






28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 191068位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
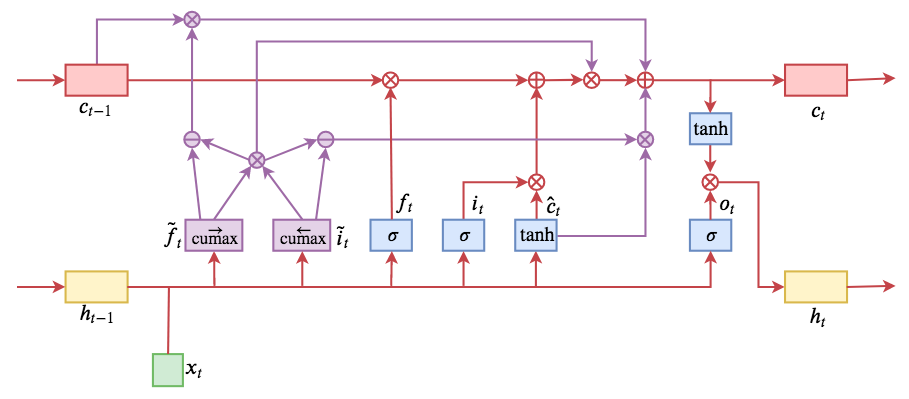
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 130864位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 82303位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 78770位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 78710位读者 | 引用
9
Mar
Seq2Seq中Exposure Bias现象的浅析与对策
By 苏剑林 | 2020-03-09 | 94902位读者 | 引用前些天笔者写了《CRF用过了,不妨再了解下更快的MEMM?》,里边提到了MEMM的局部归一化和CRF的全局归一化的优劣。同时,笔者联想到了Seq2Seq模型,因为Seq2Seq模型的典型训练方案Teacher Forcing就是一个局部归一化模型,所以它也存在着局部归一化所带来的毛病——也就是我们经常说的“Exposure Bias”。带着这个想法,笔者继续思考了一翻,将最后的思考结果记录在此文。
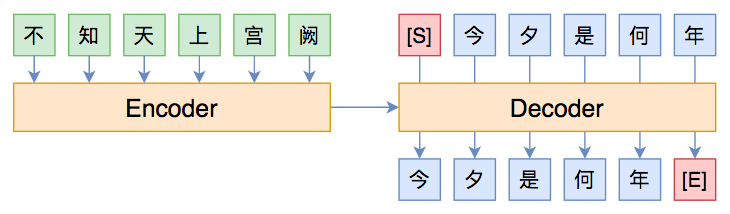
经典的Seq2Seq模型图示
本文算是一篇进阶文章,适合对Seq2Seq模型已经有一定的了解、希望进一步提升模型的理解或表现的读者。关于Seq2Seq的入门文章,可以阅读旧作《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
本文的内容大致为:
1、Exposure Bias的成因分析及例子;
2、简单可行的缓解Exposure Bias问题的策略。
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 50436位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
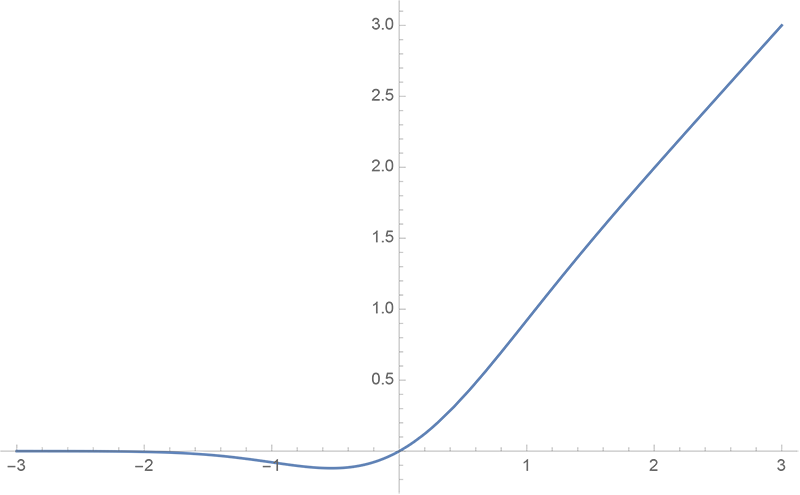
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。
7
Sep

最近评论