






3
Apr
变分自编码器(三):这样做为什么能成?
By 苏剑林 | 2018-04-03 | 184962位读者 | 引用话说我觉得我自己最近写文章都喜欢长篇大论了,而且扎堆地来~之前连续写了三篇关于Capsule的介绍,这次轮到VAE了,本文是VAE的第三篇探索,说不准还会有第四篇~不管怎么样,数量不重要,重要的是能把问题都想清楚。尤其是对于VAE这种新奇的建模思维来说,更加值得细细地抠。
这次我们要关心的一个问题是:VAE为什么能成?
估计看VAE的读者都会经历这么几个阶段。第一个阶段是刚读了VAE的介绍,然后云里雾里的,感觉像自编码器又不像自编码器的,反复啃了几遍文字并看了源码之后才知道大概是怎么回事;第二个阶段就是在第一个阶段的基础上,再去细读VAE的原理,诸如隐变量模型、KL散度、变分推断等等,细细看下去,发现虽然折腾来折腾去,最终居然都能看明白了。
这时候读者可能就进入第三个阶段了。在这个阶段中,我们会有诸多疑问,尤其是可行性的疑问:“为什么它这样反复折腾,最终出来模型是可行的?我也有很多想法呀,为什么我的想法就不行?”
前文之要
让我们再不厌其烦地回顾一下前面关于VAE的一些原理。
VAE希望通过隐变量分解来描述数据$X$的分布
$$p(x)=\int p(x|z)p(z)dz,\quad p(x,z) = p(x|z)p(z)\tag{1}$$
13
Jun
“噪声对比估计”杂谈:曲径通幽之妙
By 苏剑林 | 2018-06-13 | 172856位读者 | 引用说到噪声对比估计,或者“负采样”,大家可能立马就想到了Word2Vec。事实上,它的含义远不止于此,噪音对比估计(NCE, Noise Contrastive Estimation)是一个迂回但却异常精美的技巧,它使得我们在没法直接完成归一化因子(也叫配分函数)的计算时,就能够去估算出概率分布的参数。本文就让我们来欣赏一下NCE的曲径通幽般的美妙。
注:由于出发点不同,本文所介绍的“噪声对比估计”实际上更偏向于所谓的“负采样”技巧,但两者本质上是一样的,在此不作区分。
问题起源
问题的根源是难分难舍的指数概率分布~
指数族分布
在很多问题中都会出现指数族分布,即对于某个变量$\boldsymbol{x}$的概率$p(\boldsymbol{x})$,我们将其写成
$$p(\boldsymbol{x}) = \frac{e^{G(\boldsymbol{x})}}{Z}\tag{1}$$
其中$G(\boldsymbol{x})$是$\boldsymbol{x}$的某个“能量”函数,而$Z=\sum_{\boldsymbol{x}} e^{G(\boldsymbol{x})}$则是归一化常数,也叫配分函数。这种分布也称为“玻尔兹曼分布”。
27
Jun
从动力学角度看优化算法(一):从SGD到动量加速
By 苏剑林 | 2018-06-27 | 156708位读者 | 引用在这个系列中,我们来关心优化算法,而本文的主题则是SGD(stochastic gradient descent,随机梯度下降),包括带Momentum和Nesterov版本的。对于SGD,我们通常会关心的几个问题是:
SGD为什么有效?
SGD的batch size是不是越大越好?
SGD的学习率怎么调?
Momentum是怎么加速的?
Nesterov为什么又比Momentum稍好?
...
这里试图从动力学角度分析SGD,给出上述问题的一些启发性理解。
梯度下降
既然要比较谁好谁差,就需要知道最好是什么样的,也就是说我们的终极目标是什么?
训练目标分析
假设全部训练样本的集合为$\boldsymbol{S}$,损失度量为$L(\boldsymbol{x};\boldsymbol{\theta})$,其中$\boldsymbol{x}$代表单个样本,而$\boldsymbol{\theta}$则是优化参数,那么我们可以构建损失函数
$$L(\boldsymbol{\theta}) = \frac{1}{|\boldsymbol{S}|}\sum_{\boldsymbol{x}\in\boldsymbol{S}} L(\boldsymbol{x};\boldsymbol{\theta})\tag{1}$$
而训练的终极目标,则是找到$L(\boldsymbol{\theta})$的一个全局最优点(这里的最优是“最小”的意思)。
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 165690位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 66274位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
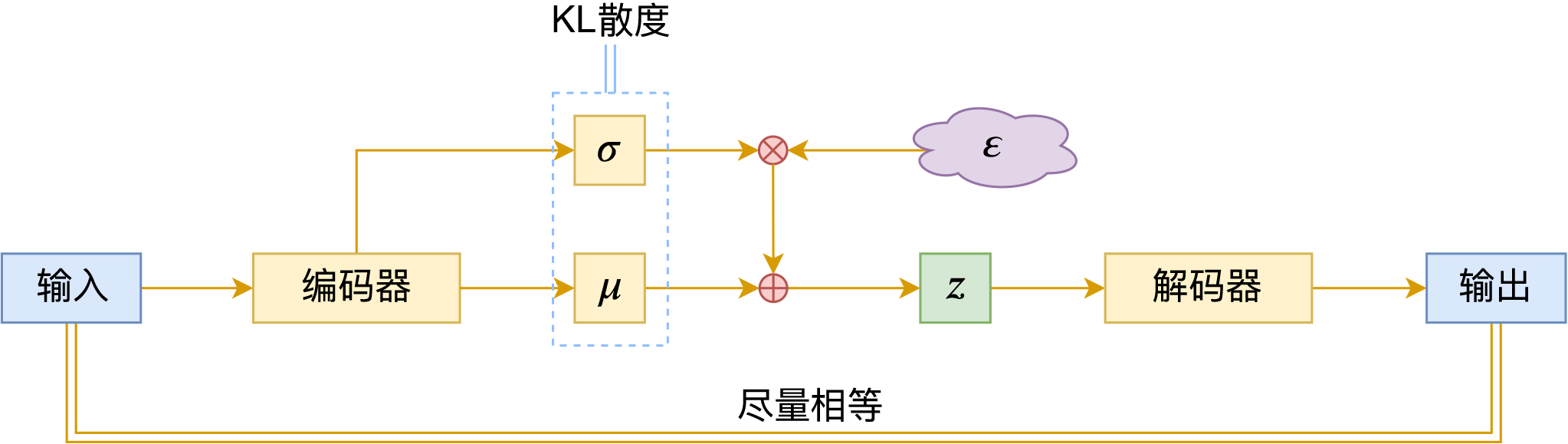
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 96217位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 200361位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
8
Jul
两个多元正态分布的KL散度、巴氏距离和W距离
By 苏剑林 | 2021-07-08 | 101188位读者 | 引用正态分布是最常见的连续型概率分布之一。它是给定均值和协方差后的最大熵分布(参考《“熵”不起:从熵、最大熵原理到最大熵模型(二)》),也可以看作任意连续型分布的二阶近似,它的地位就相当于一般函数的线性近似。从这个角度来看,正态分布算得上是最简单的连续型分布了。也正因为简单,所以对于很多估计量来说,它都能写出解析解来。
本文主要来计算两个多元正态分布的几种度量,包括KL散度、巴氏距离和W距离,它们都有显式解析解。
正态分布
这里简单回顾一下正态分布的一些基础知识。注意,仅仅是回顾,这还不足以作为正态分布的入门教程。
概率密度
正态分布,也即高斯分布,是定义在$\mathbb{R}^n$上的连续型概率分布,其概率密度函数为
\begin{equation}p(\boldsymbol{x})=\frac{1}{\sqrt{(2\pi)^n \det(\boldsymbol{\Sigma})}}\exp\left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\}\end{equation}

最近评论