






24
Oct
VQ的旋转技巧:梯度直通估计的一般推广
By 苏剑林 | 2024-10-24 | 50607位读者 |随着多模态LLM的方兴未艾,VQ(Vector Quantization)的地位也“水涨船高”,它可以作为视觉乃至任意模态的Tokenizer,将多模态数据统一到自回归生成框架中。遗憾的是,自VQ-VAE首次提出VQ以来,其理论并没有显著进步,像编码表的坍缩或利用率低等问题至今仍亟待解决,取而代之的是FSQ等替代方案被提出,成为了VQ有力的“竞争对手”。
然而,FSQ并不能在任何场景下都替代VQ,所以VQ本身的改进依然是有价值的。近日笔者读到了《Restructuring Vector Quantization with the Rotation Trick》,它提出了一种旋转技巧,声称能改善VQ的一系列问题,本文就让我们一起来品鉴一下。
回顾 #
早在五年前的博文《VQ-VAE的简明介绍:量子化自编码器》中我们就介绍过了VQ-VAE,后来在《简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE》介绍FSQ的时候,也再次仔细地温习了VQ-VAE,还不了解的读者可以先阅读这两篇文章。
VQ-VAE虽然被冠以VAE之名,但它实际上只是一个AE,并没有VAE的生成能力。它跟普通AE的区别是,它的编码结果是一个离散序列而非连续型向量,即它可以将连续型或离散型的数据编码为一个离散序列,并且允许解码器通过这个离散离散来重构原始输入,这就如同文本的Tokenizer——将输入转换为另一个离散序列,然后允许通过这个离散序列来恢复原始文本——所以它被视作任意模态的Tokenizer。
用公式来说,普通的AE是:
\begin{equation}z = encoder(x),\quad \hat{x}=decoder(z),\quad \mathcal{L}=\Vert x - \hat{x}\Vert^2 \end{equation}
而VQ-VAE则是
\begin{equation}\begin{aligned}
z =&\, encoder(x)\\[5pt]
z_q =&\, z + \text{sg}[q - z],\quad q = \mathop{\text{argmin}}_{e\in\{e_1,e_2,\cdots,e_K\}} \Vert z - e\Vert\\
\hat{x} =&\, decoder(z_q)\\[5pt]
\mathcal{L} =&\, \Vert x - \hat{x}\Vert^2 + \beta\Vert q - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[q]\Vert^2
\end{aligned}\end{equation}
其中“VQ”主要就是指从$z$变换到$q$的过程,它将$z$映射成$e_1,e_2,\cdots,e_K$之一,这些$e_i$就称为编码表(Codebook),也是可学习的向量。而训练VQ-VAE的“神之一手”,就是$z_q = z + \text{sg}[q - z]$这一步,它称为梯度的“直通估计器(Straight-Through Estimator,STE)”。
STE #
直通估计的出现,是因为从$z$到$q$的变换包含了不可导的$\text{argmin}$运算,所以没法直接将梯度传播到编码器中,换句话说编码器是没法训练的。为此,VQ-VAE想了一个技巧,它利用stop_gradient算子和$q$与$z$的最邻近特性,在反向传播时用$z$替换$q$,也就是$z_q = z + \text{sg}[q - z]$。
此时,前向计算等价于$\text{sg}$不存在,所以$z_q = z + q - z = q$,即送入Deocder的是$q$,而求梯度时$\text{sg}$的梯度等于0,所以$\nabla z_q = \nabla z$,所以梯度可以绕过不可导算子直达编码器,这就是“直通估计器”。不过这样一来,编码器是能优化了,但编码表却不能优化了,所以VQ-VAE往损失函数中加入了$\beta\Vert q - \text{sg}[z]\Vert^2$来优化编码表,其意图类似K-Means,希望$q$等于所有与它最邻近的$z$的中心。最后的$\gamma\Vert z - \text{sg}[q]\Vert^2$,则希望编码器也主动配合来促进这种聚类特性。
从梯度的链式法则角度看,我们有
\begin{equation}\frac{\partial \mathcal{L}}{\partial z} = \frac{\partial q}{\partial z}\frac{\partial \mathcal{L}}{\partial q}\end{equation}
注意这里$z,q$都是向量,所以$\frac{\partial \mathcal{L}}{\partial z},\frac{\partial \mathcal{L}}{\partial q}$也都是向量,而$\frac{\partial q}{\partial z}$则是一个矩阵。由于$z$到$q$的不可导性,所以问题卡在$\frac{\partial q}{\partial z}$没有良好定义,而STE则相当于假设了$\frac{\partial q}{\partial z}=I$(单位矩阵),所以$\frac{\partial \mathcal{L}}{\partial z} = \frac{\partial \mathcal{L}}{\partial q}$。这个设置自然有一定的合理性,但有没有什么改进空间呢?
直观上来看,STE导致的结果是,对于属于同一个$q$的所有$z$,它们的梯度都是相同的$\frac{\partial \mathcal{L}}{\partial q}$,而跟$z,q$的距离远近无关,这似乎就是一个可改进的地方:我们是否可以定义更一般的$\frac{\partial q}{\partial z}$,使得它跟$z,q$的差异大小有关呢?为了达到这个目的,我们先将STE推广成
\begin{equation}z_q = \text{sg}[G]z + \text{sg}[q - Gz]\end{equation}
其中$G$是一个矩阵。再次根据前向传播$\text{sg}$不存在、反向传播$\text{sg}$梯度为零的原则,可以得出$z_q = q$、$\frac{\partial \mathcal{L}}{\partial z_q} = G\frac{\partial \mathcal{L}}{\partial z}$,这就相当于定义了$\frac{\partial q}{\partial z}=G$。
旋转 #
那怎么选择$G$呢?文章开头所提的论文提出了一个参考方案,基于从$z$到$q$的旋转变换来构建$G$,即论文标题中的“Rotation Trick”。
具体来说,原论文考虑了$Gz = q$的简单情形,此时$\text{sg}[q - Gz]$自动为零,从而简化成$z_q = \text{sg}[G]z$。为了找到矩阵$G$,我们先将$z,q$都归一化为单位向量$\tilde{z} = \frac{z}{\Vert z\Vert},\tilde{q} = \frac{q}{\Vert q\Vert}$,那么就可以构建一个从$\tilde{z}$到$\tilde{q}$的旋转变换。具体的构造方式我们在《从一个单位向量变换到另一个单位向量的正交矩阵》已经探讨过,答案是
\begin{equation}R = I + 2\tilde{q}\tilde{z}^{\top}-
\frac{(\tilde{q} + \tilde{z})(\tilde{q} + \tilde{z})^{\top}}{1 + \cos\theta} = I + 2\tilde{q}\tilde{z}^{\top}-
2\left(\frac{\tilde{q} + \tilde{z}}{\Vert\tilde{q} + \tilde{z}\Vert}\right)\left(\frac{\tilde{q} + \tilde{z}}{\Vert\tilde{q} + \tilde{z}\Vert}\right)^{\top}
\end{equation}
其中$\theta$是$q,z$的夹角。利用这个结果,我们可以写出
\begin{equation}\tilde{q}=R\tilde{z}\quad\Rightarrow\quad q = \frac{\Vert q\Vert}{\Vert z\Vert} R z\quad\Rightarrow\quad G = \frac{\Vert q\Vert}{\Vert z\Vert} R\end{equation}
为了提高计算$Gz$的效率,我们通常选择利用矩阵乘法的结合律先计算$\tilde{z}^{\top}z$和$\left(\frac{\tilde{q} + \tilde{z}}{\Vert\tilde{q} + \tilde{z}\Vert}\right)^{\top}z$,但要注意我们实际上需要的是$\text{sg}[G]z$,所以要注意先停掉$\tilde{q},\tilde{z},\frac{\Vert q\Vert}{\Vert z\Vert}$的梯度再去计算$Gz$。
从几何意义上来看,$\frac{\partial q}{\partial z}=G=\frac{\Vert q\Vert}{\Vert z\Vert} R$,使得$\frac{\partial \mathcal{L}}{\partial q}$相对于$\frac{\partial \mathcal{L}}{\partial z}$的几何性质,跟$q$相对于$z$的几何性质是完全一致的,比如$\frac{\partial \mathcal{L}}{\partial q}$与$\frac{\partial \mathcal{L}}{\partial z}$的夹角等于$q$与$z$的夹角,它们的模长之比也相等,这些性质自然是有理论上的优雅性,但它是否真的能改善VQ-VAE的性能呢?接下来让我们转到实验部分。
实验 #
论文在相同的配置下对比了旧版STE和旋转技巧,发现旋转技巧的表现可谓“惊艳”:
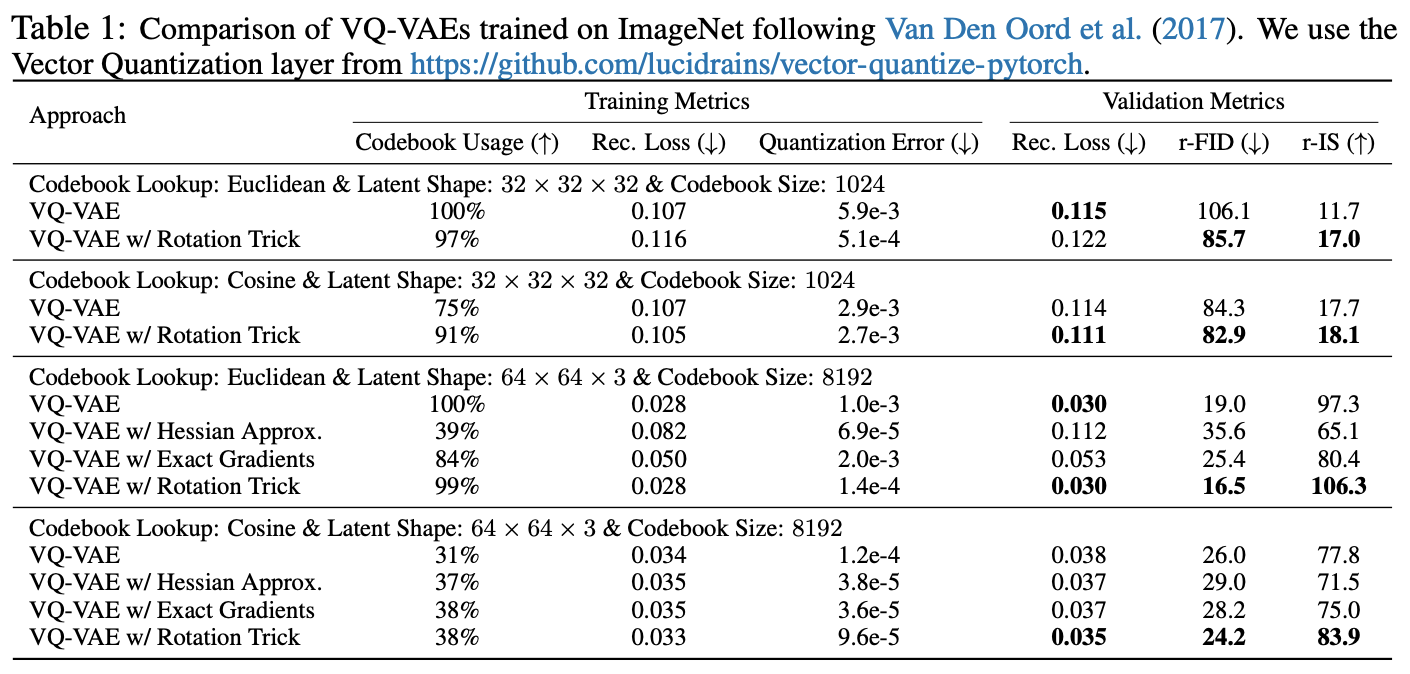
VQ-VAE + 旋转技巧的表现
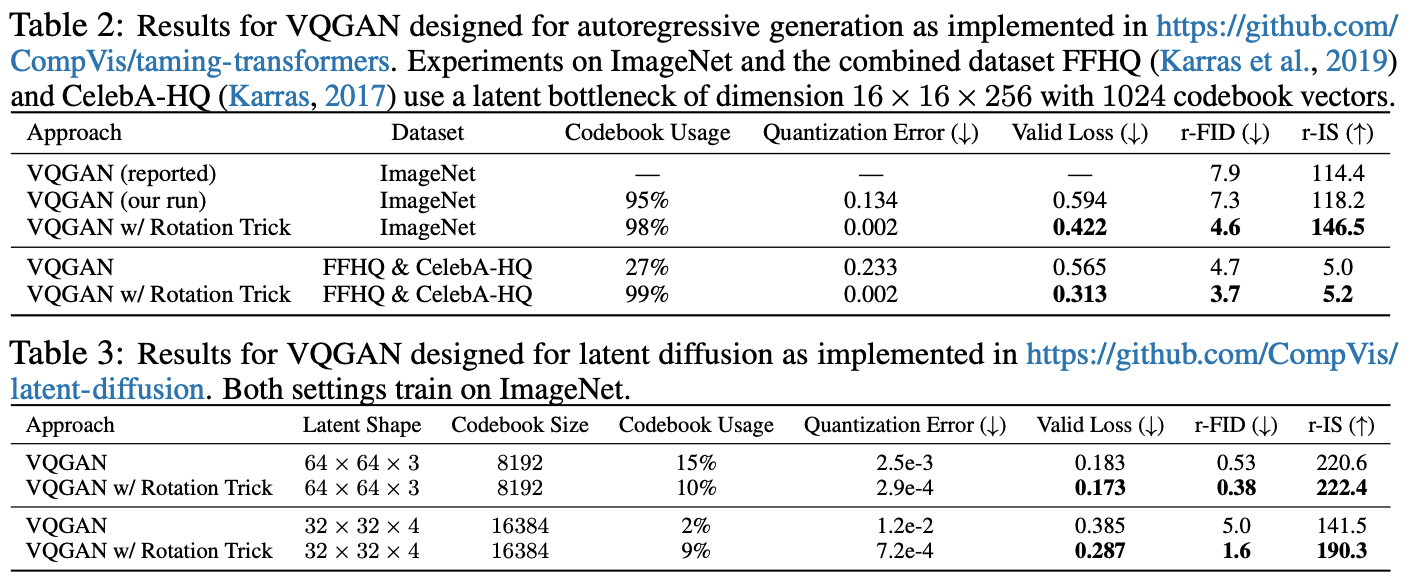
VQ-GAN + 旋转技巧的表现
简单来说,就是该高的地方(编码表利用率、IS)高、该低的地方(重构误差、Loss、FID)低,完全符合理想模型的特性了。论文的代码也已经开源,有兴趣的读者可以自行试跑一下。
思考 #
那这是不是意味着所有的VQ-VAE/VQ-GAN,都可以无脑上旋转技巧了呢?笔者在以前自己写的能跑通的VQ-VAE代码加上了旋转技巧,发现效果反而变得更差了,具体表现是重构损失$\Vert x - \hat{x}\Vert^2$变得更高,编码表损失$\Vert q - z\Vert^2$则更低了。
经过简单分析,笔者发现问题出在$\frac{\partial q}{\partial z}=G=\frac{\Vert q\Vert}{\Vert z\Vert} R$这个选择上,原本的STE则是$\frac{\partial q}{\partial z}=I$,这里旋转矩阵$R$跟单位矩阵$I$的尺度是相当的,所以旋转技巧尺度上多出了$\frac{\Vert q\Vert}{\Vert z\Vert}$。如果初始化时$\Vert q\Vert \ll \Vert z\Vert$(笔者写的VQ-VAE正好是这样),那么旋转技巧加持下重构损失的梯度就会比STE加持下重构损失的梯度小很多,于是对于编码器来说$\gamma\Vert z - \text{sg}[q]\Vert^2$这一项的梯度占了主导。
换句话说,初始阶段相当于只在优化$\beta\Vert q - \text{sg}[z]\Vert^2 + \gamma\Vert z - \text{sg}[q]\Vert^2$,这会导致$q,z\to 0$,即编码表坍缩,这就能解释编码表损失降低、重构损失增加的现象了。所以,从STE切换到旋转技巧大概率至少需要重新调一下$\gamma$。笔者简单看了一下论文的开源代码,里边应该是利用初始Encoder的K-Means来初始化编码表的,这样一来$\Vert q\Vert$与$\Vert z\Vert$的数量级不至于差太远,从而可以比较顺畅地切换。
不过,即便精调了$\gamma$,笔者也没在自己的VQ-VAE代码上调出更优的效果,所以笔者对旋转技巧的有效性保持观望态度。抛开实践不说,理论方面笔者也理解不了旋转技巧的有效性。原文的分析是,当$q$与$z$很相近时,$G$就很接近$I$,此时$\frac{\partial \mathcal{L}}{\partial z} \approx \frac{\partial \mathcal{L}}{\partial q}$是合理的,而当$q$与$z$距离较远,比如$z$位于类别$q$的边界附近时,$G$与$I$的差距较大,即$\frac{\partial \mathcal{L}}{\partial z}$明显偏离$\frac{\partial \mathcal{L}}{\partial q}$,于是$z$处于“乱飞”的状态,有助于$z$冲破“牢笼”而迈向新的类别,从而提高编码表的利用率。但很显然,这个解释让人觉得很“没底”。
此外,旋转技巧还有一个问题,就是它确立了一个具有超然地位的中心位置——原点。不难理解,VQ操作本身类似于K-Means聚类,而K-Means是无中心的,它具有平移不变性,而旋转则需要一个中心(原点),所以旋转技巧实际上跟VQ本意有点相悖。当然,VQ也可以改为按余弦值来找最邻近,这更契合旋转技巧,但也无法解释为什么旋转技巧对基于欧氏距离的VQ也有帮助。总的来说,旋转技巧起作用的根本原因,依旧是值得深思的问题。
最后,可能有读者疑问:既然VQ有这么多问题,为什么还要研究VQ呢?为什么不用更简单的FSQ呢?笔者认为,诸如FSQ等替代品,并不是在任何场景都能取代VQ,比如《VQ一下Key,Transformer的复杂度就变成线性了》介绍的Transformer-VQ,就很难用FSQ来替代VQ,因为它是每一层都要VQ一下,这样分配下来相当于说VQ的模型很小,而FSQ测试下来只有当模型足够大时表现才比VQ好。
小结 #
旋转技巧是近日arXiv上面提出的训练VQ(Vector Quantization)模型的新技术,它推广了原本的直通估计器(STE),声称能改善编码表的坍缩或利用率低等问题,本文对此进行了简单介绍,并给出了笔者对它的一些思考和疑问。
转载到请包括本文地址:https://spaces.ac.cn/archives/10489
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Oct. 24, 2024). 《VQ的旋转技巧:梯度直通估计的一般推广 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/10489
@online{kexuefm-10489,
title={VQ的旋转技巧:梯度直通估计的一般推广},
author={苏剑林},
year={2024},
month={Oct},
url={\url{https://spaces.ac.cn/archives/10489}},
}

October 24th, 2024
有尝试用 hadamard transform 之类的方法做旋转么? weight-only quantization 最近流行类似的方法,非常惊艳 https://github.com/Cornell-RelaxML/quip-sharp
简单看了一下,没太认真,感觉这个跟这里的VQ似乎关系不大,倒是感觉跟FSQ的关系大一点?
October 26th, 2024
今年ICLR25有另一篇VQ模型的投稿也有类似的思路,Addressing Representation Collapse in Vector Quantized Models with One Linear Layer,https://openreview.net/forum?id=SqUiGfJ1So。通过将codebook看成坐标基和N组系数的矩阵乘,只优化坐标基来避免码本的塌缩,实际上优化坐标基也就是在进行旋转拉伸,方法非常简单。最后实验看码本利用率,fid的效果也非常惊艳。
感谢分享。这篇文章的idea看起来靠谱一点,通过对codebook引入过参数化,使得一个code的优化会影响另一个code的结果,仔细推一下估计能得到正面的结果(不过这样就不大好用ema来更新codebook了只能用优化器来优化了)。
我印象中EMA的提出也是为了解决塌缩问题。这篇论文通过优化器直接就能fix掉塌缩问题也就不需要EMA了,而且end2end的优化器更简洁不是吗?
EMA也使得它更像K-Means求聚类中心这一操作。不过能端到端优化确实也够了,忽略我这看法。
October 29th, 2024
我实现也效果一般。
大佬的链式法则是否左右反了?
$$ \frac{\partial\mathcal{L}}{\partial z}=\frac{\partial q}{\partial z}\frac{\partial\mathcal{L}}{\partial q} $$
应该是
$$ \frac{\partial\mathcal{L}}{\partial z}=\frac{\partial\mathcal{L}}{\partial q}\frac{\partial q}{\partial z} $$
这样子结果有差别。
这个是左乘还是右乘,主要还是看对梯度的shape的约定而已。我通常希望约定$z$跟它的梯度$\frac{\partial\mathcal{L}}{\partial z}$一样的shape(比如都是列向量),所以文章中的链式法则没错;很多教程习惯约定$\frac{\partial\mathcal{L}}{\partial z}$的shape是$z$的转置的shape,就得到你的公式。
November 5th, 2024
看到评论区已经有人提到了,刚挂arxiv借苏神的平台宣传一下,[Addressing Representation Collapse in Vector Quantized Models with One Linear Layer](https://arxiv.org/abs/2411.02038),代码已经开源在https://github.com/youngsheen/SimVQ
就等你挂arxiv了hhh,要不然在OpenReview上匿名着不大好传播~
之前有看到这篇文章,看ICLR出分了关注了一下分数,感觉分数有点低,还准备rebbutle吗?
其实我个人也不算十分认可旋转技巧,只是它包含了STE一般化的思想,我个人感觉是学到了新东西的,所以来跟大家分享一下。
December 19th, 2024
感觉按照这篇文章讲的故事,它应该把commitment loss去掉。因为它说的是旋转技巧可以让z根据和q的距离和夹角,自适应的接近或远离这一类簇,而commitment loss强制z接近其当前被映射到的类簇上,跟它的故事是相反的
实际情况是去掉效果更差。