






14
Jan
基于CNN和序列标注的对联机器人
By 苏剑林 | 2019-01-14 | 43114位读者 | 引用缘起
前几天在量子位公众号上看到了《这个脑洞清奇的对联AI,大家都玩疯了》一文,觉得挺有意思,难得的是作者还整理并公开了数据集,所以决定自己尝试一下。
动手
“对对联”,我们可以看成是一个句子生成任务,可以用seq2seq完成,跟笔者之前写的《玩转Keras之seq2seq自动生成标题》一样,稍微修改一下输入即可。上面提到的文章所用的方法也是seq2seq,可见这算是标准做法了。
15
Nov
又一道川菜!媲美“开水白菜”的瓜燕穗肚
By 苏剑林 | 2018-11-15 | 34997位读者 | 引用
1
Mar
构造一个显式的、总是可逆的矩阵
By 苏剑林 | 2019-03-01 | 42174位读者 | 引用从《恒等式 det(exp(A)) = exp(Tr(A)) 赏析》一文我们得到矩阵$\exp(\boldsymbol{A})$总是可逆的,它的逆就是$\exp(-\boldsymbol{A})$。问题是$\exp(\boldsymbol{A})$只是一个理论定义,单纯这样写没有什么价值,因为它要把每个$\boldsymbol{A}^n$都算出来。
有没有什么具体的例子呢?有,本文来构造一个显式的、总是可逆的矩阵。
其实思路非常简单,假设$\boldsymbol{x},\boldsymbol{y}$是两个$k$维列向量,那么$\boldsymbol{x}\boldsymbol{y}^{\top}$就是一个$k\times k$的矩阵,我们就来考虑
\begin{equation}\begin{aligned}\exp\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)=&\sum_{n=0}^{\infty}\frac{\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)^n}{n!}\\
=&\boldsymbol{I}+\boldsymbol{x}\boldsymbol{y}^{\top}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{2}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{6}+\dots\end{aligned}\end{equation}
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 250726位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
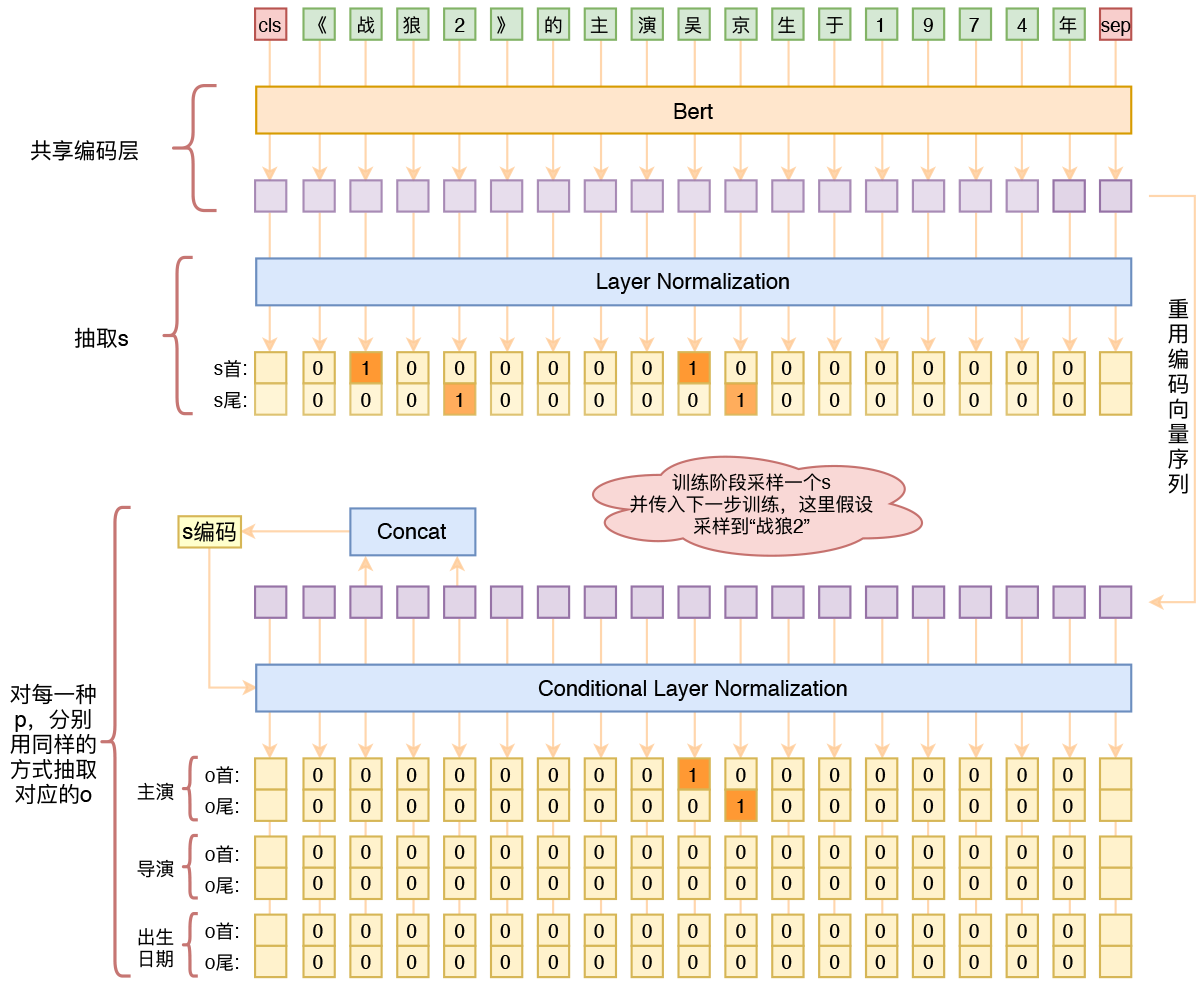
基于Bert的三元组抽取模型结构示意图
7
Jun
端午&高考乱弹:怀念的,也许只是怀念本身
By 苏剑林 | 2019-06-07 | 49884位读者 | 引用
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 313365位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 46047位读者 | 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 45815位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}

最近评论