






1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 259216位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
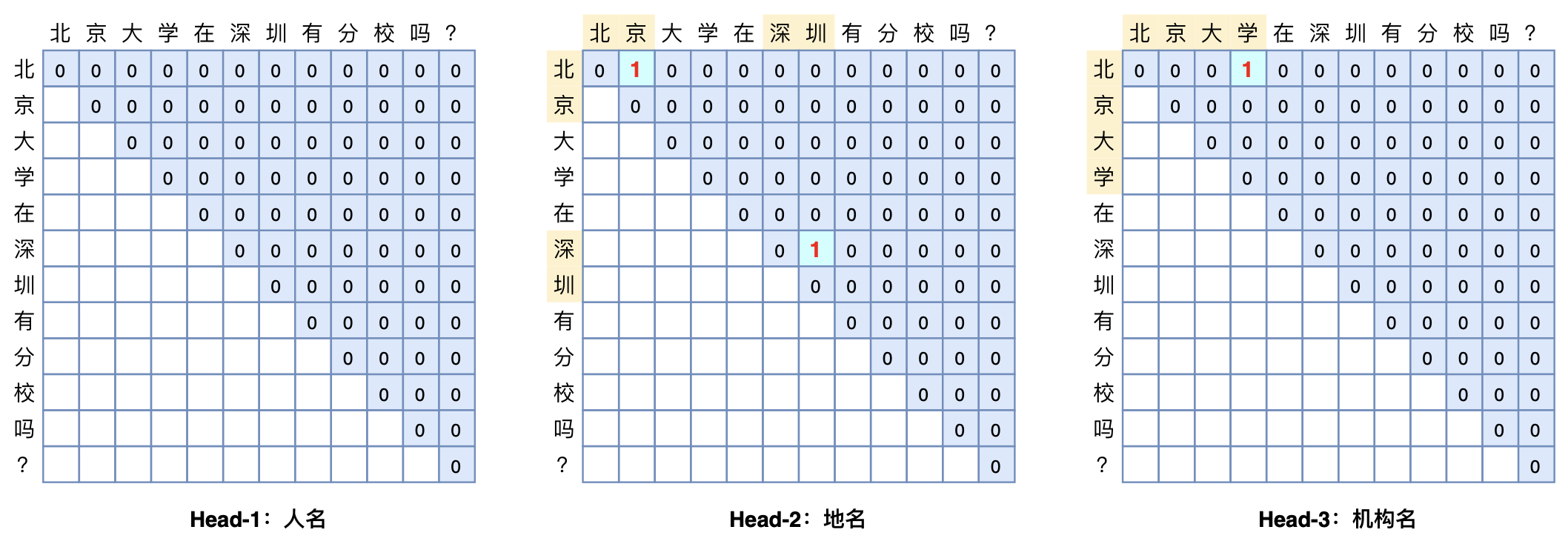
GlobalPointer多头识别嵌套实体示意图
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 56565位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 303992位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 76058位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
3
Apr
Bias项的神奇作用:RoPE + Bias = 更好的长度外推性
By 苏剑林 | 2023-04-03 | 32062位读者 | 引用【注:后来经过反复测试发现,发现此篇文章的长度外推结果可复现性比较不稳定(可能跟模型结构、超参数等紧密相关),请自行斟酌使用。】
万万没想到,Bias项能跟Transformer的长度外推性联系在一起!
长度外推性是我们希望Transformer具有的一个理想性质,笔者曾在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》系统地介绍过这一问题。至于Bias项(偏置项),目前的主流观点是当模型足够大时,Bias项不会有什么特别的作用,所以很多模型选择去掉Bias项,其中代表是Google的T5和PaLM,我们后面做的RoFormerV2和GAU-α也沿用了这个做法。
那么,这两个看上去“风牛马不相及”的东西,究竟是怎么联系起来的呢?Bias项真的可以增强Transformer的长度外推性?且听笔者慢慢道来。
12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 36777位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
17
Aug
浅谈Transformer的初始化、参数化与标准化
By 苏剑林 | 2021-08-17 | 144059位读者 | 引用前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候$\boldsymbol{Q}\boldsymbol{K}^{\top}$之后忘记除以$\sqrt{d}$了,于是重新温习了一下为什么除以$\sqrt{d}$如此重要的原因。当然,Google的T5确实是没有除以$\sqrt{d}$的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。
藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
21
Feb
“闭门造车”之多模态思路浅谈(一):无损
By 苏剑林 | 2024-02-21 | 97425位读者 | 引用这篇文章分享一下笔者关于多模态模型架构的一些闭门造车的想法,或者说一些猜测。
最近Google的Gemini 1.5和OpenAI的Sora再次点燃了不少人对多模态的热情,只言片语的技术报告也引起了大家对其背后模型架构的热烈猜测。不过,本文并非是为了凑这个热闹才发出来的,事实上其中的一些思考由来已久,最近才勉强捋顺了一下,遂想写出来跟大家交流一波,刚好碰上了两者的发布。
事先声明,“闭门造车”一词并非自谦,笔者的大模型实践本就“乏善可陈”,而多模态实践更是几乎“一片空白”,本文确实只是根据以往文本生成和图像生成的一些经验所做的“主观臆测”。
问题背景
首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗?

最近评论