






3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 115213位读者 |前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
赛题介绍 #
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
数据格式 #
实体链接是为基于知识图谱的问答来准备的,所以首先我们要有一个知识库(kb_data),样例如下:
{"alias": ["胜利"], "subject_id": "10001", "subject": "胜利", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "英雄联盟胜利系列皮肤是拳头公司制作的具有纪念意义限定系列皮肤之一。拳头公司制作的具有纪念意义限定系列皮肤还包括英雄联盟冠军系列皮肤、MSI季中冠军赛征服者系列以及英雄联盟全球总决赛冠军系列皮肤。每到赛季结束时,拳头公司都会制作胜利系列皮肤作为赛季奖励来认可那些在排位赛中勇猛拼搏达到黄金段位的玩家。"}, {"predicate": "制作方", "object": "Riot Games"}, {"predicate": "外文名", "object": "Victorious"}, {"predicate": "来源", "object": "英雄联盟"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "属性", "object": "虚拟"}, {"predicate": "义项描述", "object": "游戏《英雄联盟》胜利系列限定皮肤"}]}
{"alias": ["张三的歌"], "subject_id": "10002", "subject": "张三的歌", "type": ["CreativeWork"], "data": [{"predicate": "摘要", "object": "《张三的歌》这首经典老歌,词曲作者是张子石。最早收录于李寿全的专辑《8又二分之一》当中。李寿全作为台湾民谣时代的推动人,在80年代中后期有着举足轻重的地位,而这首《张三的歌》出现在当时的背景之下,带来了无可比拟的社会效应,也为那个年代留下了无法抹去的回忆。随着时间的推移,陈翔、齐秦、吴宗宪、蔡琴、青鸟飞鱼等歌手都曾翻唱过。"}, {"predicate": "歌曲原唱", "object": "李寿全"}, {"predicate": "谱曲", "object": "张子石"}, {"predicate": "歌曲时长", "object": "3分58秒"}, {"predicate": "歌曲语言", "object": "普通话"}, {"predicate": "音乐风格", "object": "民谣"}, {"predicate": "唱片公司", "object": "飞碟唱片"}, {"predicate": "翻唱", "object": "齐秦、苏芮、南方二重唱等"}, {"predicate": "填词", "object": "张子石"}, {"predicate": "发行时间", "object": "1986-08-01"}, {"predicate": "中文名称", "object": "张三的歌"}, {"predicate": "所属专辑", "object": "8又二分之一"}, {"predicate": "义项描述", "object": "李寿全演唱歌曲"}, {"predicate": "标签", "object": "单曲"}, {"predicate": "标签", "object": "音乐作品"}]}
...
...知识库包括很多实体,每个实体的信息包括一个唯一的实体id、别名以及实体相关的属性和属性值等,说白了,这其实就是一个知识图谱。知识库的特点是,“实体”不一定是指特别的专有名词,还包括常见的名词、动词、形容词等,比如“胜利”、“美丽”等。此外,同名实体很多(所以才会有实体链接这个任务),比如在这比赛提供的知识库中,名为“胜利”的实体共有15个,如下:
{"alias": ["胜利"], "subject_id": "10001", "subject": "胜利", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "英雄联盟胜利系列皮肤是拳头公司制作的具有纪念意义限定系列皮肤之一。拳头公司制作的具有纪念意义限定系列皮肤还包括英雄联盟冠军系列皮肤、MSI季中冠军赛征服者系列以及英雄联盟全球总决赛冠军系列皮肤。每到赛季结束时,拳头公司都会制作胜利系列皮肤作为赛季奖励来认可那些在排位赛中勇猛拼搏达到黄金段位的玩家。"}, {"predicate": "制作方", "object": "Riot Games"}, {"predicate": "外文名", "object": "Victorious"}, {"predicate": "来源", "object": "英雄联盟"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "属性", "object": "虚拟"}, {"predicate": "义项描述", "object": "游戏《英雄联盟》胜利系列限定皮肤"}]}
{"alias": ["胜利"], "subject_id": "19044", "type": ["Vocabulary"], "data": [{"predicate": "摘要", "object": "胜利,汉语词汇。拼音:shèng lì胜利,指达到预期的目的。与“失败”相对。有“成功”的意思,古代打仗成功称胜利,比赛夺冠胜利称“成功”。其他寓意也很广泛(如:一件事坚持到了最后也称胜利)。胜利在英语中都为victory [Victory ]"}, {"predicate": "外文名", "object": "win"}, {"predicate": "反义词", "object": "失败"}, {"predicate": "拼音", "object": "shèng lì"}, {"predicate": "中文名", "object": "胜利"}, {"predicate": "释义", "object": "获得成功或达到目的"}, {"predicate": "义项描述", "object": "汉语词语"}, {"predicate": "标签", "object": "文化"}], "subject": "胜利"}
{"alias": ["胜利"], "subject_id": "37234", "type": ["Thing"], "data": [{"predicate": "摘要", "object": "《胜利》是由[英] 约瑟夫·康拉德所著一部讽喻小说,新华出版社出版发行。"}, {"predicate": "作者", "object": "[英] 约瑟夫·康拉德"}, {"predicate": "ISBN", "object": "9787516620762"}, {"predicate": "书名", "object": "胜利"}, {"predicate": "出版社", "object": "新华出版社"}, {"predicate": "义项描述", "object": "[英] 约瑟夫·康拉德所著小说"}], "subject": "胜利"}
...
...除了知识库外,我们还有一批标注样本,格式如下:
{"text_id": "1", "text": "南京南站:坐高铁在南京南站下。南京南站", "mention_data": [{"kb_id": "311223", "mention": "南京南站", "offset": "0"}, {"kb_id": "341096", "mention": "高铁", "offset": "6"}, {"kb_id": "311223", "mention": "南京南站", "offset": "9"}, {"kb_id": "311223", "mention": "南京南站", "offset": "15"}]}
{"text_id": "2", "text": "比特币吸粉无数,但央行的心另有所属|界面新闻 · jmedia", "mention_data": [{"kb_id": "278410", "mention": "比特币", "offset": "0"}, {"kb_id": "199602", "mention": "央行", "offset": "9"}, {"kb_id": "215472", "mention": "界面新闻", "offset": "18"}]}
{"text_id": "3", "text": "解读《万历十五年》", "mention_data": [{"kb_id": "131751", "mention": "万历十五年", "offset": "3"}]}
{"text_id": "4", "text": "《时间的针脚第一季》迅雷下载_完整版在线观看_美剧...", "mention_data": [{"kb_id": "NIL", "mention": "时间的针脚第一季", "offset": "1"}, {"kb_id": "57067", "mention": "迅雷", "offset": "10"}, {"kb_id": "394479", "mention": "美剧", "offset": "23"}]}
...
...这个训练数据标注的是query文本(text)中的实体(mention)、实体所在的位置(offset)以及对应在知识库里边的实体id(kb_id),每个query文本可能识别出多个实体。由于预测的时候仅仅提供query文本,因此需要同时做实体识别和实体链接。
基本思路 #
上面已经说到,在百度这个比赛中,不仅仅需要找到实体对应的知识库id,还需要先把实体找出来,换言之,我们需要先做实体识别,然后再做实体链接。在这一节中,我们结合赛题数据对这两个任务进行基本分析,以得到后面解决问题的思路。
实体识别的技术显然已经很成熟了,标配的方案是BiLSTM+CRF,当然最近也流行用Bert+CRF进行Fine Tune。在本文的模型中,实体识别的模型是“LSTM+半指针半标注结构”,外加一些人工特征,这样做既是出于速度上的考虑,也是结合本身标注数据特点来做的。
而实体链接这一步,我们看到知识库中每个实体的对应着多个“属性-属性值”对。分别处理这些“属性-属性值”对显得颇为繁琐,所以我干脆将所有的“属性-属性值”都拼成一个字符串,当作该实体的完整描述了,例如下面是名为“胜利”的某个实体拼接成字符串后的完整描述:
摘要:英雄联盟胜利系列皮肤是拳头公司制作的具有纪念意义限定系列皮肤之一。拳头公司制作的具有纪念意义限定系列皮肤还包括英雄联盟冠军系列皮肤、msi季中冠军赛征服者系列以及英雄联盟全球总决赛冠军系列皮肤。每到赛季结束时,拳头公司都会制作胜利系列皮肤作为赛季奖励来认可那些在排位赛中勇猛拼搏达到黄金段位的玩家。
制作方:riot games
外文名:victorious
来源:英雄联盟
中文名:胜利
属性:虚拟
义项描述:游戏《英雄联盟》胜利系列限定皮肤
名称:胜利
这样一来,每个实体对应的是一个(通常比较长的)文本描述,我们要做实体链接,实际上就是要将query文本、实体span与这个实体描述匹配起来。总的来说,比较接近于两个文本的匹配问题,所以笔者采用的做法是将query文本和实体描述文本分别编码,然后在query文本中标记出某个实体位置,再接着query文本和实体描述的编码通过Attention融合起来,最后变成一个二分类问题。
这样做的好处是训练成本比较低,缺点是每次识别处理query文本的一个实体,以及每次只能遍历知识库中的单个实体,总的来说采样效率较低,训练时间相对会长一些。预测的时候则是遍历所有同名实体,逐个跟query文本、实体span做二分类,最后输出概率最高的那个。
模型细节 #
这里逐一介绍笔者的处理和建模过程。在笔者的实现里,实体标注和实体链接两个部分是联合训练的,并且共享了部分模块。模型的整体思想(包括训练方案)都跟《基于DGCNN和概率图的轻量级信息抽取模型》一文类似,读者也可以对比着来阅读。
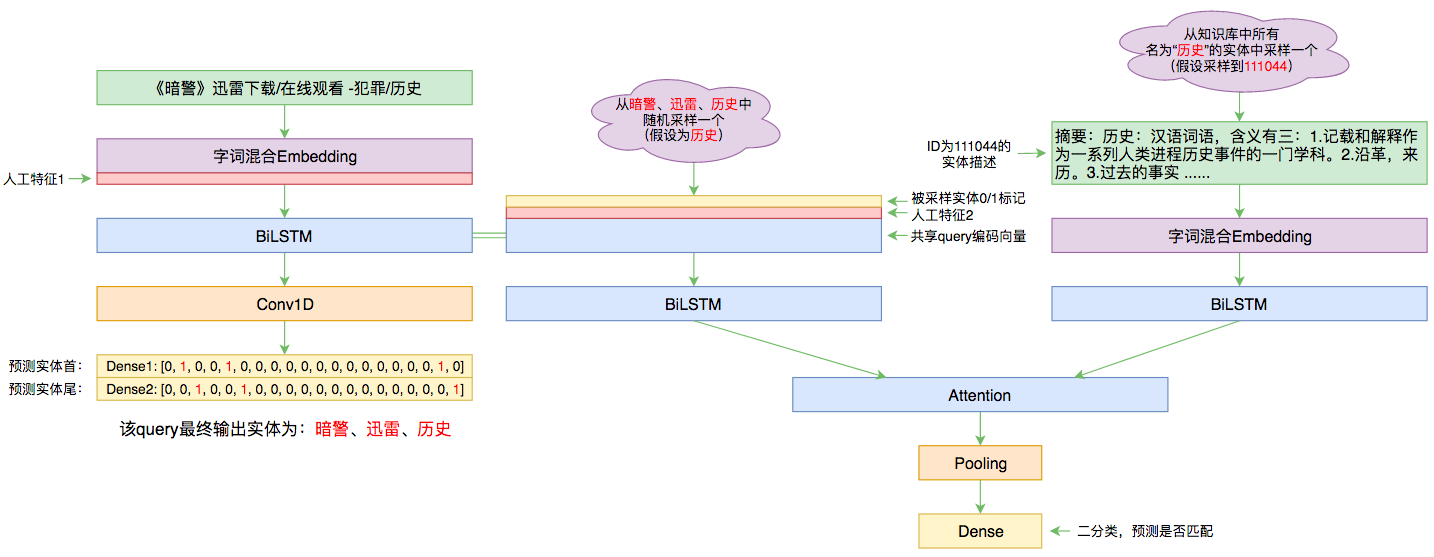
本文的实体链接模型总图(可以点击查看大图)
实体识别 #
首先是实体识别部分,分“基本模型”和“人工特征”两部分介绍。
基本模型 #
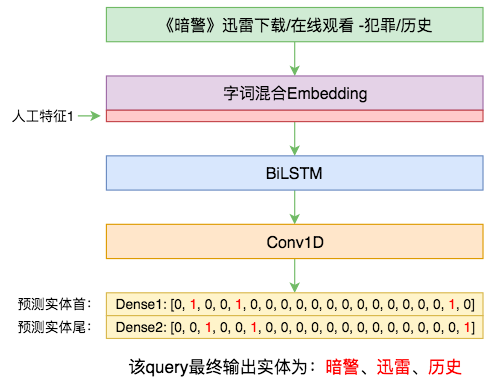
本文的实体识别模型
“基本模型”是指神经网络部分,通过传入的字词混合Embedding和人工特征来做字标注,标注结构依然是笔者之前构思的“半指针半标注结构”(参考这里和这里)。
不同于以往用全CNN的习惯,本次模型主要还是用到了双向LSTM,因为这一次不打算将模型做得太深,而模型非常浅(只有一两层)的时候,双向LSTM往往比CNN和Attention都要好。
人工特征 #
由于已经给出了知识库,并且识别出来的实体名都是在知识库里边出现过的(知识库的alias字段,如果没出现过可以视为标注错误),所以实体识别的一个baseline是直接把知识库里边所有的alias拿出来,组成一个词库,然后根据这个词库做一个最大匹配模型。这样做实体的召回率为92%左右,但是精度不高,只有30%左右,总的F1约为40%。
接着,我们可以观察到,在训练数据中,对实体的标注是相当“任性”的,总的来说就是主观因素相当大,可以说这根本就不是什么基于语义的实体识别,而更多的是“标注人员标注轨迹建模”,也就是说我们主要是在努力标注人员的标注习惯,而不是建立在语义理解基础上的实体识别。
比如,前面示意图中的query“《暗警》迅雷下载/在线观看 -犯罪/历史”只标注出了“暗警”、“迅雷”、“历史”三个实体,事实上“下载”、“在线”、“观看”、“犯罪”都是知识库里边的实体,而且存在能够适配这个query的实体id。那为什么不标?只能说标注人员不喜欢标/不想标/没力气标了~还有一种情况是:比如“高清视频”,在有些query中“高清视频”是作为一整个实体被标注出来的,而有些query中则是作为“高清”、“视频”两个实体标注的(因为“高清视频”、“高清”、“视频”都是知识库里边的实体)。
所以,有很多实体识别结果是没有什么道理可言的,就是标注人员的习惯而已。而为了更好地拟合标注人员的标注习惯,我们可以通过训练集做一些统计,统计一下知识库的哪些实体被标注得多,哪些实体标注得少,这样就可以对知识库的实体做一个基本的过滤(过滤细节参考后面的开源代码),用过滤后的实体集做词典来构建最大匹配模型,最终的实体召回率在91.8%左右,但是精度可以达到60%,F1可以达到70%+。
也就是说,只要通过简单的统计和最大匹配,就可以将实体识别这一步的F1做到70%+,我们把这个最大匹配的结果转为0/1特征传入到基本模型中,相当于用基本模型在最大匹配的结果上作进一步的过滤,最终实体识别的F1约为81%(具体值不记得了)。
实体链接 #
现在是实体链接这一步,依然分“基本模型”和“人工特征”两部分介绍,依然是一个相当朴素的基准模型基础上结合人工特征来提升。
基本模型 #
在实体链接的模型中,我们要做的事情是“判断query中的某个实体跟知识库中某个同名实体是否匹配”,为此,我们就需要随机采样:从query的所有识别出的实体中随机采样一个,然后从知识库里边所有同名实体中采样一个。
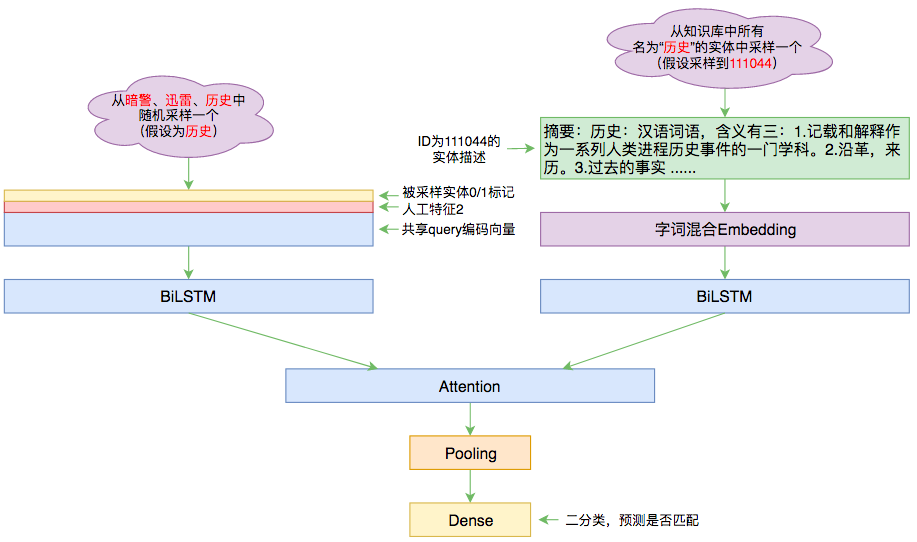
本文的实体链接模型
对于query,我们先沿用实体识别这一步对query文本的编码序列,然后将采样到的实体用一个0/1序列来标记,拼接到这个编码序列中,同时拼接到编码序列的还有一些人工特征,拼接完成后再做一个BiLSTM,得到最终的编码序列$\boldsymbol{Q}$;在同名实体这一边,把同名实体的描述拿出来后,经过Embedding层(跟query的Embedding共享)后再接一个BiLSTM,就完成对实体描述的编码$\boldsymbol{D}$了。
有了两者的编码序列后,就可以做Attention了,如《〈Attention is All You Need〉浅读(简介+代码)》所说,Attention三要素就是query、key、value,这里我们先用$\boldsymbol{Q}$做query、$\boldsymbol{D}$做key和value做一次Attention,然后再用$\boldsymbol{D}$做query、$\boldsymbol{Q}$做key和value做一次Attention,两次Attention分别用MaxPooling得到固定长度的向量,然后拼接起来,接一个全连接做2分类。
人工特征 #
实体链接中用到的人工特征是以query主体的,最终生成的是跟query一样长度的向量序列,拼接到query的编码结果中。在本文的模型的,用到的人工特征有三个:
1、query的每个字是否在实体描述中出现过(对应一个0/1序列);
2、query和实体描述都分词,然后判断query每个词是否在实体描述中出现过(对应一个0/1序列,每个词对应的标记要重复词的长度那么多次,以保证得到通常长度的序列);
3、query中的每个词/片段,是否为该实体的某个object(对应一个0/1序列,object的含义参考文章开头给出的知识库样例)。
印象中这三个特征对实体链接的准确率提升还是比较明显的(但具体幅度忘记了)。
此外,在预测的时候,还用到了一个统计结果。前面已经强调过,实体识别这一步其实更像是“标注行为建模”而不是“语义理解”,而且带有相当多的随机性,事实上实体链接这一步也是如此。我们可以统计发现,对于某些实体,它们在知识库中可能会有很多同名实体,但是被标注出来的可能只有其中几个,剩下的说不定标注人员看都没看,也就是说,本来可能是50选1的问题,在标注人员的标注习惯里边可能变成了5选1。
于是我们可以对训练集所有出现过的实体及其对应的实体id进行统计,这样一来对于每个实体名我们都可以得到一个分布,这个分布描述的是当前名字的实体被标注的id的分布情况,如果分布相当集中在其中几个id中,那么我们干脆就只保留这几个id好了,剩下的同名实体全部去掉好了。事后发现,这样既提高了预测速度,也提高了准确性。
代码分享 #
Github地址:https://github.com/bojone/el-2019
代码测试环境是Python 2.7 + Keras 2.2.4 + Tensorflow 1.8,整个模型只需要一个GTX1060 6G版就可以跑起来,非常轻松~其他部分跟之前的信息抽取模型的实验炼丹差不多,其实代码也是在那个基础上改过来的,自然差别不大。
文章小结 #
本文分享了一次实体链接比赛的参赛过程,从模型上看整体模型比较朴素,主要效果提升在于所提出的人工特征。这些人工特征主要是人工观察数据特点得出的统计特征,属于比赛的一些trick,事实上这些trick有投机取巧之嫌,未必能在真正的生产环境中用到,但却紧密结合了赛题数据特点。
还是那句话,笔者更倾向于认为这更像是一次标注行为建模,而不是真正的语义理解竞赛,尤其是在实体识别这一步,主观性太强了,是整个比赛的主要瓶颈之一。为了提升最终分数,我们必须要花相当大的力气做好实体识别这一步,但是做好实体识别这一步,只能说你更好地拟合了标注人员的行为,而不是真正最好了语义上的实体识别,对比赛的初衷——实体链接——更没有太大帮助。
而且真的是生产环境的话,对实体识别往往是有标准方法的,所以通常只需要做好实体链接。这是笔者所认为的这次比赛的失策之处。
当然,标注数据来之不易,还是感谢百度大佬举办比赛以及提供标注数据~
转载到请包括本文地址:https://spaces.ac.cn/archives/6919
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 03, 2019). 《百度实体链接比赛后记:行为建模和实体链接 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6919
@online{kexuefm-6919,
title={百度实体链接比赛后记:行为建模和实体链接},
author={苏剑林},
year={2019},
month={Sep},
url={\url{https://spaces.ac.cn/archives/6919}},
}

September 9th, 2019
https://github.com/panchunguang/ccks_baidu_entity_link
刚好参加了今年的ccks,上面是这个任务第一名的解决方案,苏神可以看看
好的,谢谢,拜读一下~
September 11th, 2019
大大~请问代码中的这个文件夹下的数据是在哪里下的
word2vec = Word2Vec.load('../../kg/word2vec_baike/word2vec_baike')
这是word2vec词向量吗?
https://kexue.fm/archives/6906
跟这里开源的是同一个
September 25th, 2019
苏神,想请教个问题哦,如果我想把bert 的输出 150,21128压缩为150 256但是需要减少信息损失,是选择用一个不加激活不加bias的dense呢,还是用不加激活的卷积?
你说的是mlm的输出?默认encoder部分不是输出768么?哪来的21128?
October 15th, 2019
“而且真的是生产环境的话,实体识别往往是有标准方法”
请问苏神,这里的标准方法是指 RNN系/Bert系+CRF 吗?
我的意思是生产环境用的方法就叫做标准方法,至于具体是什么方法,我怎么知道~每个人每个公司的生产环境都不一样。
谢谢苏神回复
October 30th, 2019
你好,请问哪里有实体链指的数据集可以下载?求分享,邮箱 434835764@qq.com
April 16th, 2020
苏神你好,
阅读代码,我发现词的 embedding 没有放到模型里面去做,这是不是为了节省 GPU 空间?
苏神有篇文章解释了,大致是说这样可以保留词向量的先验信息,相当于用字向量在词向量基础上finetune
是的,词向量可以在别处无监督学习到更丰富的知识,另外固定embedding也有助于防止过拟合。
July 6th, 2020
您好,请问您在插入人工特征的三种方法中,各个短句的长度不一致,您是怎么处理的呢?
人工特征与输入的query是等长的。
嗯嗯,所以您是把手工特征和原始数据拼在一起输入了。
我有个想法是,可否考虑把手工特征和经过模型后的特征拼接在一起?
这就随你怎么玩了,试验了才知道~
May 12th, 2021
苏神,看了你后面用 bert4keras 重写的三元组抽取,思考用类似的方法做实体链接的任务,现在编码遇到一个问题不知道怎么解决,还望不吝赐教。
data_generator 返回的前 4 个是输入 text 的 token 和 segment,以及随机选择的候选实体对应的描述的 token 和 segment,但是我发现 bert4keras 直接用 bert.model.inputs 处理第一句话的 token 和 segment,我调用类似 train_model = Model(bert.model.inputs + bert1.model.inputs, output) 希望两个 bert 模型读取两个句子的编码特征,但是会报错 ValueError: The name "Input-Token" is used 2 times in the model. All layer names should be unique.
在网上查阅之后也没有什么思路,希望苏神可以指导一下如何处理。(因为需要先找出实体再选一个实体的描述,所以没办法对两句话一起编码,所以思考的是再经过一个 Dense 层对两个句子向量做一个是否匹配的判断)
既然是重名,那就让它不重名就是了。
如果是bert4keras的话,build_transformer_model时可以传入参数prefix='xxx'来做区分;如果是一般的keras模型,可以通过下述代码来转:
for layer in model.layers:
layer.name = 'xxx' + layer.name
model = Model(model.input, model.output)
感谢苏神指导!模型跑的过程中还出现了一个问题,之前是按字切分能够正常跑,但是 bert 是 wordpiece 切分,导致预测结果和原来最大匹配序列结果长度不同没办法作乘积过滤,仔细看了 spo 模型发现对实体也 encode 然后在 token_ids 里面找对应起始位置,这样全部都统一到 token_ids 的长度里面了,真是太妙了!
June 30th, 2021
苏神好,我用bert做端到端的实体链接,左边用bert做ner,然后取bert的最后一层输出和候选实体描述经过另一个bert的两个向量concat起来再经过dense层输出链接结果。但是左边ner遇到比较大的问题,最初用最大匹配的时候发现头尾标1的地方预测概率都在0.95以上,nerf1为0.74,el pre为0.58,recall为0.79,f1为0.67,当时猜测过拟合;后来去掉最大匹配发现预测实体头的概率都在0.8-0.9,预测实体尾的概率在0.1-0.2左右 f1都是0。我认为是代码编写的问题,同一个模型该怎么既预测头的概率又预测尾的概率……这个问题卡了很久的时间,如果苏神有时间的话还望不吝赐教!
下面是模型代码
'''ner 模型,给定句子和最大匹配结果,输出预测 mention'''
bert_ner = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, return_keras_model=False, prefix='mention_detection_')
match_word_heads = Lambda(lambda x: K.expand_dims(x, 2))(match_word_heads) # 让 pred_mention_heads 和 match_word_heads 都是(batch_size, seq_len, 1)
match_word_tails = Lambda(lambda x: K.expand_dims(x, 2))(match_word_tails)
ner_feature = Concatenate()([bert_ner.model.output, match_word_heads, match_word_tails])
pred_mention_heads = Dense(units=1, activation='sigmoid')(ner_feature)
pred_mention_tails = Dense(units=1, activation='sigmoid')(ner_feature)
pred_mention_heads = Lambda(lambda x: x[0] * x[1])([pred_mention_heads, match_word_heads]) # 在最大匹配的结果中筛选实体
pred_mention_tails = Lambda(lambda x: x[0] * x[1])([pred_mention_tails, match_word_tails]) # 在最大匹配的结果中筛选实体
# 接收 text 的 token segm`ent,最大匹配的词的开头和结尾位置,输出预测实体的开始结束位置
ner_model = Model(bert_ner.model.inputs + [match_word_heads_in, match_word_tails_in], [pred_mention_heads, pred_mention_tails])
'''el 模型,判断两个句子是否匹配'''
ner_output = GlobalMaxPooling1D(data_format="channels_last")(bert_ner.model.output)
bert_el = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, return_keras_model=False, prefix='sentence_match_')
el_output = GlobalMaxPooling1D(data_format="channels_last")(bert_el.model.output)
match_output = Concatenate()([ner_output, el_output])
pred_labels = Dense(units=1, activation='sigmoid')(match_output)
el_model = Model(bert_ner.model.inputs + bert_el.model.inputs, pred_labels)
'''整体模型'''
train_model = Model(
bert_ner.model.inputs + bert_el.model.inputs + [ gold_mention_heads_in , gold_mention_tails_in , match_word_heads_in , match_word_tails_in , labels_in],
[pred_mention_heads, pred_mention_tails, pred_labels]
)
November 9th, 2021
1/1407 [..............................] - ETA: 13:38:18 - loss: 0.4108
2/1407 [..............................] - ETA: 11:57:15 - loss: 0.3902
3/1407 [..............................] - ETA: 10:23:11 - loss: 0.3721
4/1407 [..............................] - ETA: 9:58:51 - loss: 0.3764
5/1407 [..............................] - ETA: 10:23:50 - loss: nan
您好,为什么程序跑通了会出现loss为nan现象 尝试过修改参数、减小batch size、更换激活函数更换参数初始化方法 都会出现loss为nan现象。
我也不清楚呢~