







方轮自行车
你见过正方形轮子的自行车吗?一般认为,只有圆形的车轮才能使我们的车子平稳向前移动,但这只是针对平直道路而言的。谁规定路一定是平的?只要铺好一条适当的道路,正方形车轮的自行车照样可以平稳前行!本文就让我们为方轮自行车铺一条路。
其实,方轮自行车已经不是新鲜玩意了,它早已出现在不少科技馆中。从图片中可以看到,它的特殊轨道是有许多段弧组成的,每一段弧的长度等于正方形的边长。车轮前行时,正方形会保持与弧形相切(确保不会打滑)。这样的路的形状是什么曲线呢?很幸运,它并不十分复杂,而且让人意外的是,它就是我们之前已经研究过的“悬链线”!原来,要设计这样的一个曲线的轨道,不需要多么高深的设计师,只需要我们手拿一条铁链,让它自由垂下......
19
Jul
【备忘】在自己的电脑上搭建服务器
By 苏剑林 | 2012-07-19 | 58486位读者 | 引用写在前面:作为离散数学的实验作业,我选择了研究数独。经过测试发现,数独的自动推理还不算难,我把两种常规的推理思路转化为了计算机代码,并结合了随机性推导,得到了一个解题能力还不错的数独程序。事实上,本文的程序还可以进一步优化,以得到更高能力的数独程序(只需要整理一下代码,加上几个循环和判断即可),但是我实在太懒,没有动力继续弄下去了,就这样先和大家分享吧。最后,笔者认为本文的算法是更接近我们的思维的算法。
数独简介
历史
相传数独源起于拉丁方阵(Latin Square),1970年代在美国发展,改名为数字拼图(Number Place)、之后流传至日本并发扬光大,以数学智力游戏智力拼图游戏发表。在1984年一本游戏杂志《パズル通信ニコリ》正式把它命名为数独,意思是“在每一格只有一个数字”。后来一位前任香港高等法院的新西兰籍法官高乐德(Wayne Gould)在1997年3月到日本东京旅游时,无意中发现了。他首先在英国的《泰晤士报》上发表,不久其他报纸也发表,很快便风靡全英国,之后他用了6年时间编写了电脑程式,并将它放在网站上,使这个游戏很快在全世界流行。
台湾于2005年5月由“中国时报”首度引进, 且每日连载, 亦造成很大的回响。台湾数独发展协会(Taiwan Sudoku Association, 简称 TSA)亦为世界解谜联盟会员。香港是在2005年7月30日由AM730在创刊时引入数独。中国大陆是在2007年2月28日正式引入数独。北京晚报智力休闲数独俱乐部(数独联盟前身)在新闻大厦举行加入世界谜题联合会的颁证仪式,成为世界谜题联合会的39个成员之一。(引用自“中文维基百科”: http://zh.wikipedia.org/wiki/数独)
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 194302位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
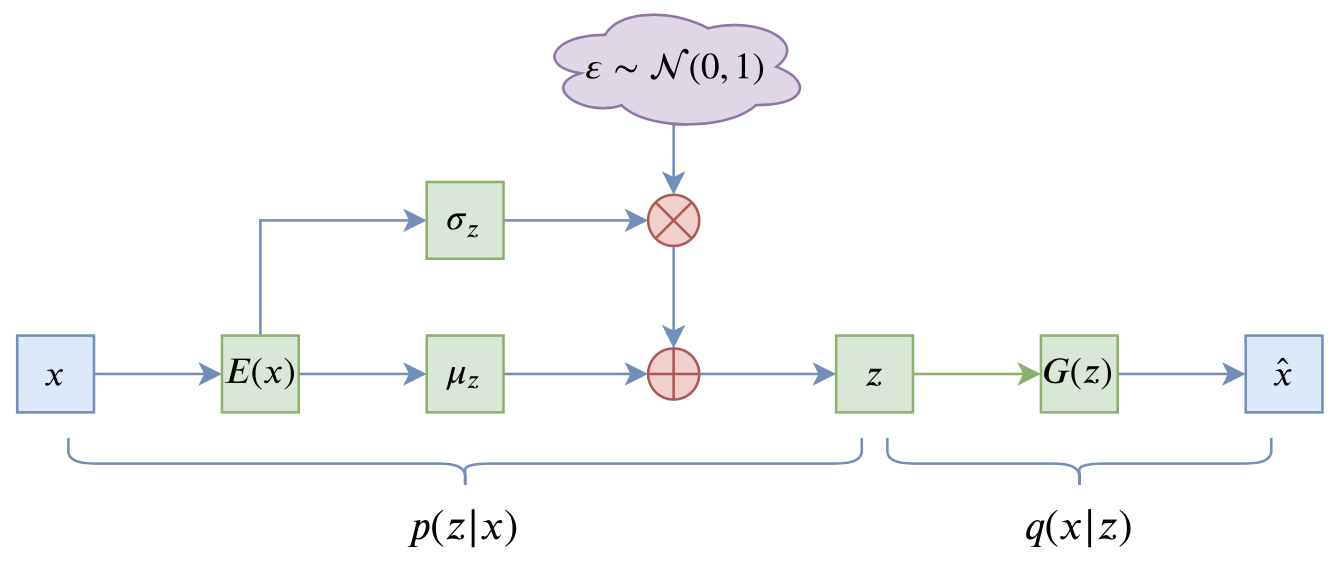
VAE训练流程图示
6
Mar
Openwrt自动扫描WiFi并连接中继
By 苏剑林 | 2016-03-06 | 54512位读者 | 引用
17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 96218位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。
15
Jan
SVD分解(一):自编码器与人工智能
By 苏剑林 | 2017-01-15 | 48487位读者 | 引用咋看上去,SVD分解是比较传统的数据挖掘手段,自编码器是深度学习中一个比较“先进”的概念,应该没啥交集才对。而本文则要说,如果不考虑激活函数,那么两者将是等价的。进一步的思考就可以发现,不管是SVD还是自编码器,我们降维,并不是纯粹地为了减少储存量或者减少计算量,而是“智能”的初步体现。
等价性
假设有一个$m$行$n$列的庞大矩阵$M_{m\times n}$,这可能使得计算甚至存储上都成问题,于是考虑一个分解,希望找到矩阵$A_{m\times k}$和$B_{k\times n}$,使得
$$M_{m\times n}=A_{m\times k}\times B_{k\times n}$$
这里的乘法是矩阵乘法。如图

SVD
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 428130位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。

最近评论