






31
Mar
中位数(Median)简介
By 苏剑林 | 2026-03-31 | 3817位读者 | 引用最近重新学习了一下中位数的概念,趁新鲜记录一下要点。
做异常值剔除或者裁剪时,我们经常需要一个“基准”,比如对于一堆非负数据,我们可能认为大于基准的50倍就是异常值。那这个基准如何选取呢?一个常用的指标是平均值,然而平均值容易被异常值“带偏”,因此以它为基准可能会偏向异常值,从而漏掉一些结果,这时我们可以考虑选取中位数为基准。
基本性质
对于一维数据点$x_1,x_2,\cdots,x_n$,它们的平均值(Mean)定义为
\begin{equation}\newcommand{mean}{\mathop{\text{mean}}}\mean(x_1,x_2,\cdots,x_n) = \frac{1}{n}\sum_{i=1}^n x_i\end{equation}
由于全体数据都直接参与平均计算,所以一旦有几个点特别大,那么平均值也会随之变大,从而干扰异常值的判断。
6
Nov
n个正态随机数的最大值的渐近估计
By 苏剑林 | 2025-11-06 | 21788位读者 | 引用设$z_1,z_2,\cdots,z_n$是$n$个从标准正态分布中独立重复采样出来的随机数,由此我们可以构造出很多衍生随机变量,比如$z_1+z_2+\cdots+z_n$,它依旧服从正态分布,又比如$z_1^2+z_2^2+\cdots+z_n^2$,它服从卡方分布。这篇文章我们来关心它的最大值$z_{\max} = \max\{z_1,z_2,\cdots,z_n\}$的分布信息,尤其是它的数学期望$\mathbb{E}[z_{\max}]$。
先看结论
关于$\mathbb{E}[z_{\max}]$的基本估计结果是:
设$z_1,z_2,\cdots,z_n\sim\mathcal{N}(0,1)$,$z_{\max} = \max\{z_1,z_2,\cdots,z_n\}$,那么 \begin{equation}\mathbb{E}[z_{\max}]\sim \sqrt{2\log n}\label{eq:E-z-max}\end{equation}
30
Apr
一道概率不等式:盯着它到显然成立为止!
By 苏剑林 | 2025-04-30 | 27758位读者 | 引用前两天,QQ群里有群友抛出了一道不等式求证:
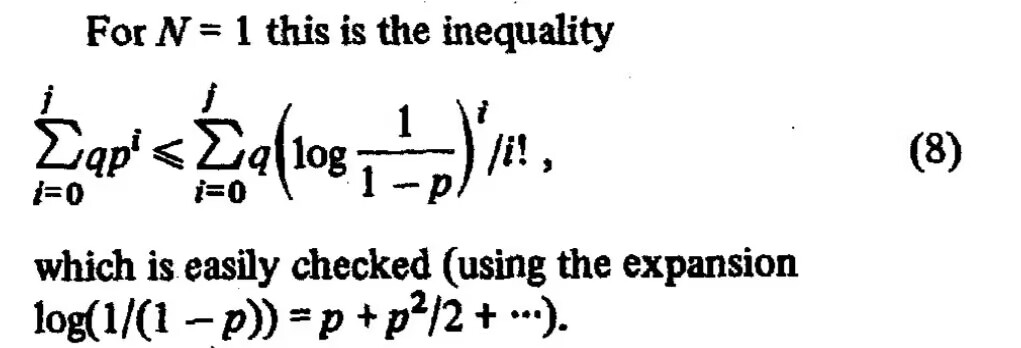
一道概率相关的不等式,出自《There is no fast single hashing algorithm》
简短的题目,加上“easily”的提示,让人觉得这似乎是显然成立的结果,然而提问者却表示尝试了很久仍未果。那么实际情况如何呢?是否真的是显然成立呢?
初步尝试
题目等价于证
\begin{equation}\sum_{i=0}^j p^i \leq \sum_{i=0}^j \left(\log\frac{1}{1-p}\right)^i/i!,\qquad p\in[0, 1)\label{eq:q}\end{equation}
19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 76580位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 38272位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。
14
Jun
通向概率分布之路:盘点Softmax及其替代品
By 苏剑林 | 2024-06-14 | 62424位读者 | 引用不论是在基础的分类任务中,还是如今无处不在的注意力机制中,概率分布的构建都是一个关键步骤。具体来说,就是将一个$n$维的任意向量,转换为一个$n$元的离散型概率分布。众所周知,这个问题的标准答案是Softmax,它是指数归一化的形式,相对来说比较简单直观,同时也伴有很多优良性质,从而成为大部分场景下的“标配”。
尽管如此,Softmax在某些场景下也有一些不如人意之处,比如不够稀疏、无法绝对等于零等,因此很多替代品也应运而生。在这篇文章中,我们将简单总结一下Softmax的相关性质,并盘点和对比一下它的部分替代方案。
Softmax回顾
首先引入一些通用记号:$\boldsymbol{x} = (x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$是需要转为概率分布的$n$维向量,它的分量可正可负,也没有限定的上下界。$\Delta^{n-1}$定义为全体$n$元离散概率分布的集合,即
\begin{equation}\Delta^{n-1} = \left\{\boldsymbol{p}=(p_1,p_2,\cdots,p_n)\left|\, p_1,p_2,\cdots,p_n\geq 0,\sum_{i=1}^n p_i = 1\right.\right\}\end{equation}
之所以标注$n-1$而不是$n$,是因为约束$\sum\limits_{i=1}^n p_i = 1$定义了$n$维空间中的一个$n-1$维子平面,再加上$p_i\geq 0$的约束,$(p_1,p_2,\cdots,p_n)$的集合就只是该平面的一个子集,即实际维度只有$n-1$。
7
Mar
用傅里叶级数拟合一维概率密度函数
By 苏剑林 | 2024-03-07 | 60613位读者 | 引用在《“闭门造车”之多模态思路浅谈(一):无损输入》中我们曾提到,图像生成的本质困难是没有一个连续型概率密度的万能拟合器。当然,也不能说完全没有,比如高斯混合模型(GMM)理论上就是可以拟合任意概率密度,就连GAN本质上也可以理解为混合了无限个高斯模型的GMM。然而,GMM尽管理论上的能力是足够的,但它的最大似然估计会很困难,尤其是通常不适用基于梯度的优化器,这限制了它的使用场景。
近日,Google的一篇新论文《Fourier Basis Density Model》针对一维情形,提出了一个新的解决方案——用傅里叶级数来拟合。论文的分析过程颇为有趣,构造形式也很是巧妙,值得学习一番。
问题简述
可能有读者质疑:只研究一维情形有什么价值?确实,如果只考虑图像生成场景,那可能真的价值有限,但一维概率密度估计本身有它的应用价值,如数据的有损压缩,所以它依然是一个值得研究的主题。再者,即便我们需要研究多维的概率密度,也可以通过自回归的方式转化为多个一维的条件概率密度来估计。最后,这个分析和构造过程本身就很值得回味,所以哪怕是仅仅作为一道数学分析题来练习也是相当有益的。
16
Oct
随机分词再探:从Viterbi Sampling到完美采样算法
By 苏剑林 | 2023-10-16 | 42649位读者 | 引用在文章《随机分词浅探:从Viterbi Decoding到Viterbi Sampling》中,笔者提出了一种名为“Viterbi Sampling”的随机分词算法,它只是在求最优解的Viterbi Decoding基础上进行小修改,保留了Viterbi算法的简单快速的特点,相比于已有的Subword Regularization明显更加高效。不过,知乎上的读者 @鶴舞 指出,当前的采样算法可能会在多次二选一“稀释”了部分方案的出现概率,直接后果是原本分数最高的切分并不是以最高概率出现。
经过仔细思考后,笔者发现相应的问题确实存在,当时为了尽快得到一种新的采样算法,在细节上的思考和处理确实比较粗糙。为此,本文将进一步完善Viterbi Sampling算法,并证明完善后的算法在效果上可以跟Subword Regularization等价的。
问题分析
首先,我们来看一下评论原话:

最近评论