






24
Sep
让人惊叹的Johnson-Lindenstrauss引理:应用篇
By 苏剑林 | 2021-09-24 | 52744位读者 | 引用上一篇文章《让人惊叹的Johnson-Lindenstrauss引理:理论篇》中,我们比较详细地介绍了Johnson-Lindenstrauss引理(JL引理)的理论推导,这一篇我们来关注它的应用。
作为一个内容上本身就跟降维相关的结论,JL引理最基本的自然就是作为一个降维方法来用。但除了这个直接应用外,很多看似不相关的算法,比如局部敏感哈希(LSH)、随机SVD等,本质上也依赖于JL引理。此外,对于机器学习模型来说,JL引理通常还能为我们的维度选择提供一些理论解释。
降维的工具
JL引理提供了一个非常简单直接的“随机投影”降维思路:
给定$N$个向量$v_1,v_2,\cdots,v_N\in\mathbb{R}^m$,如果想要将它降到$n$维,那么只需要从$\mathcal{N}(0,1/n)$中采样一个$n\times m$矩阵$A$,然后$Av_1,Av_2,\cdots,Av_N$就是降维后的结果。
17
Sep
让人惊叹的Johnson-Lindenstrauss引理:理论篇
By 苏剑林 | 2021-09-17 | 132165位读者 | 引用今天我们来学习Johnson-Lindenstrauss引理,由于名字比较长,下面都简称“JL引理”。
个人认为,JL引理是每一个计算机科学的同学都必须了解的神奇结论之一,它是一个关于降维的著名的结果,它也是高维空间中众多反直觉的“维度灾难”现象的经典例子之一。可以说,JL引理是机器学习中各种降维、Hash等技术的理论基础,此外,在现代机器学习中,JL引理也为我们理解、调试模型维度等相关参数提供了重要的理论支撑。
对数的维度
JL引理,可以非常通俗地表达为:
通俗版JL引理: 塞下$N$个向量,只需要$\mathcal{O}(\log N)$维空间。
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 255202位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
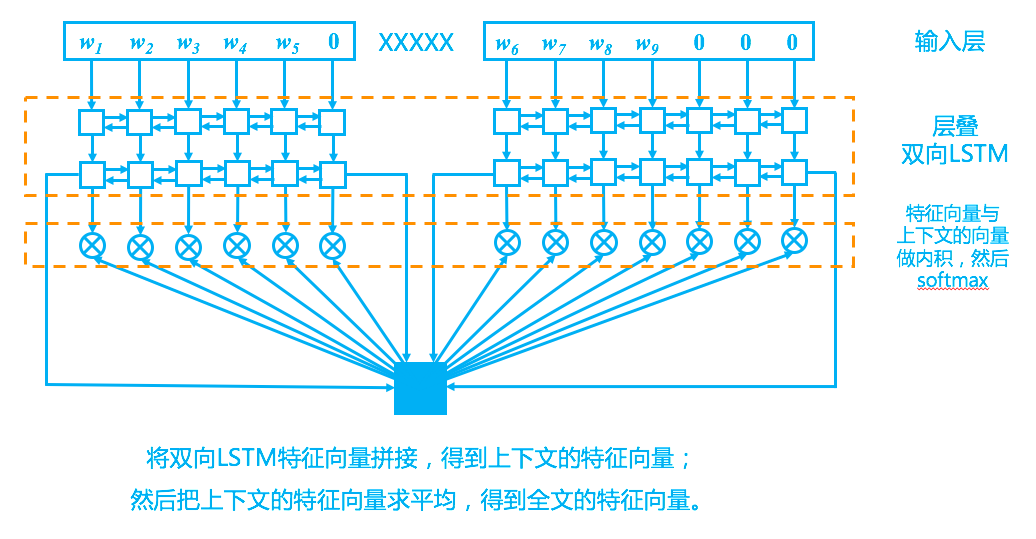
完形填空模型
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 768063位读者 | 引用
15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 49913位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 310341位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
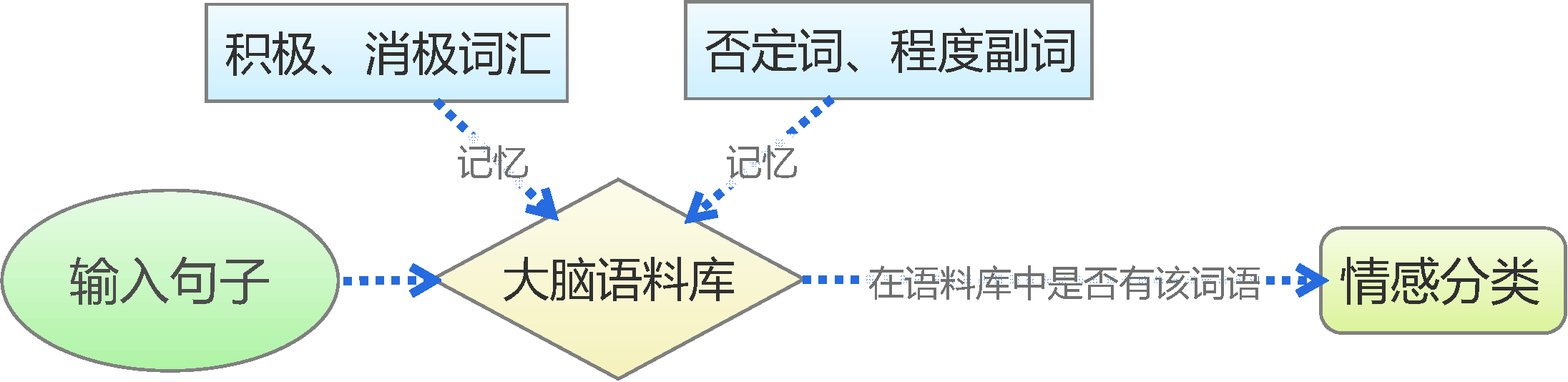
人的最简单的判断思维
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 106240位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。

最近评论