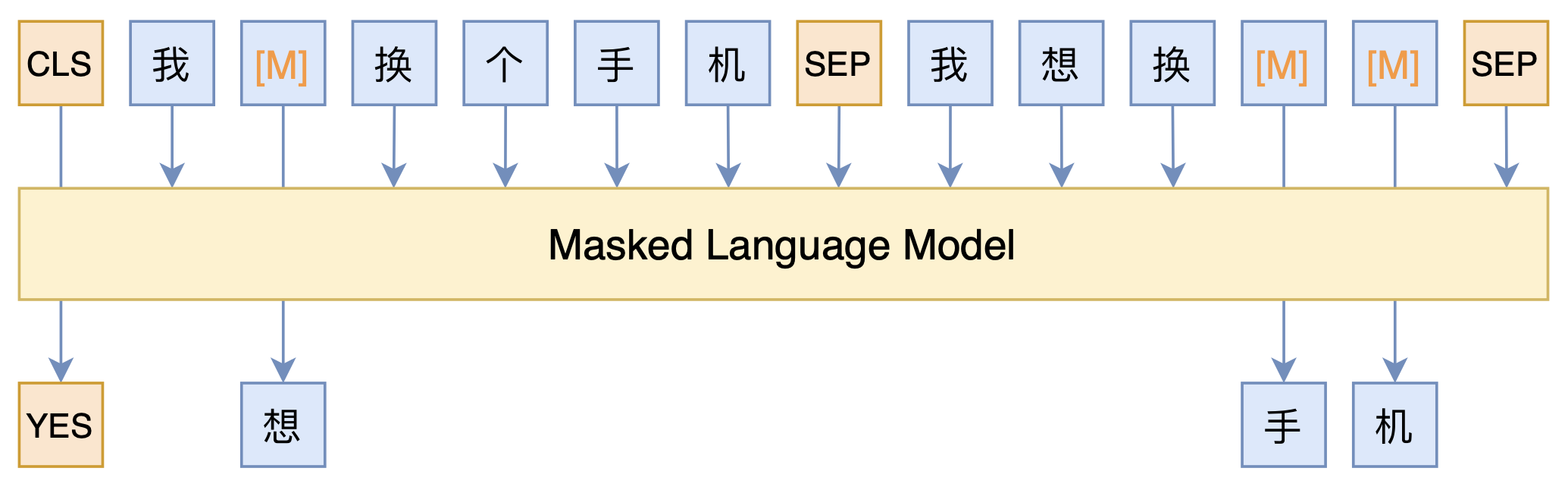
本文模型示意图
可以看到,全模型就只是一个MLM模型。具体来说,我们在词表里边添加了[YES]和[NO]两个标记,用来表示句子之间的相似性,通过[CLS]对应的输出向量来预测句子对的标签([YES]或[NO]),然后构建语料的方式,就是常规的把句子对拼接起来,两个句子随机mask掉一些token,然后在对应的输出位置预测这个token。
这样一来,我们同时做了句子对的分类任务([CLS]的预测结果),也做了MLM的预训练任务(其他被mask掉的token),而且没有标签的样本(比如测试集)也可以扔进去训练,只要不预测[CLS]就行了。于是我们通过MLM模型,把分类、预训练和半监督都结合起来了~
重用BERT #
脱敏数据还可以用BERT吗?当然是可以的,脱敏数据对于BERT来说,其实就是Embedding层不一样而已,其他层还是很有价值的。所以重用BERT主要还是通过预训练重新对齐Embedding层。
在这个过程中,初始化很重要。首先,我们把BERT的Embedding层中的[UNK]、[CLS]、[SEP]等特殊标记拿出来,这部分不变;然后,我们分别统计密文数据和明文数据的字频,明文数据指的是任意的开源通用语料,不一定要密文数据对应的明文数据;接着按照频率简单对齐明文字表和密文字表。这样一来,我们就可以按照明文的字来取出BERT的Embedding层来作为相应的初始化。
简单来说,就是我用最高频的明文字对应的BERT Embedding,来初始化最高频的密文字,依此类推来做一个基本的字表对齐。个人的对比实验表明,这个操作可以明显加快模型的收敛速度。
代码分享 #
说到这里,模型就基本介绍完了,这样的操作我目前使用base版本的bert,在排行榜上的分数是0.866,线下则已经是0.952了(单模型,没做K-fold融合,大家的线上线下差距貌似都蛮大)。这里分享自己的bert4keras实现:
关于明文数据的词频,我已经实现统计好一份,也同步在Github了,大家直接用就好。建议大家训练完100个epoch,在3090上大概要6小时。
对了,如果你想用Large版本的BERT,不建议用哈工大开源的RoBERTa-wwm-ext-large,理由在《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》已经说过了,该版本不知道为啥随机初始化了MLM部分的权重,而我们需要用到MLM权重。需要用Large版本的,推荐用腾讯UER开源的BERT Large。
文本小结 #
也没啥,就是分享了个比赛的简单baseline,顺便水了篇博客而已,希望对大家有所帮助~
转载到请包括本文地址:https://spaces.ac.cn/archives/8213
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 05, 2021). 《短文本匹配Baseline:脱敏数据使用预训练模型的尝试 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8213
@online{kexuefm-8213,
title={短文本匹配Baseline:脱敏数据使用预训练模型的尝试},
author={苏剑林},
year={2021},
month={Mar},
url={\url{https://spaces.ac.cn/archives/8213}},
}

April 6th, 2021
苏神想请教下..如果需要在这个训练好的预训练模型下进行下游任务,词典需要怎样修改呢
一般不用修改
April 12th, 2021
请问明文数据的词频是使用什么语料统计的呢
百科语料
May 3rd, 2021
苏神,你好!
"单模型,没做K-flod融合",此处应改为:k-fold
谢谢,已经修正。
May 14th, 2021
苏神你好!
y_pred = model.predict(x_true)[:, 0, 5:7]这里想请教一下,这里取出的[CLS]的长度是词表长度。但正常不应该是embedding_size吗?是接了一个[embedding_size,vocab_size]的dense吗?想确认一下
因为是小白看源码半天没有定位到对应位置= =,问的哪里不对还请海涵
认真理解文章,这是一个MLM模型。
June 28th, 2021
请教一些苏神你是如何再3090上使用bert4keras的,貌似30系的显卡都只支持cuda11.0以上的,这和tensorflow2.3以下的版本不兼容
用nvidia自己维护的tensorflow 1.15
https://developer.nvidia.com/zh-cn/blog/accelerating-tensorflow-on-a100-gpus/
October 7th, 2021
请问这一行是如何得出正确标签的?y_pred = y_pred[:, 1] / (y_pred.sum(axis=1) + 1e-8)(因为最近才看到文章,身边没有比赛数据去验证)
这一项明显只是得到预测结果呀,哪有正确标签?
不好意思我表述有误,意思就是得到预测标签。上一行是y_pred = model.predict(x_true)[:, 0, 5:7],这个我看懂了,是拿出no和yes的预测概率值。y_pred = y_pred[:, 1] / (y_pred.sum(axis=1) + 1e-8) 这个我没看懂,麻烦解释一下。 另外又想到了一个问题,用PET可以用MLM模型完成所有,那么如果用传统做法,先用MLM做进一步的pretrain,后finetune用[CLS]做分类也是可以的吧?两者效果上会有比较大的差异吗?
1、除以(y_pred.sum(axis=1) + 1e-8)的作用很明显啊,就是在yes和no之间重新归一化,然后y_pred[:, 1]就是取出yes的概率值作为最终的预测结果;
2、据说先pretrain然后finetune效果会更好。
非常感谢! 那PET效果没那么好的话,优点是在于高效吗(只训练一次模型)?
还有一个不成熟的想法,可以先训练一个其他词向量比如word2vec去替换bert的embedding再去finetune吗?是不是可以跟词频对应一样起到加速收敛的效果?
就当时来看,只是验证这种思路作为一个baseline,并没有说一定要找一个最好的方法。
word2vec的效果不知,无法评价。