






7
Mar
用傅里叶级数拟合一维概率密度函数
By 苏剑林 | 2024-03-07 | 32957位读者 | 引用在《“闭门造车”之多模态思路浅谈(一):无损输入》中我们曾提到,图像生成的本质困难是没有一个连续型概率密度的万能拟合器。当然,也不能说完全没有,比如高斯混合模型(GMM)理论上就是可以拟合任意概率密度,就连GAN本质上也可以理解为混合了无限个高斯模型的GMM。然而,GMM尽管理论上的能力是足够的,但它的最大似然估计会很困难,尤其是通常不适用基于梯度的优化器,这限制了它的使用场景。
近日,Google的一篇新论文《Fourier Basis Density Model》针对一维情形,提出了一个新的解决方案——用傅里叶级数来拟合。论文的分析过程颇为有趣,构造形式也很是巧妙,值得学习一番。
问题简述
可能有读者质疑:只研究一维情形有什么价值?确实,如果只考虑图像生成场景,那可能真的价值有限,但一维概率密度估计本身有它的应用价值,如数据的有损压缩,所以它依然是一个值得研究的主题。再者,即便我们需要研究多维的概率密度,也可以通过自回归的方式转化为多个一维的条件概率密度来估计。最后,这个分析和构造过程本身就很值得回味,所以哪怕是仅仅作为一道数学分析题来练习也是相当有益的。
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 438453位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 132524位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
7
Nov
WGAN-div:一个默默无闻的WGAN填坑者
By 苏剑林 | 2018-11-07 | 157838位读者 | 引用今天我们来谈一下Wasserstein散度,简称“W散度”。注意,这跟Wasserstein距离(Wasserstein distance,简称“W距离”,又叫Wasserstein度量、Wasserstein metric)是不同的两个东西。
本文源于论文《Wasserstein Divergence for GANs》,论文中提出了称为WGAN-div的GAN训练方案。这是一篇我很是欣赏却默默无闻的paper,我只是找文献时偶然碰到了它。不管英文还是中文界,它似乎都没有流行起来,但是我感觉它是一个相当漂亮的结果。

WGAN-div的部分样本(2w iter)
如果读者需要入门一下WGAN的相关知识,不妨请阅读拙作《互怼的艺术:从零直达WGAN-GP》。
WGAN
我们知道原始的GAN(SGAN)会有可能存在梯度消失的问题,因此WGAN横空出世了。
W距离
WGAN引入了最优传输里边的W距离来度量两个分布的距离:
\begin{equation}W_c[\tilde{p}(x), q(x)] = \inf_{\gamma\in \Pi(\tilde{p}(x), q(x))} \mathbb{E}_{(x,y)\sim \gamma}[c(x,y)] \end{equation}
这里的$\tilde{p}(x)$是真实样本的分布,$q(x)$是伪造分布,$c(x,y)$是传输成本,论文中用的是$c(x,y)=\Vert x-y\Vert$;而$\gamma\in \Pi(\tilde{p}(x), q(x))$的意思是说:$\gamma$是任意关于$x, y$的二元分布,其边缘分布则为$\tilde{p}(x)$和$q(y)$。直观来看,$\gamma$描述了一个运输方案,而$c(x,y)$则是运输成本,$W_c[\tilde{p}(x), q(x)]$就是说要找到成本最低的那个运输方案所对应的成本作为分布度量。
20
Nov
不用L约束又不会梯度消失的GAN,了解一下?
By 苏剑林 | 2018-11-20 | 172071位读者 | 引用不知道从什么时候开始,我发现我也掉到了GAN的大坑里边了,唉,争取早日能跳出来...
这篇博客介绍的是我最近提交到arxiv的一个关于GAN的新框架,里边主要介绍了一种对概率散度的新理解,并且基于这种理解推导出了一个新的GAN。整篇文章比较偏理论,对这个GAN的相关性质都做了完整的论证,自认为是一个理论完备的结果。
文章链接:https://papers.cool/arxiv/1811.07296
先摆结论:
1、论文提供了一种分析和构造概率散度的直接思路,从而简化了构建新GAN框架的过程。
2、推导出了一个称为GAN-QP的GAN框架$\eqref{eq:gan-gp-gd}$,这个GAN不需要像WGAN那样的L约束,又不会有SGAN的梯度消失问题,实验表明它至少有不逊色于、甚至优于WGAN的表现。

GAN-QP效果图
论文的实验最大做到了512x512的人脸生成(CelebA HQ),充分表明了模型的有效性(效果不算完美,但是模型特别简单)。有兴趣的朋友,欢迎继续阅读下去。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 114365位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
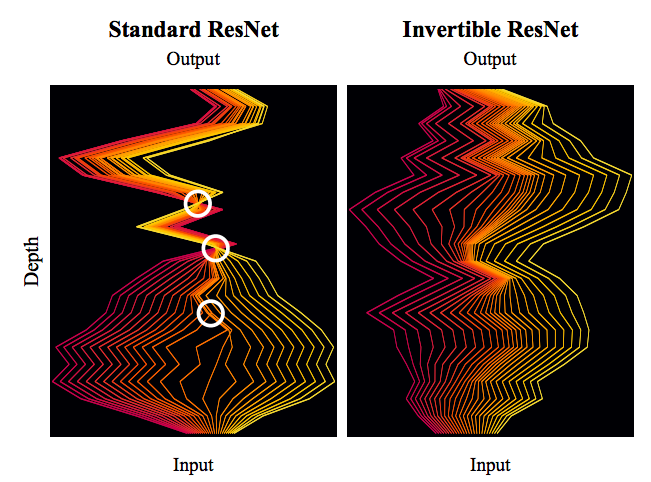
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
8
Nov
模型优化漫谈:BERT的初始标准差为什么是0.02?
By 苏剑林 | 2021-11-08 | 91248位读者 | 引用前几天在群里大家讨论到了“Transformer如何解决梯度消失”这个问题,答案有提到残差的,也有提到LN(Layer Norm)的。这些是否都是正确答案呢?事实上这是一个非常有趣而综合的问题,它其实关联到挺多模型细节,比如“BERT为什么要warmup?”、“BERT的初始化标准差为什么是0.02?”、“BERT做MLM预测之前为什么还要多加一层Dense?”,等等。本文就来集中讨论一下这些问题。
梯度消失说的是什么意思?
在文章《也来谈谈RNN的梯度消失/爆炸问题》中,我们曾讨论过RNN的梯度消失问题。事实上,一般模型的梯度消失现象也是类似,它指的是(主要是在模型的初始阶段)越靠近输入的层梯度越小,趋于零甚至等于零,而我们主要用的是基于梯度的优化器,所以梯度消失意味着我们没有很好的信号去调整优化前面的层。
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 7379位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
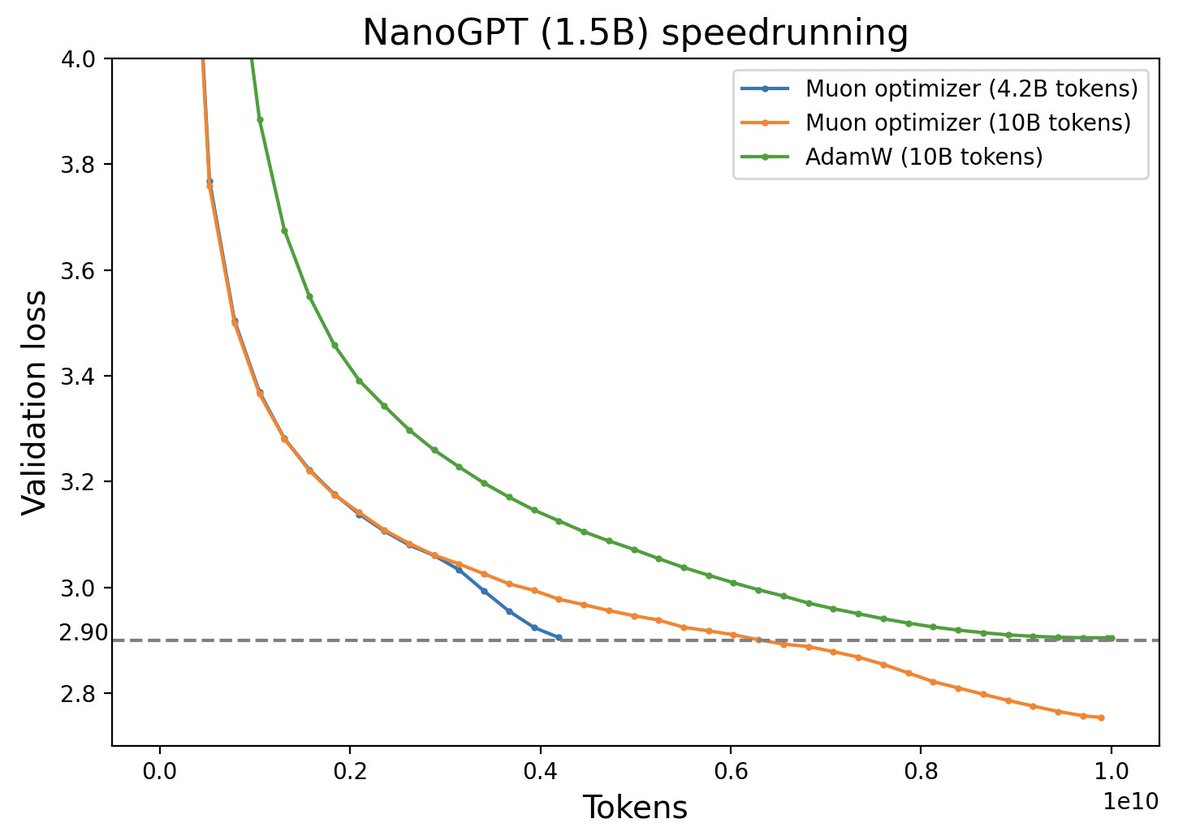
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)

最近评论