






2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 200511位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
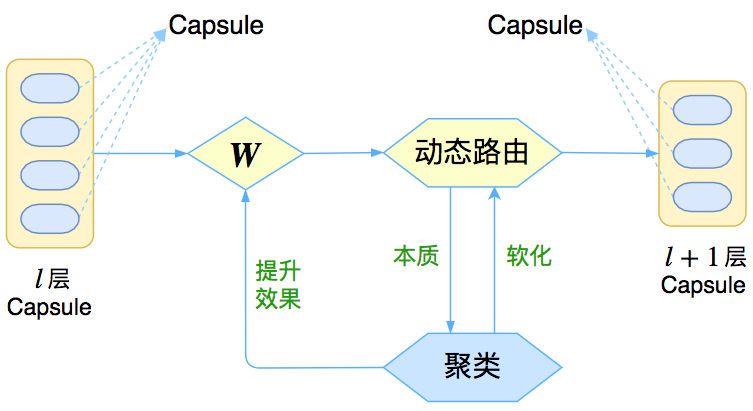
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 114074位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。

“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
24
May
重温SSM(一):线性系统和HiPPO矩阵
By 苏剑林 | 2024-05-24 | 20912位读者 | 引用前几天,笔者看了几篇介绍SSM(State Space Model)的文章,才发现原来自己从未认真了解过SSM,于是打算认真去学习一下SSM的相关内容,顺便开了这个新坑,记录一下学习所得。
SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的S4,不算太老,而SSM最新最火的变体大概是去年的Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前我们在《Google新作试图“复活”RNN:RNN能否再次辉煌?》介绍过的LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。
尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 275363位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
16
Jul
今天把Blog升级了
By 苏剑林 | 2009-07-16 | 57198位读者 | 引用
20
Jul
两千美元的汽车----世界最便宜汽车在印度上路!
By 苏剑林 | 2009-07-20 | 15152位读者 | 引用
18
Jul
日全食多路联合直播频道
By 苏剑林 | 2009-07-18 | 15765位读者 | 引用
18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 255630位读者 | 引用前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask

最近评论