






9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 38567位读者 | 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
11
Nov
JoSE:球面上的词向量和句向量
By 苏剑林 | 2019-11-11 | 96194位读者 | 引用这篇文章介绍一个发表在NeurIPS 2019的做词向量和句向量的模型JoSE(Joint Spherical Embedding),论文名字是《Spherical Text Embedding》。JoSE模型思想上和方法上传承自Doc2Vec,评测结果更加漂亮,但写作有点故弄玄虚之感。不过笔者决定写这篇文章,是因为觉得里边的某些分析过程有点意思,可能会对一般的优化问题都有些参考价值。
优化目标
在思想上,这篇文章基本上跟Doc2Vec是一致的:为了训练句向量,把句子用一个id表示,然后把它也当作一个词,跟句内所有的词都共现,最后训练一个Skip Gram模型,训练的方式都是基于负采样的。跟Doc2Vec不一样的是,JoSE将全体向量的模长都归一化了(也就是只考虑单位球面上的向量),然后训练目标没有用交叉熵,而是用hinge loss:
\begin{equation}\max(0, m - \cos(\boldsymbol{u}, \boldsymbol{v}) - \cos(\boldsymbol{u}, \boldsymbol{d}) + \cos(\boldsymbol{u}', \boldsymbol{v}) + \cos(\boldsymbol{u}', \boldsymbol{d})\label{eq:loss}\end{equation}
30
Jan
【分享】千万级百度知道语料
By 苏剑林 | 2018-01-30 | 105474位读者 | 引用发布
2018年01月30日
数目
共1千万条
格式
[
{
"url": "http://zhidao.baidu.com/question/565618371557484884.html",
"question": "学文员有哪些专科学校",
"tags": [
"学校",
"专科",
"院校信息"
]
},
{
"url": "http://zhidao.baidu.com/question/2079794100345438428.html",
"question": "网赌和澳门赌有区别吗",
"tags": [
"网络",
"澳门",
"赌博"
]
}
]
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 101135位读者 | 引用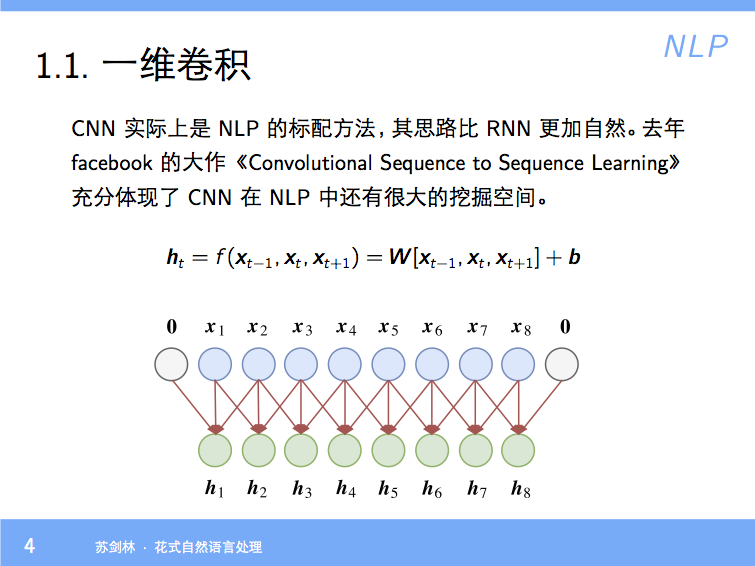
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 145059位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 77355位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。
3
Dec
词向量与Embedding究竟是怎么回事?
By 苏剑林 | 2016-12-03 | 357947位读者 | 引用词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。
这一切,还得从one hot说起...
五十步笑百步
one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分别用一个0-1编码:
$$\begin{array}{c|c}\hline\text{科} & [1, 0, 0, 0, 0, 0]\\
\text{学} & [0, 1, 0, 0, 0, 0]\\
\text{空} & [0, 0, 1, 0, 0, 0]\\
\text{间} & [0, 0, 0, 1, 0, 0]\\
\text{不} & [0, 0, 0, 0, 1, 0]\\
\text{错} & [0, 0, 0, 0, 0, 1]\\
\hline
\end{array}$$
1
Dec
基于双向GRU和语言模型的视角情感分析
By 苏剑林 | 2016-12-01 | 113113位读者 | 引用前段时间参加了一个傻逼的网络比赛——基于视角的领域情感分析,主页在这里。比赛的任务是找出一段话的实体然后判断情感,比如“我喜欢本田,我不喜欢丰田”这句话中,要标出“本田”和“丰田”,并且站在本田的角度,情感是积极的,站在丰田的角度,情感就是消极的。也就是说,等价于将实体识别和情感分析结合起来了。
吐槽
看起来很高端,哪里傻逼了?比赛任务本身还不错,值得研究,然而官方却很傻逼,主要体现为:1、比赛分初赛、复赛、决赛三个阶段,初赛一个多月时间,然后筛选部分进入复赛,复赛就简单换了一点数据,题目、数据的领域都没有变化,复赛也是一个月的时间,这傻逼复赛究竟有什么意义?2、大家可以看看选手们在群里讨论什么:

最近评论