






24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 1743位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
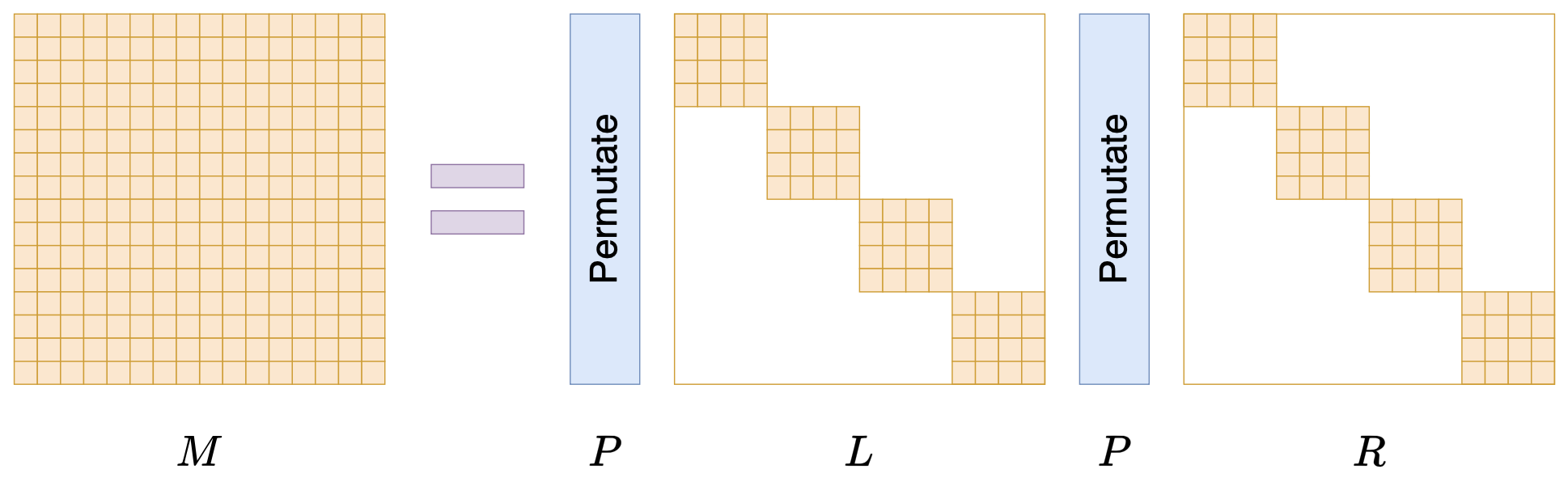
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 36782位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
5
May
如何度量数据的稀疏程度?
By 苏剑林 | 2023-05-05 | 23546位读者 | 引用在机器学习中,我们经常会谈到稀疏性,比如我们经常说注意力矩阵通常是很稀疏的。然而,不知道大家发现没有,我们似乎从没有给出过度量稀疏程度的标准方法。也就是说,以往我们关于稀疏性的讨论,仅仅是直观层面的感觉,并没有过定量分析。那么问题来了,稀疏性的度量有标准方法了吗?
经过搜索,笔者发现确实是有一些可用的指标,比如$l_1/l_2$、熵等,但由于关注视角的不同,在稀疏性度量方面并没有标准答案。本文简单记录一下笔者的结果。
基本结果
狭义上来讲,“稀疏”就是指数据中有大量的零,所以最简单的稀疏性指标就是统计零的比例。但如果仅仅是这样的话,注意力矩阵就谈不上稀疏了,因为softmax出来的结果一定是正数。所以,有必要推广稀疏的概念。一个朴素的想法是统计绝对值不超过$\epsilon$的元素比例,但这个$\epsilon$怎么确定呢?
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 200714位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 113711位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}

最近评论