






18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 46065位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 312323位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
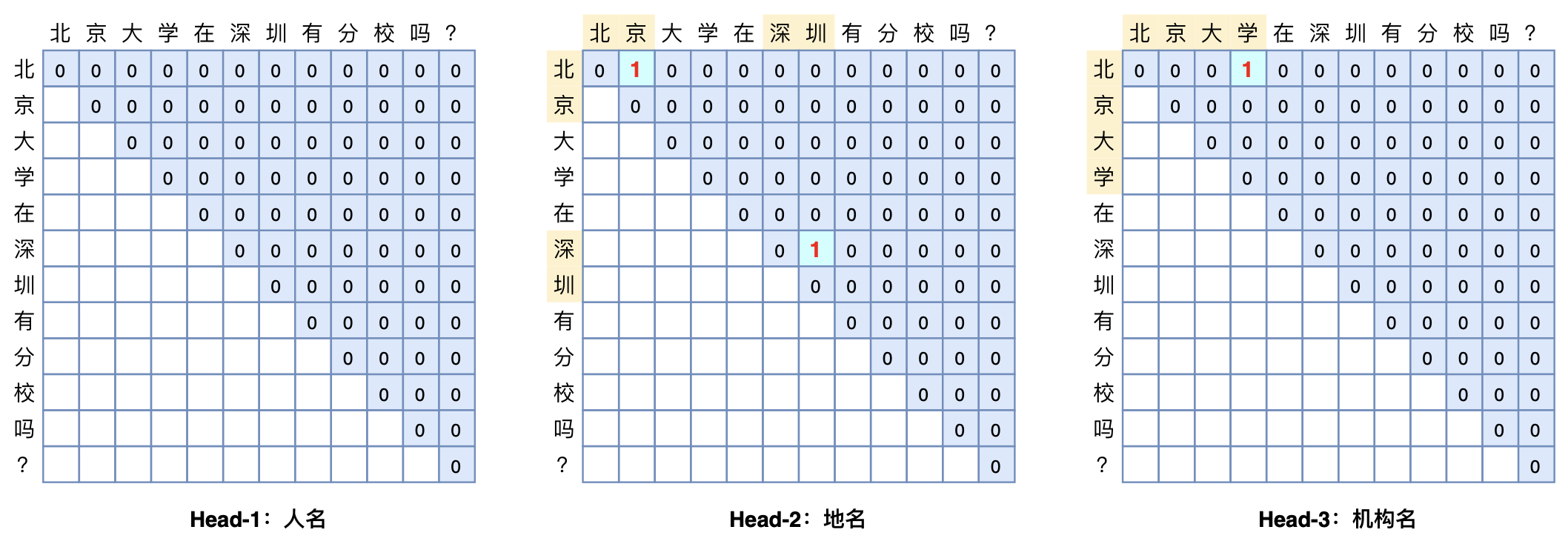
GlobalPointer多头识别嵌套实体示意图
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 77050位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 409660位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 108861位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
3
Apr
Bias项的神奇作用:RoPE + Bias = 更好的长度外推性
By 苏剑林 | 2023-04-03 | 42650位读者 | 引用万万没想到,Bias项能跟Transformer的长度外推性联系在一起!
长度外推性是我们希望Transformer具有的一个理想性质,笔者曾在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》系统地介绍过这一问题。至于Bias项(偏置项),目前的主流观点是当模型足够大时,Bias项不会有什么特别的作用,所以很多模型选择去掉Bias项,其中代表是Google的T5和PaLM,我们后面做的RoFormerV2和GAU-α也沿用了这个做法。
那么,这两个看上去“风牛马不相及”的东西,究竟是怎么联系起来的呢?Bias项真的可以增强Transformer的长度外推性?且听笔者慢慢道来。
12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 45616位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
1
Sep
Decoder-only的LLM为什么需要位置编码?
By 苏剑林 | 2024-09-01 | 31851位读者 | 引用众所周知,目前主流的LLM,都是基于Causal Attention的Decoder-only模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称NoPE)就可以取得非平凡的结果。然而,事实是主流的Decoder-only LLM都还是加上了额外的位置编码,比如RoPE、ALIBI等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的LLM反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1、位置编码对于Attention的作用是什么?
2、NoPE的Causal Attention是怎么实现位置编码的?
3、NoPE实现的位置编码有什么不足?

最近评论