






14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 74852位读者 | 引用
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 75342位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 416930位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
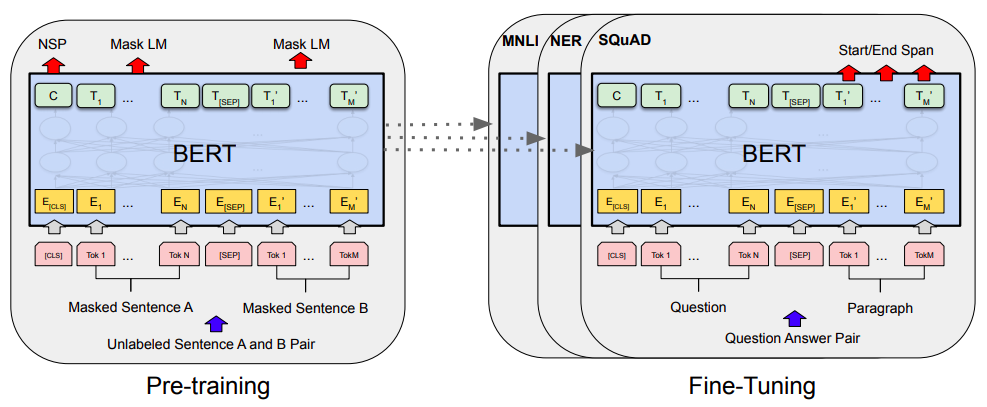
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
29
Apr
节省显存的重计算技巧也有了Keras版了
By 苏剑林 | 2020-04-29 | 48486位读者 | 引用不少读者最近可能留意到了公众号文章《BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)》,里边介绍了一个叫做“重计算”的技巧,简单来说就是用来省显存的方法,让平均训练速度慢一点,但batch_size可以增大好几倍。该技巧首先发布于论文《Training Deep Nets with Sublinear Memory Cost》,其实在2016年就已经提出了,只不过似乎还没有特别流行起来。
探索
公众号文章提到该技巧在pytorch和paddlepaddle都有原生实现了,但tensorflow还没有。但事实上从tensorflow 1.8开始,tensorflow就已经自带了该功能了,当时被列入了tf.contrib这个子库中,而从tensorflow 1.15开始,它就被内置为tensorflow的主函数之一,那就是tf.recompute_grad。
找到tf.recompute_grad之后,笔者就琢磨了一下它的用法,经过一番折腾,最终居然真的成功地用起来了,居然成功地让batch_size从48增加到了144!然而,在继续整理测试的过程中,发现这玩意居然在tensorflow 2.x是失效的...于是再折腾了两天,查找了各种资料并反复调试,最终算是成功地补充了这一缺陷。
最后是笔者自己的开源实现:
该实现已经内置在bert4keras中,使用bert4keras的读者可以升级到最新版本(0.7.5+)来测试该功能。
11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 108976位读者 | 引用去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
17
Sep
让人惊叹的Johnson-Lindenstrauss引理:理论篇
By 苏剑林 | 2021-09-17 | 82978位读者 | 引用今天我们来学习Johnson-Lindenstrauss引理,由于名字比较长,下面都简称“JL引理”。
个人认为,JL引理是每一个计算机科学的同学都必须了解的神奇结论之一,它是一个关于降维的著名的结果,它也是高维空间中众多反直觉的“维度灾难”现象的经典例子之一。可以说,JL引理是机器学习中各种降维、Hash等技术的理论基础,此外,在现代机器学习中,JL引理也为我们理解、调试模型维度等相关参数提供了重要的理论支撑。
对数的维度
JL引理,可以非常通俗地表达为:
通俗版JL引理: 塞下$N$个向量,只需要$\mathcal{O}(\log N)$维空间。
高三高考用考场,我们就放假了。无奈高三正兴致勃勃地写着作文的同时,我们这群“低年级”也得写作文。这一次作文是标题作文——《人与路》
人与路的关系是什么?是人在走路,还是路在指引着人?
不同的人会有不同的答案。但是在我看来,智者总在走路,而愚者却在“被走路”。走路的人清楚自己的方向,敢于追逐自己所喜欢的,拥有无畏的精神;“被走路”的人无法找到心中的罗盘,就好比云雾中的星光,飘忽不定。两个人的路的终点都是一样的,只是一个人走到了,一个人没有走到。
当我们在人生的大海中航行时,我们是否能够认识到,我们究竟在“走路”还是“被走路”呢?只有自己走路,才能够更好地追逐自己的梦想,使自己的人生更上一层楼!
8
Jul
科学空间:一种有趣的平方数
By 苏剑林 | 2009-07-08 | 20820位读者 | 引用数字是美丽的、极具魅力的,正如——
有这样的一种数,将其拆开成为两个数,这两个数的和的平方等于原数。例如:
$$\begin{aligned}2025=&(20+25)^2\\88209=&(88+209)^2\\152344237969=&(152344+237969)^2\\ &...\end{aligned}$$
下面是关于这类数的一些研究:
1、这类数的实质是:$(A+B)^2=10^nA+B$,而对于$(A+B)^2=kA+B$,有
$A=k/2-B\pm\sqrt{{k^2}/{4}-(k-1)B}$
因此,一般地,对于一个适合的B,可以找到两个对应的A。

最近评论