






29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 108931位读者 |本文标题看起来有点“标题党”了,不过所作改动放到bert4keras框架下,确实是一行代码的变动,至于是否有提升,这个笔者不敢打包票,不过测了几个算是比较有代表性的任务,均显示持平甚至有提升,所以标题说的也基本是事实。
那究竟是什么改动呢?其实一句话也能讲清楚:
在下游任务中,放弃albert的权重共享的约束,也就是把albert当bert用。
具体思路细节,请接着看下去~
albert是什么 #
这个改动是专门给albert设计的,所以要理解这个改动,需要先知道albert是什么。在此还是花点篇幅对albert进行个简单的科普。这里假设读者已经对bert有了一定的了解,所以主要是比较albert跟bert的异同。
低秩分解 #
首先是Embedding层,以中文版bert base为例,token总数大约是20000,而Embedding层维度是768,所以Embedding层的总参数量大约是1500万,大概占了总参数量的1/6。albert第一个开刀的部分就是Embedding层,它把Embedding层弄成128维了,然后再通过$128\times 768$的矩阵变换矩阵变回768维,这样Embedding层参数量就只有原来的1/6了,这就是所谓的低秩分解。
参数共享 #
其次是transformer部分。在以bert为代表的transformer架构模型中,其核心是由self attention、layer norm、全连接(核大小为1的一维卷积)等组成的模块,这里称之为“transformer block”,而bert模型就是多个transformer block的堆叠。如下面左图实际上是bert base的示意图,它堆叠了12个transformer block:
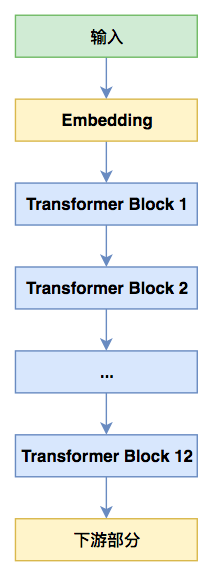
bert base极简示意图
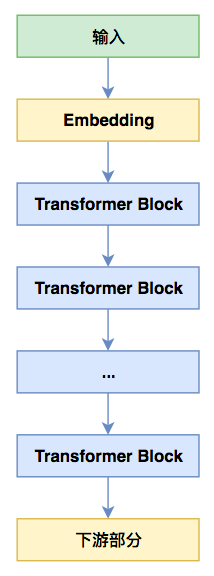
albert base极简示意图
注意到,在bert的设计里边,每个transformer block的输入和输出形状是一样的,这意味着当前block的输出作为当前block的输入也是合理的。这也告诉我们,同一个block其实是可以重复使用来迭代的,而不至于每一层都使用一个新的block。albert里边使用了一种最简单直接的方案:所有层都公用同一个transformer block(如上面右图所示)!这样一来,在albert base中,transformer block这部分参数量直接降低为原来bert base的1/12了。
简单评述 #
除了以上两点之外,albert与bert的一个显著不同之处是在预训练阶段将NSP(Next Sentence Prediction)任务改为了SOP(Sentence-Order Prediction)任务,但是这并不属于模型架构上的,所以并不是本文要关心的,读者自行找相关资料了解即可。
总的来说,albert是一个为了降低参数量而设计的模型,并且希望这个参数量的降低能带来一定的正则化作用,从而降低过拟合风险,提升最终表现。但最后的结果是否如作者所愿呢?从“战绩”来看,albert问世之时用它最大版本的模型刷新了glue榜单,所以应该算是达到了作者的期望。但是,albert并非总是那么理想,albert也不是我们想象中的小模型。
对于一个模型来说,我们比较关心的是速度和效果两个指标。从上面两个bert和albert的图其实就可以看到,在预测阶段(前向传播),其实albert跟bert没啥差别,所以同一规格(比如大家都是base版本)下的albert和bert的预测速度是一样的,甚至更严格地说,albert还更慢些,因为albert的Embedding部分还多了一个矩阵运算。换句话说,albert不能带来预测速度的提升!
那同一规格的albert和bert,哪个效果好呢?其实albert论文已经给出了答案:在large以内的版本,albert效果比bert更差,只有在xlarge、xxlarge的版本时albert效果才开始优于bert。但是roberta方式的预训练部分弥补了bert的缺点,所以真正可以说稳定优于bert/roberta的albert版本就只有xxlarge。然而albert xxlarge是一个很庞大的模型,以至于我们很难把它跑起来。
所以,基本上可以说:(在大多数人能搞起的前提下)在同样的预测速度下,albert效果更差;在同样的效果下,albert更慢。
那训练阶段呢?前面还没有提到的一点是,albert的参数共享设计其实有很强的正则化作用,所以albert去掉的dropout。参数共享和去掉dropout这两点确实可以省一些显存,并且提高训练速度,但是笔者的评测是幅度只有10%~20%左右。也就是说,就算albert参数降低到bert的1/10甚至更多,并不意味着它的显存占用量能降低到1/10,也不意味着训练速度能提高10倍,相反,它只有小幅度的提升。
抛开共享约束 #
从前面的讨论中,我们能理解到几个事实:
1、只看预测的话,albert跟bert基本一致;
2、albert的参数共享对效果的作用基本是负面的。
既然这样,那么我们可以尝试一个新鲜的玩法:在针对下游任务进行finetune时,我们把参数共享这个约束去掉如何?也就是说,finetune的时候把albert当bert用,相当于每一个transformer block的初始化权重都一样的bert。
效果评测 #
事不宜迟,测了效果再说话。这里挑了四个任务来测。为了保证可复现性,下面同一个实验都跑了三次,表格里显示的是三次结果的平均值。其中unshared版本就是指去掉参数共享后的模型。而训练速度那一列,指的是每个epoch所用的训练时间,这是在单卡TITAN RTX上跑的时间,仅供相对比较参考。
实验用bert4keras进行,对unshared版本,只需要在build_transformer_model时加载albert权重,并且设置model='albert_unshared',这就是标题所说的“一行代码”。
首先是比较简单的文本情感分类任务。
$$\begin{array}{c|c|c|c|c}
\hline
\text{模型} & \text{验证集(valid)} & \text{训练速度} & \text{第一个epoch结束时的指标值} & \text{测试集(test)} \\
\hline
\text{small_unshared} & 94.66\% & 38s & 90.75\% & 94.35\% \\
\text{small} & 94.57\% & 33s & 91.02\% & 94.52\% \\
\hline
\text{tiny_unshared} & 94.02\% & 23s & 88.09\% & 94.13\% \\
\text{tiny} & 94.14\% & 20s & 90.18\% & 93.78\% \\
\hline
\end{array}$$
去掉参数共享后,训练时间略有增加,这是预料之中的,至于模型表现各有优劣。考虑到这个任务准确率本身比较高了,可能显示不出模型间的差距,所以下面继续测试复杂一点的模型。
这次我们试试CLUE的IFLYTEK'长文本分类,结果如下:
$$\begin{array}{c|c|c|c}
\hline
\text{模型} & \text{验证集(dev)} & \text{训练速度} & \text{第一个epoch结束时的指标值} \\
\hline
\text{small_unshared} & 57.73\% & 27s & 49.35\% \\
\text{small} & 57.14\% & 24s & 48.21\% \\
\hline
\text{tiny_unshared} & 55.91\% & 16s & 47.89\% \\
\text{tiny} & 56.42\% & 14s & 43.84\% \\
\hline
\end{array}$$
这时候unshared版本的优势开始显示出来了,主要体现在整体上收敛更快(看第一个epoch的指标值),small版本最优效果明显更优,tiny版本最优效果略差,但通过精细调整学习率后,tiny_unshared版本的最优效果其实是可以优于tiny版的(但这样一来变量太多了,表格显示的是严格的控制变量的结果)。
然后试试比较综合的任务:信息抽取。结果如下:
$$\begin{array}{c|c|c|c}
\hline
\text{模型} & \text{验证集(dev)} & \text{训练速度} & \text{第一个epoch结束时的指标值} \\
\hline
\text{small_unshared} & 77.89\% & 375s & 61.11\% \\
\text{small} & 77.69\% & 335s & 46.58\% \\
\hline
\text{tiny_unshared} & 76.44\% & 235s & 49.74\% \\
\text{tiny} & 75.94\% & 215s & 31.66\% \\
\hline
\end{array}$$
可以看到,在比较综合性的复杂任务,unshared版本的模型已经稳定超过同规模的原模型。
最后一个是用seq2seq做阅读理解式问答,结果如下:
$$\begin{array}{c|c|c|c}
\hline
\text{模型} & \text{验证集(dev)} & \text{训练速度} & \text{第一个epoch结束时的指标值} \\
\hline
\text{small_unshared} & 68.80\% & 607s & 57.02\% \\
\text{small} & 66.66\% & 582s & 50.93\% \\
\hline
\text{tiny_unshared} & 66.15\% & 455s & 48.64\% \\
\text{tiny} & 63.41\% & 443s & 37.47\% \\
\hline
\end{array}$$
这个任务主要目的是测试模型的文本生成能力。可以看到在此任务上,unshared版本的模型已经明显超过原版模型,甚至tiny版的unshared模型已经逼近原版small模型。
分析思考 #
上面的模型都是albert tiny/small的实验,其实base版也实验过,结论跟tiny和small版的基本一致,但是base版本(自然也包括large以及xlarge版本)实验时间过长,所以没有做完完整的实验(也没有重复三次),因此就不贴上了。但总的来说,可以感觉到tiny/small版本的结果基本上有代表性了。
上述实验标明,去掉参数共享后的albert,在下游任务中的表现基本能持平甚至超过原版albert,这显示了对于很多NLP任务来说,参数共享可能并不是一个很好的约束。读者可能纠结于“为什么到了xlarge甚至xxlarge规模的模型时,参数共享的albert又开始超过了不参数共享的bert了呢?”。这里笔者尝试给出一个解释。
从理论上来说,bert防止过拟合的手段有dropout和权重衰减,其中权重衰减在albert也用了,但dropout没有出现在albert中,所以可以往dropout角度思考。很多实验都表明,dropout确实是一种降低过拟合风险的有效策略,但已有的实验模型基本都远远比不上bert xlarge、bert xxlarge那么大,所以dropout在超大模型下的有效性依然值得商榷。事实上,dropout存在训练和推断的不一致问题,也就是“严格来讲训练模型和预测模型并不是同一个模型”,个人感觉模型变大变深时,这种不一致性会进一步放大,所以个人认为dropout对于超大模型并不是一种有效的防止过拟合的方法。那bert里边直接去掉dropout呢?也不大行,因为去掉dropout就没有什么手段来抑制bert的过拟合了,参数量那么大,过拟合肯定严重。而albert去掉了dropout,通过参数共享来引入隐式的正则,使得模型变大变深不至于退化,甚至会表现更好。
反过来说,albert的参数共享性能要好,条件是要足够大、足够深,所以如果我们用的是base版本、small版本甚至是tiny版本时,反而不应该用参数共享,因为对于小模型来说参数共享反而是对模型表达能力的不必要的限制,所以这时候去掉参数共享表现反而更好些。
文章的小结 #
本文实验了一个新鲜的玩法:finetune阶段把albert的参数共享去掉,把albert当bert用,在几个任务上发现这样做有着持平甚至超过原始albert的表现,最后给出了对albert以及此现象的个人理解。
转载到请包括本文地址:https://spaces.ac.cn/archives/7187
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jan. 29, 2020). 《抛开约束,增强模型:一行代码提升albert表现 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7187
@online{kexuefm-7187,
title={抛开约束,增强模型:一行代码提升albert表现},
author={苏剑林},
year={2020},
month={Jan},
url={\url{https://spaces.ac.cn/archives/7187}},
}

January 30th, 2020
博主您好,之前看到您关于CapsNet网络的分享,请问您Github的网址是多少呢?
https://github.com/bojone
感谢!
February 3rd, 2020
您好,我在代码中似乎并没有找到相关unshared的代码呀?
只需要在build_bert_model时加载albert权重,并且设置model='albert_unshared'
我按你的方法设置了,但是加载albert权重时报错:ValueError: Dimension 1 in both shapes must be equal, but are 768 and 128. Shapes are [768,768] and [768,128]. for 'Assign_23' (op: 'Assign') with input shapes: [768,768], [768,128].
你可以先尝试一下把
https://github.com/bojone/bert4keras/blob/master/examples/task_sentiment_albert.py
里边的model='albert'改为model='albert_unshared',看看有没有报错(注意bert4keras要最新版)。如果有,请贴错误信息;如果没有,那就请认真仔细地阅读README.md,搞清楚自己使用错误在哪。
February 12th, 2020
bert防止过拟合的手段有dropout和权重衰减,这里的权重衰减指的是学习率吗,还是其它的?
权重衰减指的是用了AdamW优化器,里边有个weight_decay_rate=0.01,理论上这有助于防止过拟合。
February 23rd, 2020
请问下当我用了unshared之后,计算资源的消耗猛增,这是正常的吗?
增加是有的,但是按照我的理解,应该算不上“猛增”吧?你具体是从什么增加到什么?
我在跑xxlarge 其他条件相同的情况下,unshared 一个epoch要200多个小时,而普通的只用3,4个小时。我用的是cpu来进行运算的。
如果是用base版本的话,unshare要2分钟,普通的要1分钟。
CPU...没体验过。GPU的情况下,base版慢10~20%左右。
July 2nd, 2020
请问大佬TensorFlow版本如何设置unshared去除权重共享呢,没找到相关代码呀…
没有简单的方法...这本来就不在albert的涉及范围内,你要搞的话只能改它的源码了。
October 30th, 2020
[...]至于效果,其实ALBERT的原论文已经说得很清楚,如下表所示。参数共享会限制模型的表达能力,因此ALBERT的xlarge版才能持平BERT的large版,而要稳定超过它则需要xxlarge版,换句话说,只要版本规格小于xlarge,那幺同一规格的ALBERT效果都是不如BERT的。中文任务上的评测结果也是类似的,可以参考 这里 和 这里 。而且笔者之前还做过更极端的实验:加载ALBERT的权重,[...]
November 13th, 2020
但如果是dropout 的問題,那bert 把dropout 拿掉結果不就更好了嗎?但是bert 的作者卻沒有這麼做,是不是表示dropout 確實有其必要?
我倒有不同的看法。我認為不是dropout的問題,而是albert 預訓練的時候參數共享,相當於每一層都學到一樣多東西。相比bert的第1層到第12層從random 開始訓練,到最後第12層會學到跟第1層一樣多東西嗎?我認為未必,也許到第12層已經學不到什麼了。而你的做法,把預訓練過的albert 拿掉參數共享,其實就相當於從第1層到第12層都學到一樣多東西的bert,而且還不用dropout(因為預訓練時事實上只有一層的權重,其他層都共享,如果還dropout,反而限制了表達能力)。而原始的bert 如不加dropout,很可能就會遇到第12層已經學不到甚麼東西的狀況,因為光是前面幾層複雜度就高到足以overfitting了。
不過你這邊並沒有把albert unshared 跟bert 做比較對吧?我認為你那個所謂的提升,應該就是回復到bert本來的水準而已。如果是這樣,那麼這個做法其實就只有在預訓練時比較快,預測時拿掉參數共享可以得到跟bert 接近的水準,如此而已。
你误解我意思了。我说“dropout对于超大模型并不是一种有效的防止过拟合的方法”,但不是说“没有dropout更好”,而是“dropout不够好,不够有力”,导致bert+dropout在超大模型下不够dropout好。
我修改一下描述吧~谢谢指出。
February 24th, 2021
ALBERT 不能简单地说是一个 transformer block 过 12 次吧,只是 attention 做了参数共享, FFN 并没有呀
ALBERT就是“一个 transformer block 过 12 次”,整个block都参数共享的。请仔细看原文或者阅读源码。
April 20th, 2021
我记的ALBERT的dropout问题这个在ICLR上审稿的时候,作者说:我们首次发现了Dropout损害性能。reviews:***,那是因为你这个用的是参数共享,而且这个别人早发现过。
哈哈哈,学习了