






19
Jul
用开源的人工标注数据来增强RoFormer-Sim
By 苏剑林 | 2021-07-19 | 208033位读者 |大家知道,从SimBERT到SimBERTv2(RoFormer-Sim),我们算是为中文文本相似度任务建立了一个还算不错的基准模型。然而,SimBERT和RoFormer-Sim本质上都只是“弱监督”模型,跟“无监督”类似,我们不能指望纯弱监督的模型能达到完美符合人的认知效果。所以,为了进一步提升RoFormer-Sim的效果,我们尝试了使用开源的一些标注数据来辅助训练。本文就来介绍我们的探索过程。
有的读者可能想:有监督有啥好讲的?不就是直接训练么?说是这么说,但其实并没有那么“显然易得”,还是有些“雷区”的,所以本文也算是一份简单的“扫雷指南”吧。
前情回顾 #
笔者发现,自从SimBERT发布后,读者问得最多的问题大概是:
为什么“我喜欢北京”跟“我不喜欢北京”相似度这么高?它们不是意思相反吗?
尤其是RoFormer-Sim发布之后,类似的问题几乎一两周就出现一次。此外,不止笔者自己的科学空间交流群,别的NLP相关的群也时不时冒出差不多的问题,说明类似的疑惑是普遍存在的。
那么,怎么理解这件事呢?
首先,“意思相反”这个认知是不对的,从相似的角度来看,只有“相似”、“不相似”的说法,并没有“相反”的说法,原则上来看,没有两个绝对毫无关联的句子,所以理论上没有哪两个句子的相似度为0,更不用说没有明确定义的“相反”了。而恰恰相反,我们通常认为的“反义词”,从客观上来看,它们都算是比较相似的词,比如“喜欢”和“讨厌”,它们的共性多了去了:都是动词,都是描述情感倾向,用法也差不多,所以我们怎么能说这两个词“毫不相似”甚至“相反”?我们说它是反义词,是指它在某一个极小的维度下是对立关系,要注意,只是某个维度,不是全部,所以意味着我们这种认知本身是非客观的(这么多维度相似,只有一个维度不相似,我们就说它们是“反义词”,这还不是不客观?)。
同理,按照笔者的理解,从客观角度来看,“我喜欢北京”跟“我不喜欢北京”就是很相似的,所以模型给出的相似度高是很合理的,给出相似度低才是不合理的。当然,我不是说“我喜欢北京”跟“我不喜欢北京”在任何场景下都相似,它们确实是存在对立的维度,但问题是无监督、弱监督学习出来的都是比较客观的结果,而如果我们认为“我喜欢北京”跟“我不喜欢北京”不相似,那么就说明我们主观地挑出了我们要进行比较的维度,而不是客观的全部的维度。而既然是人的主观行为,我们不应该指望无监督、弱监督的方法能学出来,最好的办法就是标注数据来有监督学习。
所以,说白了就是:
模型没错,错的是人。如果人坚持自己没错,那就请通过标注数据有监督学习的方式来告诉模型它错了。
分门别类 #
通过上述讨论,我们应该就能理解标数据有监督的必要性了。不是所有问题都可以通过无监督、弱监督的方式解决,如果非要想无监督、弱监督的方案,其成本可能远远大于标几条数据。
至于相似度相关的中文人工标注数据,目前收集到的有三种类型:
1、是非类型:这种是比较常见的类型,主要格式是“(句子1, 句子2, 是否相似)”,这里收集到的ATEC、BQ、LCQMC、PAWSX都是这种类型;
2、NLI类型:NLI的全称是Natrual Language Inference(自然语言推理),样本格式是“(句子1, 句子2, 蕴涵/中立/矛盾)”,可以视为更为精细一点的相似度数据集,当前可以找到的中文NLI数据集是英文版翻译过来的,链接位于CNSD;
3、打分类型:这算是最精细的相似度语料,格式为“(句子1, 句子2, 相似程度)”,这个相似程度一般是比0/1更细颗粒度的等级,目前可以找到的中文数据集是STS-B,也是由对应的英文数据集翻译过来的。
由于量比较大的是前2种,所以为了处理上的方便,我们直接设置一个阈值,将第3种的STS-B数据转化为第1种情形,所以可利用的就两种数据格式:1、句子对的2分类;2、句子对的3分类。
出乎意料 #
文章开头写到,虽然是监督训练,但也不是那么“显然易得”,这主要是因为训练方式的选择有点出乎意料。简单起见,我们先以2分类的训练样本为例进行说明。
假设两个句子通过编码器后得到的句向量分别为$u,v$,由于在检索阶段我们通常使用它们的余弦值$\cos(u,v)=\frac{\langle u,v\rangle}{\Vert u\Vert \Vert v\Vert}$为相似度进行排序,所以很自然的想法就是基于$\cos(u,v)$设计损失函数,一些比较容易想到的有:
\begin{equation}\begin{aligned}
&t\cdot (\cos(u,v) - 1)^2 + (1 - t)\cdot \cos^2(u,v) \\
&t\cdot (\cos(u,v) - 1)^2 + (1 - t)\cdot (\cos(u,v) + 1)^2 \\
&t\cdot \max(0.9 - \cos(u,v), 0) + (1-t)\cdot \max(\cos(u,v) - 0.1, 0)
\end{aligned}\end{equation}
其中$t\in\{0,1\}$是该句子对的标签。上述几个loss的大致意思是让正样本对的$\cos(u,v)$尽量大,让负样本对的$\cos(u,v)$尽量小。
然而,在笔者的实验中,这样的训练和预测都一致训练方案,结果居然都不如出自InferSent、并且被Sentence-BERT沿用的一种看起来是训练和预测不一致的方案。具体来说,Sentence-BERT是将$u,v,|u-v|$(其中$|u-v|$是指$u-v$的每个元素都取绝对值后构成的向量)拼接起来做为特征,后面接一个全连接层做2分类(如果是NLI数据集则是3分类)。
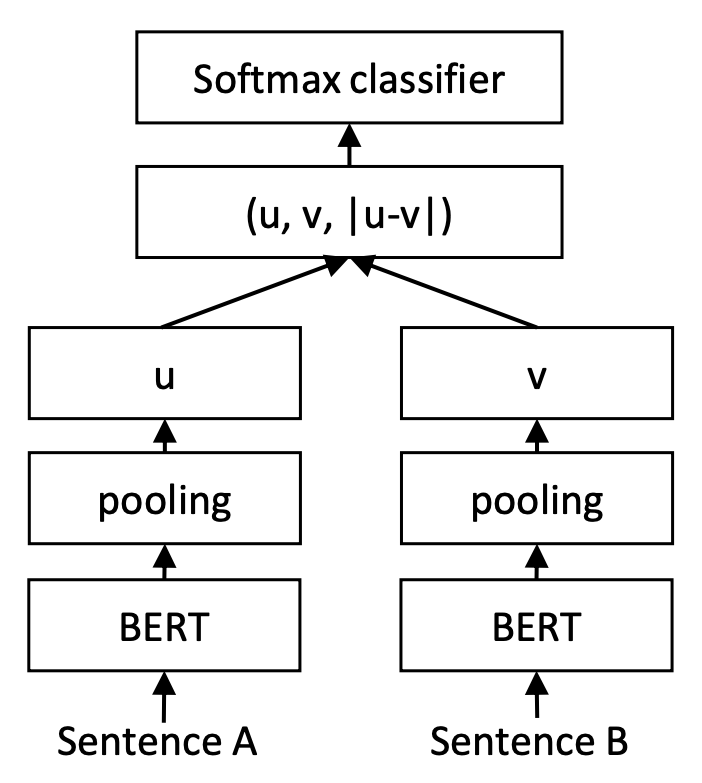
训练阶段的Sentence-BERT
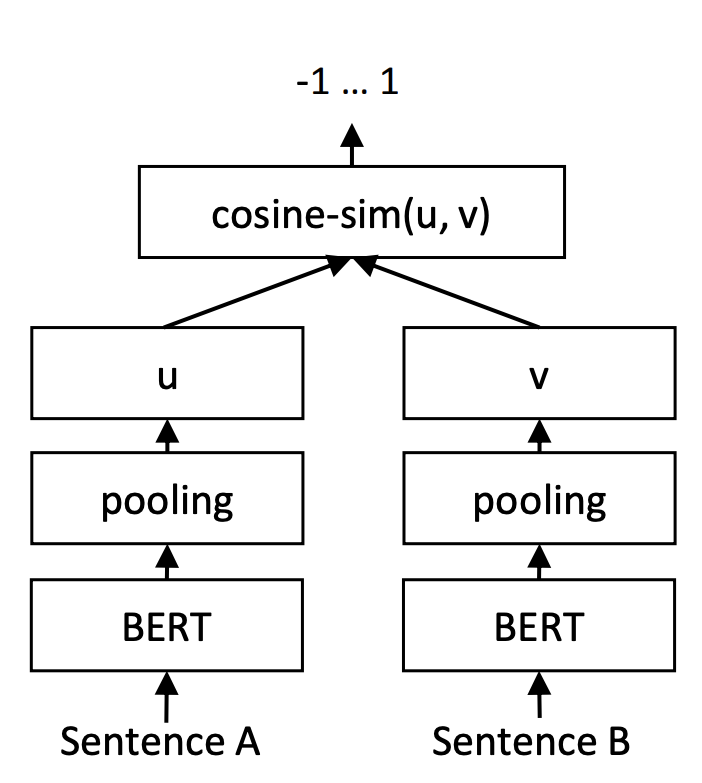
预测阶段的Sentence-BERT
当然,这只是训练方案,使用的时候,还是把句向量拿出来,用余弦相似度做检索。这样看来,InferSent、Sentence-BERT使用的这种方案,事实上属于训练和预测不一致的方案,训练的时候并没有直接涉及到$\cos(u,v)$,预测的时候却可以用$\cos(u,v)$来检索,并且表现还相当不错,所以不能不说出人意料。
闭门造车 #
对此,笔者也是百思不得其解。笔者留意到,Sentence-BERT的论文里,还比较了不同的特征拼合方式的最终效果,显示出$u,v,|u-v|$拼接的效果是最佳的,如果只保留它们的一部分,效果都将会明显下降,如下表。
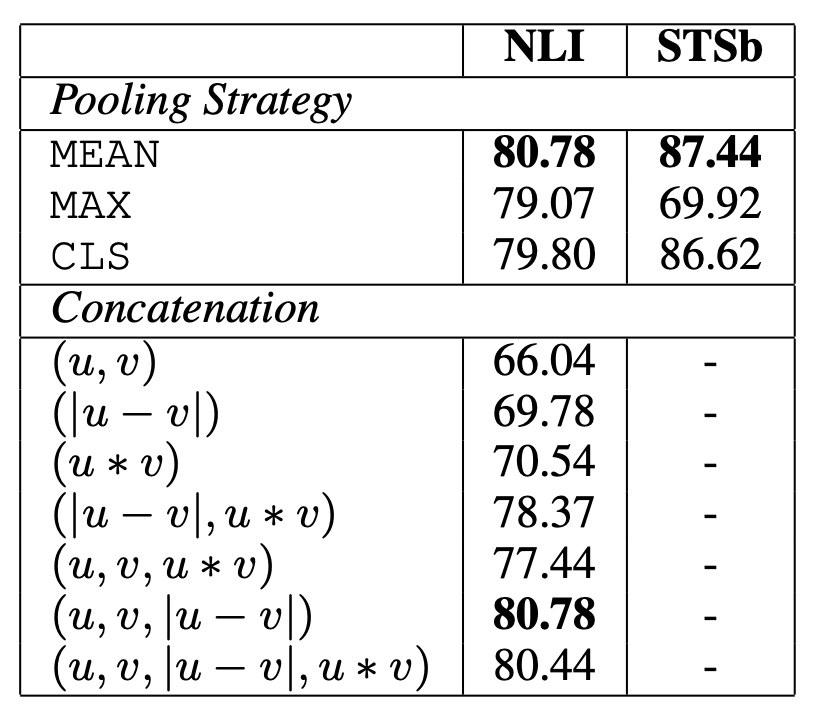
不同拼接特征的实验结果
受到这个表格的启发,笔者“闭门造车”地构思了一种解释。首先,我们知道,人是非常“挑剔”的,尤其是对于相似度任务,我们通常是认为比较严格的相似才算是相似,但是我们的训练数据通常没那么精准。一方面,标注本身可能存在噪声;另一方面,对于某些样本对,标注人员可能由于它们主题(而不是语义)相同就标记为正样本对。也就是说,标注数据通常没有我们要求的那么严格,如果直接用标注结果来学习我们的排序度量,那么反而会带来意外的偏差。
回看$u,v,|u-v|$拼接然后接个全连接的做法,它的打分函数相当于
\begin{equation}s = \langle u, w_1\rangle + \langle v, w_2\rangle + \langle |u-v|, w_3\rangle\end{equation}
这里的$w_1,w_2,w_3$是对应的参数向量。其中前两项打分为$\langle u, w_1\rangle + \langle v, w_2\rangle$,如果它很大,并不能说明$u,v$很接近,同理如果它很小,也不能说明$u,v$差得很远,它的作用更像是一个“主题分类”模型,用于识别$u,v$的主题是否一致;而对于第三项,我们知道$|u-v|=0\Leftrightarrow u=v$,所以第三项是有能力判断两个向量的近似程度的,它也许代表了真正的“语义相似”。
综合起来,我们就可以认为,$u,v,|u-v|$拼接然后接个全连接的做法,它既包含了判断两个句子主题是否一致的打分,也包含了两个句子语义相似的打分,它将“主题”和“语义”分离开来,增强了模型对数据的容错性,从而使得最终学习出来的向量更能体现出较为纯粹、精准的“语义”。
鱼与熊掌 #
通过Sentence-BERT的方案,利用开源的相似度数据集,我们可以学习到一个效果还不错的句向量模型,也即检索模型,利用它抽取特征并且用余弦相似度作为度量可以得到不错的结果。但问题是,SimBERT、RoFormer-Sim从来就不是单纯的检索模型,它希望“鱼与熊掌兼得”——既具备好的检索效果,又具备生成相似句的能力。
为此,我们通过上述方式训练好一个Sentence-BERT后,通过《SimBERTv2来了!融合检索和生成的RoFormer-Sim模型》介绍的方案,把Sentence-BERT的检索效果蒸馏到RoFormer-Sim上去,从而在保留相似句生成的基础上提高检索模型的效果。此外,同尺寸模型之间的蒸馏往往还能提升一点效果,所以我们蒸馏后的RoFormer-Sim的检索效果,其实还比直接训练得到的Sentence-BERT效果要好些。
效果演示 #
我们把用标注数据训练好的RoFormer-Sim开源如下(文件名带-ft的权重):
下面是《无监督语义相似度哪家强?我们做了个比较全面的评测》中的几个任务的测试结果(测试集):
\begin{array}{c|ccccc}
\hline
& \text{ATEC} & \text{BQ} & \text{LCQMC} & \text{PAWSX} & \text{STS-B} \\
\hline
\text{RoFormer-Sim} & 39.27 & 48.31 & 72.30 & 6.70 & 71.75 \\
\text{RoFormer-Sim-FT} & 51.71 & 73.48 & 79.56 & 62.84 & 78.28 \\
\hline
\text{RoFormer-Sim-small} & 37.08 & 46.83 & 71.27 & 5.8 & 71.29 \\
\text{RoFormer-Sim-FT-small} & 51.21 & 73.09 & 78.88 & 56.41 & 76.33 \\
\hline
\end{array}
可以看到效果有明显提升,并且small版本也有相当不俗的表现。当然,经过了监督训练,有提升是必然的,这个表格的对比意义不算大。但对于用户来说,有现成的模型可用就行了,管它是怎么来的对吧。读者可能更关心的是,这个新模型有没有解决之前检索模型的“痛点”,比如能不能拉开“我喜欢北京”跟“我不喜欢北京”的差距?下面就来看一些例子(base版,另外small版的结果相差无几):
>>> similarity(u'今天天气不错', u'今天天气很好')
0.9769838
>>> similarity(u'今天天气不错', u'今天天气不好')
0.62359834
>>> similarity(u'我喜欢北京', u'我很喜欢北京')
0.9921096
>>> similarity(u'我喜欢北京', u'我不喜欢北京')
0.5291042
>>> similarity(u'电影不错', u'电影很好')
0.96764225
>>> similarity(u'电影不错', u'电影不好')
0.6312722
>>> similarity(u'红色的苹果', u'绿色的苹果')
0.6974633
>>> similarity(u'给我推荐一款红色的车', u'给我推荐一款黑色的车')
0.7191832
>>> similarity(u'给我推荐一款红色的车', u'推荐一辆红车')
0.9866457
>>> similarity(u'给我推荐一款红色的车', u'麻烦来一辆红车')
0.9460306
从例子可以看出,经过有监督训练后,模型确实能体现出更符合普通常规认知的相似度打分,比如加了“不”字后相似度明显降低,经过对比我们发现这部分效果主要由NLI数据集带来的;还有,对“红”、“黑”等颜色也会更加敏感,尤其是最后三个例子,体现出它的检索排序结果更符合我们常规的意图识别场景。
本文小结 #
本文介绍了我们利用标注数据增强RoFormer-Sim的过程,并开源了相应的训练好的模型,使得中文相似度模型有了一个效果更好的开源可用开源的baseline。
转载到请包括本文地址:https://spaces.ac.cn/archives/8541
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jul. 19, 2021). 《用开源的人工标注数据来增强RoFormer-Sim 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8541
@online{kexuefm-8541,
title={用开源的人工标注数据来增强RoFormer-Sim},
author={苏剑林},
year={2021},
month={Jul},
url={\url{https://spaces.ac.cn/archives/8541}},
}

March 28th, 2022
试了下,语义检索效果没有simbert好,加上蒸馏也不太好。
你是说有监督的RoFormer-Sim-FT没有SimBERT效果好吗?这倒是比较意外。是什么类型的数据集呢?
按时间看,忙猜这里:https://tianchi.aliyun.com/competition/entrance/531946/information
April 22nd, 2022
可能是 长短文档的原因?
长短文档可能是什么的原因?
November 16th, 2022
如果检索过程用欧式距离的话,那我们的loss用MSE是不是就可以了,这样我们的训练目标和检索目标就一致了。
无视,想明白了,这根本不是一个问题。