






15
Apr
GlobalPointer下的“KL散度”应该是怎样的?
By 苏剑林 | 2022-04-15 | 38770位读者 | 引用最近有读者提到想测试一下GlobalPointer与R-Drop结合的效果,但不知道GlobalPointer下的KL散度该怎么算。像R-Drop或者虚拟对抗训练这些正则化手段,里边都需要算概率分布的KL散度,但GlobalPointer的预测结果并非一个概率分布,因此无法直接进行计算。
经过一番尝试,笔者给出了一个可用的形式,并通过简单实验验证了它的可行性,遂在此介绍笔者的分析过程。
对称散度
KL散度是关于两个概率分布的函数,它是不对称的,即$KL(p\Vert q)$通常不等于$KL(q\Vert p)$,在实际应用中,我们通常使用对称化的KL散度:
\begin{equation}D(p,q) = KL(p\Vert q) + KL(q\Vert p)\end{equation}
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 326276位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
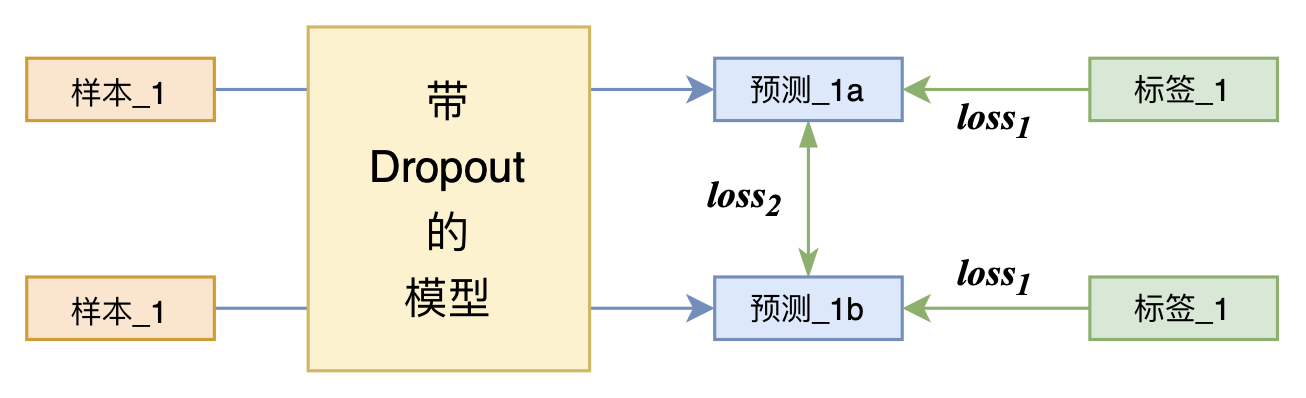
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 137369位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
9
Mar
Seq2Seq中Exposure Bias现象的浅析与对策
By 苏剑林 | 2020-03-09 | 117904位读者 | 引用前些天笔者写了《CRF用过了,不妨再了解下更快的MEMM?》,里边提到了MEMM的局部归一化和CRF的全局归一化的优劣。同时,笔者联想到了Seq2Seq模型,因为Seq2Seq模型的典型训练方案Teacher Forcing就是一个局部归一化模型,所以它也存在着局部归一化所带来的毛病——也就是我们经常说的“Exposure Bias”。带着这个想法,笔者继续思考了一翻,将最后的思考结果记录在此文。
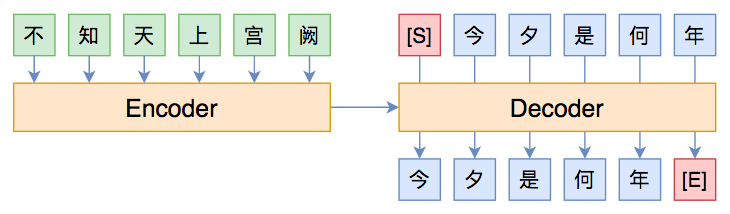
经典的Seq2Seq模型图示
本文算是一篇进阶文章,适合对Seq2Seq模型已经有一定的了解、希望进一步提升模型的理解或表现的读者。关于Seq2Seq的入门文章,可以阅读旧作《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
本文的内容大致为:
1、Exposure Bias的成因分析及例子;
2、简单可行的缓解Exposure Bias问题的策略。
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 346787位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。

最近评论