






26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 334931位读者 |今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
SimCSE #
首先,简单对SimCSE做个介绍。事实上,SimCSE可以看成是SimBERT的简化版(关于SimBERT请阅读《鱼与熊掌兼得:融合检索和生成的SimBERT模型》),它简化的部分如下:
1、SimCSE去掉了SimBERT的生成部分,仅保留检索模型;
2、由于SimCSE没有标签数据,所以把每个句子自身视为相似句传入。
说白了,本质上来说就是(自己,自己)作为正例、(自己,别人)作为负例来训练对比学习模型。当然,事实上还没那么简单,如果仅仅是完全相同的两个样本作为正例,那么泛化能力会大打折扣。一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身又是一个难搞的问题,SimCSE则提出了一个极为简单的方案:直接把Dropout当作数据扩增!
具体来说,$N$个句子经过带Dropout的Encoder得到向量$\boldsymbol{h}^{(0)}_1,\boldsymbol{h}^{(0)}_2,\cdots,\boldsymbol{h}^{(0)}_N$,然后让这批句子再重新过一遍Encoder(这时候是另一个随机Dropout)得到向量$\boldsymbol{h}^{(1)}_1,\boldsymbol{h}^{(1)}_2,\cdots,\boldsymbol{h}^{(1)}_N$,我们可以将$(\boldsymbol{h}^{(0)}_i,\boldsymbol{h}^{(1)}_i)$视为一对(略有不同的)正例了,那么训练目标为:
\begin{equation}-\sum_{i=1}^N\sum_{\alpha=0,1}\log \frac{e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(1-\alpha)}_i)/\tau}}{\sum\limits_{j=1,j\neq i}^N e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(\alpha)}_j)/\tau} + \sum\limits_j^N e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(1-\alpha)}_j)/\tau}}\end{equation}
英文效果 #
原论文的(英文)实验还是颇为丰富的,读者可以仔细阅读原文。但是要注意的是,原论文正文表格的评测指标跟BERT-flow、BERT-whitening的不一致,指标一致的表格在附录:
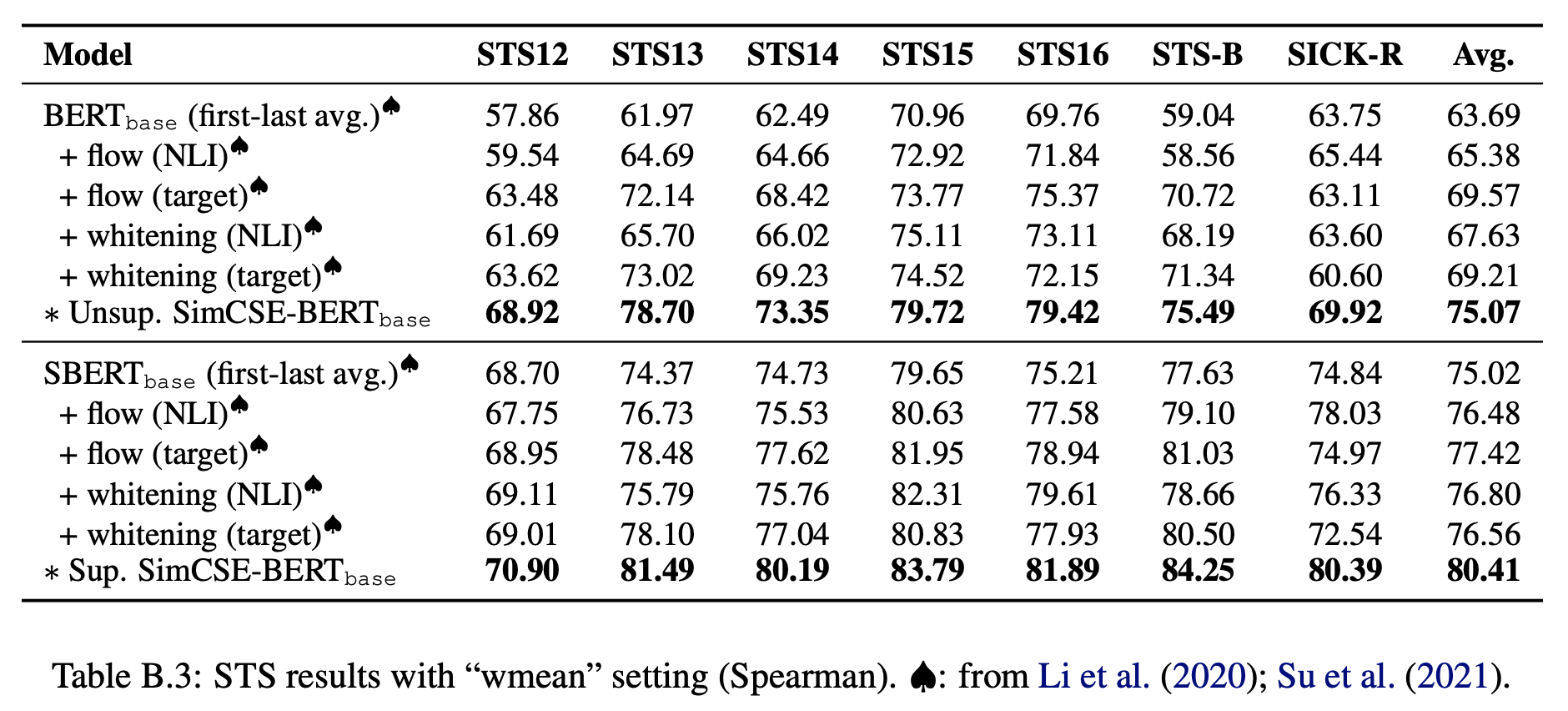
SimCSE与BERT-flow、BERT-whitening的效果对比
不管怎样比,SimCSE还是明显优于BERT-flow和BERT-whitening的。那么SimCSE的这个优势是不是普遍的呢?在中文上有没有这个优势呢?我们马上就来做实验。
实验配置 #
我们的中文实验基本与《无监督语义相似度哪家强?我们做了个比较全面的评测》对齐,包括之前测试的5个任务、4中Pooling以及所有base、small、tiny版的模型,large没有跑是因为相同配置下large模型OOM了。
经过调参,笔者发现中文任务上SimCSE的最优参数跟原论文中的不完全一致,具体区别如下:
1、原论文batch_size=512,这里是batch_size=64(实在跑不起这么壕的batch_size);
2、原论文的学习率是5e-5,这里是1e-5;
3、原论文的最优dropout比例是0.1,这里是0.3;
4、原论文的无监督SimCSE是在额外数据上训练的,这里直接随机选了1万条任务数据训练;
5、原文无监督训练的时候还带了个MLM任务,这里只有SimCSE训练。
最后一点再说明一下,原论文的无监督SimCSE是从维基百科上挑了100万个句子进行训练的,至于中文实验,为了实验上的方便以及对比上的公平,直接用任务数据训练(只用了句子,没有用标签,还是无监督的)。不过除了PAWSX之外,其他4个任务都不需要全部数据都拿来训练,经过测试,只需要随机选1万个训练样本训练一个epoch即可训练到最优效果(更多样本更少样本效果都变差)。
中文效果 #
SimCSE的所有中文实验结果如下:
$$\small{\begin{array}{l|ccccc}
\hline
& \text{ATEC} & \text{BQ} & \text{LCQMC} & \text{PAWSX} & \text{STS-B} \\
\hline
\text{BERT}\text{-P1} & 16.59 / 20.61 / \color{green}{33.14} & 29.35 / 25.76 / \color{green}{50.67} & 41.71 / 48.92 / \color{green}{69.99} & 15.15 / 17.03 / \color{red}{12.95} & 34.65 / 61.19 / \color{green}{69.04} \\
\text{BERT}\text{-P2} & 9.46 / 22.16 / \color{green}{25.18} & 16.97 / 18.97 / \color{green}{41.19} & 28.42 / 49.61 / \color{green}{56.45} & 13.93 / 16.08 / \color{red}{12.46} & 21.66 / 60.75 / \color{red}{57.63} \\
\text{BERT}\text{-P3} & 20.79 / 18.27 / \color{green}{32.89} & 33.08 / 22.58 / \color{green}{49.58} & 59.22 / 60.12 / \color{green}{71.83} & 16.68 / 18.37 / \color{red}{14.47} & 57.48 / 63.97 / \color{green}{70.08} \\
\text{BERT}\text{-P4} & 24.51 / 27.00 / \color{green}{31.96} & 38.81 / 32.29 / \color{green}{48.40} & 64.75 / 64.75 / \color{green}{71.49} & 15.12 / 17.80 / \color{red}{16.01} & 61.66 / 69.45 / \color{green}{70.03} \\
\hline
\text{RoBERTa}\text{-P1} & 24.61 / 29.59 / \color{green}{32.23} & 40.54 / 28.95 / \color{green}{50.61} & 70.55 / 70.82 / \color{green}{74.22} & 16.23 / 17.99 / \color{red}{12.25} & 66.91 / 69.19 / \color{green}{71.13} \\
\text{RoBERTa}\text{-P2} & 20.61 / 28.91 / \color{red}{20.07} & 31.14 / 27.48 / \color{green}{39.92} & 65.43 / 70.62 / \color{red}{62.65} & 15.71 / 17.30 / \color{red}{12.00} & 59.50 / 70.77 / \color{red}{61.49} \\
\text{RoBERTa}\text{-P3} & 26.94 / 29.94 / \color{green}{32.66} & 40.71 / 30.95 / \color{green}{51.03} & 66.80 / 68.00 / \color{green}{73.15} & 16.08 / 19.01 / \color{red}{16.47} & 61.67 / 66.19 / \color{green}{70.14} \\
\text{RoBERTa}\text{-P4} & 27.94 / 28.33 / \color{green}{32.40} & 43.09 / 33.49 / \color{green}{49.78} & 68.43 / 67.86 / \color{green}{72.74} & 15.02 / 17.91 / \color{red}{16.39} & 64.09 / 69.74 / \color{green}{70.11} \\
\hline
\text{NEZHA}\text{-P1} & 17.39 / 18.83 / \color{green}{32.14} & 29.63 / 21.94 / \color{green}{46.08} & 40.60 / 50.52 / \color{green}{60.38} & 14.90 / 18.15 / \color{red}{16.60} & 35.84 / 60.84 / \color{green}{68.50} \\
\text{NEZHA}\text{-P2} & 10.96 / 23.08 / \color{red}{15.70} & 17.38 / 28.81 / \color{green}{32.20} & 22.66 / 49.12 / \color{red}{21.07} & 13.45 / 18.05 / \color{red}{12.68} & 21.16 / 60.11 / \color{red}{43.35} \\
\text{NEZHA}\text{-P3} & 23.70 / 21.93 / \color{green}{31.47} & 35.44 / 22.44 / \color{green}{46.69} & 60.94 / 62.10 / \color{green}{69.65} & 18.35 / 21.72 / \color{red}{18.17} & 60.35 / 68.57 / \color{green}{70.68} \\
\text{NEZHA}\text{-P4} & 27.72 / 25.31 / \color{green}{30.26} & 44.18 / 31.47 / \color{green}{46.57} & 65.16 / 66.68 / \color{green}{67.21} & 13.98 / 16.66 / \color{red}{14.41} & 61.94 / 69.55 / \color{red}{68.18} \\
\hline
\text{WoBERT}\text{-P1} & 23.88 / 22.45 / \color{green}{32.66} & 43.08 / 32.52 / \color{green}{49.13} & 68.56 / 67.89 / \color{green}{72.99} & 18.15 / 19.92 / \color{red}{12.36} & 64.12 / 66.53 / \color{green}{70.00} \\
\text{WoBERT}\text{-P2} & \text{-} & \text{-} & \text{-} & \text{-} & \text{-} \\
\text{WoBERT}\text{-P3} & 24.62 / 22.74 / \color{green}{34.03} & 40.64 / 28.12 / \color{green}{49.77} & 64.89 / 65.22 / \color{green}{72.44} & 16.83 / 20.56 / \color{red}{14.55} & 59.43 / 66.57 / \color{green}{70.96} \\
\text{WoBERT}\text{-P4} & 25.97 / 27.24 / \color{green}{33.67} & 42.37 / 32.34 / \color{green}{49.09} & 66.53 / 65.62 / \color{green}{71.74} & 15.54 / 18.85 / \color{red}{14.00} & 61.37 / 68.11 / \color{green}{70.00} \\
\hline
\text{RoFormer}\text{-P1} & 24.29 / 26.04 / \color{green}{32.33} & 41.91 / 28.13 / \color{green}{49.13} & 64.87 / 60.92 / \color{green}{71.61} & 20.15 / 23.08 / \color{red}{15.25} & 59.91 / 66.96 / \color{green}{69.45} \\
\text{RoFormer}\text{-P2} & \text{-} & \text{-} & \text{-} & \text{-} & \text{-} \\
\text{RoFormer}\text{-P3} & 24.09 / 28.51 / \color{green}{34.23} & 39.09 / 34.92 / \color{green}{50.01} & 63.55 / 63.85 / \color{green}{72.01} & 16.53 / 18.43 / \color{red}{15.25} & 58.98 / 55.30 / \color{green}{71.44} \\
\text{RoFormer}\text{-P4} & 25.92 / 27.38 / \color{green}{34.10} & 41.75 / 32.36 / \color{green}{49.58} & 66.18 / 65.45 / \color{green}{71.84} & 15.30 / 18.36 / \color{red}{15.17} & 61.40 / 68.02 / \color{green}{71.40} \\
\hline
\text{SimBERT}\text{-P1} & 38.50 / 23.64 / \color{green}{36.98} & 48.54 / 31.78 / \color{green}{51.47} & 76.23 / 75.05 / \color{red}{74.87} & 15.10 / 18.49 / \color{red}{12.66} & 74.14 / 73.37 / \color{green}{75.12} \\
\text{SimBERT}\text{-P2} & 38.93 / 27.06 / \color{green}{37.00} & 49.93 / 35.38 / \color{green}{50.33} & 75.56 / 73.45 / \color{red}{72.61} & 14.52 / 18.51 / \color{green}{19.72} & 73.18 / 73.43 / \color{green}{75.13} \\
\text{SimBERT}\text{-P3} & 36.50 / 31.32 / \color{green}{37.81} & 45.78 / 29.17 / \color{green}{51.24} & 74.42 / 73.79 / \color{green}{73.85} & 15.33 / 18.39 / \color{red}{12.48} & 67.31 / 70.70 / \color{green}{73.18} \\
\text{SimBERT}\text{-P4} & 33.53 / 29.04 / \color{green}{36.93} & 45.28 / 34.70 / \color{green}{50.09} & 73.20 / 71.22 / \color{green}{73.42} & 14.16 / 17.32 / \color{red}{16.59} & 66.98 / 70.55 / \color{green}{72.64} \\
\hline
\text{SimBERT}_{\text{small}}\text{-P1} & 30.68 / 27.56 / \color{green}{31.16} & 43.41 / 30.89 / \color{green}{44.80} & 74.73 / 73.21 / \color{green}{74.32} & 15.89 / 17.96 / \color{red}{14.69} & 70.54 / 71.39 / \color{red}{69.85} \\
\text{SimBERT}_{\text{small}}\text{-P2} & 31.00 / 29.14 / \color{green}{30.76} & 43.76 / 36.86 / \color{green}{45.50} & 74.21 / 73.14 / \color{green}{74.55} & 16.17 / 18.12 / \color{red}{15.18} & 70.10 / 71.40 / \color{red}{69.18} \\
\text{SimBERT}_{\text{small}}\text{-P3} & 30.03 / 21.24 / \color{green}{30.07} & 43.72 / 31.69 / \color{green}{44.27} & 72.12 / 70.27 / \color{green}{71.21} & 16.93 / 21.68 / \color{red}{12.10} & 66.55 / 66.11 / \color{red}{64.95} \\
\text{SimBERT}_{\text{small}}\text{-P4} & 29.52 / 28.41 / \color{green}{28.56} & 43.52 / 36.56 / \color{green}{43.38} & 70.33 / 68.75 / \color{red}{68.35} & 15.39 / 21.57 / \color{red}{14.47} & 64.73 / 68.12 / \color{red}{63.23} \\
\hline
\text{SimBERT}_{\text{tiny}}\text{-P1} & 30.51 / 24.67 / \color{green}{30.04} & 44.25 / 31.75 / \color{green}{43.89} & 74.27 / 72.25 / \color{green}{73.47} & 16.01 / 18.07 / \color{red}{12.51} & 70.11 / 66.39 / \color{green}{70.11} \\
\text{SimBERT}_{\text{tiny}}\text{-P2} & 30.01 / 27.66 / \color{green}{29.37} & 44.47 / 37.33 / \color{green}{44.04} & 73.98 / 72.31 / \color{green}{72.93} & 16.55 / 18.15 / \color{red}{13.73} & 70.35 / 70.88 / \color{red}{69.63} \\
\text{SimBERT}_{\text{tiny}}\text{-P3} & 28.47 / 19.68 / \color{green}{28.08} & 42.04 / 29.49 / \color{green}{41.21} & 69.16 / 66.99 / \color{green}{69.85} & 16.18 / 20.11 / \color{red}{12.21} & 64.41 / 66.72 / \color{red}{64.62} \\
\text{SimBERT}_{\text{tiny}}\text{-P4} & 27.77 / 27.67 / \color{red}{26.25} & 41.76 / 37.02 / \color{green}{41.62} & 67.55 / 65.66 / \color{green}{67.34} & 15.06 / 20.49 / \color{red}{13.87} & 62.92 / 66.77 / \color{red}{60.80} \\
\hline
\end{array}}$$
其中每个单元的数据是“a/b/c”的形式,a是不加任何处理的原始结果,b是BERT-whitening的结果(没有降维),c则是SimCSE的结果,如果c > b,那么c显示为绿色,否则为红色,也就是说绿色越多,说明SimCSE比BERT-whitening好得越多。关于其他实验细节,可以看原代码以及《无监督语义相似度哪家强?我们做了个比较全面的评测》。
注意由于又有Dropout,训练时又是随机采样1万个样本,因此结果具有一定的随机性,重跑代码指标肯定会有波动,请读者知悉。
一些结论 #
从实验结果可以看出,除了PAWSX这个“异类”外,SimCSE相比BERT-whitening确实有压倒性优势,有些任务还能好10个点以上,在BQ上SimCSE还比有监督训练过的SimBERT要好,而且像SimBERT这种已经经过监督训练的模型还能获得进一步的提升,这些都说明确实强大。(至于PAWSX为什么“异”,文章《无监督语义相似度哪家强?我们做了个比较全面的评测》已经做过简单分析。)
同时,我们还可以看出在SimCSE之下,在BERT-flow和BERT-whitening中表现较好的first-last-avg这种Pooling方式已经没有任何优势了,反而较好的是直接取[CLS]向量,但让人意外的是,Pooler(取[CLS]的基础上再加个Dense)的表现又比较差,真让人迷惘~
由于BERT-whiteing只是一个线性变换,所以笔者还实验了单靠SimCSE是否能复现这个线性变换的效果。具体来说,就是固定Encoder的权重,然后接一个不加激活函数的Dense层,然后以SimCSE为目标,只训练最后接的Dense层。结果发现这种情况下的SimCSE并不如BERT-whitening。那就意味着,SimCSE要有效必须要把Encoder微调才行,同时也说明BERT-whitening可能包含了SimCSE所没有东西的,也许两者以某种方式进行结合会取得更好的效果(构思中...)。
相关工作 #
简单调研了一下,发现“自己与自己做正样本”这个思想的工作,最近都出现好几篇论文了,除了SimCSE之外,还有《Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks》、《Semantic Re-tuning with Contrastive Tension》都是极度相似的。其实类似的idea笔者也想过,只不过没想到真的能work(就没去做实验了),也没想到关键点是Dropout,看来还是得多多实验啊~
本文小结 #
本文分享了笔者在SimCSE上的中文实验,结果表明不少任务上SimCSE确实相当优秀,能明显优于BERT-whiteining。
转载到请包括本文地址:https://spaces.ac.cn/archives/8348
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 26, 2021). 《中文任务还是SOTA吗?我们给SimCSE补充了一些实验 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8348
@online{kexuefm-8348,
title={中文任务还是SOTA吗?我们给SimCSE补充了一些实验},
author={苏剑林},
year={2021},
month={Apr},
url={\url{https://spaces.ac.cn/archives/8348}},
}

November 1st, 2024
苏神您好,想请问下文本匹配的问题,主要两个问题
1.目前在相关任务上SimCSE/ESimCSE与发布的一些前沿Embedding模型比效果差些,从技术角度看是否合理,新的Embedding主要哪些角度进行了改进。相关Embedding模型也没在任务关联的数据上进行微调。
2.大模型直接做文本匹配,能够给出详细的可解释性,从小模型角度看,需要研究哪些技术或模型能够实现类似能力。
示例:
Q:从领域方向及研究对象分析 ,“三峡库区危岩协同监测预警技术研发与应用”与“基于遥感数据的三峡库区灾害预警与决策系统及应用”两个项目的相似度分值.
A:
研究对象
- 两个项目都以三峡库区的地质灾害为研究对象,特别是危岩体的变形和破坏情况,以及可能引发的灾害。
- 它们都关注地质灾害的发生机理、监测方法、预警技术等方面。
技术手段
- 两个项目都采用了先进的技术手段进行监测和预警。
- “三峡库区危岩协同监测预警技术研发与应用”可能更侧重于多种监测手段的协同应用,如北斗GNSS、物联网、大数据分析等。
- “基于遥感数据的三峡库区灾害预警与决策系统及应用”则更侧重于遥感技术的应用,通过遥感数据获取地质灾害的相关信息。
应用目标
- 两个项目的应用目标都是提高三峡库区地质灾害的监测预警能力,降低灾害损失。
- 它们都致力于构建有效的监测预警系统,为灾害防治提供科学依据。
相似度分值
基于以上分析,我认为这两个项目的相似度较高,但并非完全相同。它们在领域方向、研究对象和应用目标上高度一致,但在技术手段上略有差异。因此,我给出以下相似度分值(满分为10分):
相似度分值:8.5分
这个分值反映了两个项目在多个方面的相似性和共同目标,同时也考虑了它们在技术手段上的细微差异。需要注意的是,这个分值是基于当前信息的主观判断,实际情况可能因具体项目细节而有所不同。
Embedding压缩为单个向量,然后比较简单的度量如cos、欧氏距离,本就是一个以效率为主的算法,没法做很深入的交互。
像GPT直接做相似度,或者两个样本concat然后送入BERT做二分类的做法,才能做到更深层次的交互(参考 https://kexue.fm/archives/8860 ) ,但效率低(参考 https://kexue.fm/archives/9336 )。也有将两者结合的,即先粗筛后细排。总之实际中的花样很多,我也不完全了解。
January 4th, 2025
苏神,你在最后计算spearman相关系数时,使用的是两个句子相似度和标签两个向量来计算的。
我想请问,你的句子相似度计算用的是什么算法?
我看到代码中,你将一对句子分别交给模型预测,得到两个768维的句子向量,对这两个句子向量点乘再相加,就得到了这两句话的相似度。这是余弦相似度吗?
是余弦。因为两个向量是归一化的,所以内积就是余弦。
January 7th, 2025
苏神,您好。有一个问题想要请教。
在测评STS-B时能得到与您相近的结果。
但是测评LCQMC时,用1w条数据作为训练集,斯皮尔曼系数由第0个epoch的0.56到第7个epoch的0.38,结果非常不好。
我猜测的是因为STS-B的标签是0-5,更接近斯皮尔曼系数离散分布,但LCQMC只有0,1标签,属于2分类任务,所以测评效果比较差。
请问是什么问题导致,该如何解决呢?
标签的范围不影响相关系数。我的评测代码本来就是公开的,你可以认真对比一下每一步的输出。