






28
Oct
朋友们,来瓶汽水吧!有趣的换汽水问题
By 苏剑林 | 2015-10-28 | 32814位读者 | 引用————怀念我曾经参加过的小学数学竞赛。
从一道小学竞赛题谈起
笔者小学五年级时参加了第一次数学竞赛,叫“育苗杯”,大多数题目都记不清楚了,唯一记得很清楚的是如下这道题目(不完全相同,意思类似):
假设汽水一块钱一瓶,而且4个空瓶子可以换一瓶汽水喝。如果我有30块钱,我最多可以喝到多少瓶汽水?

来瓶汽水吧
当然,这道题并不困难,30块钱能买30瓶汽水,然后留下30个空瓶子,这30个空瓶子可以换来7瓶汽水,剩下2个空瓶子;喝完汽水后,剩下9个空瓶子,可以换来2瓶汽水,剩下1个空瓶子;喝完汽水后,剩下3个空瓶子。算算看,这时候我们已经喝了30+7+2=39瓶汽水了。(不考虑撑着啊,也可以分给别人喝^_^)整个过程如下表:
$$\begin{array}{c|cccc}
\hline
\text{空瓶子数} & 30 & 2+7 & 1+2 & ? \\
\hline
\text{已喝汽水数} & 30 & 7 & 2 & ? \\
\hline \end{array}$$
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 329427位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 151138位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}
31
Aug
再谈类别不平衡问题:调节权重与魔改Loss的对比联系
By 苏剑林 | 2020-08-31 | 75923位读者 | 引用类别不平衡问题,也称为长尾分布问题,在本博客里已经有好几次相关讨论了,比如《从loss的硬截断、软化到focal loss》、《将“Softmax+交叉熵”推广到多标签分类问题》、《通过互信息思想来缓解类别不平衡问题》。对于缓解类别不平衡,比较基本的方法就是调节样本权重,看起来“高端”一点的方法则是各种魔改loss了(比如Focal Loss、Dice Loss、Logits Adjustment等),本文希望比较系统地理解一下它们之间的联系。
长尾分布:少数类别的样本数目非常多,多数类别的样本数目非常少。
从光滑准确率到交叉熵
这里的分析主要以sigmoid的2分类为主,但多数结论可以平行推广到softmax的多分类。设$x$为输入,$y\in\{0,1\}$为目标,$p_{\theta}(x) \in [0, 1]$为模型。理想情况下,当然是要评测什么指标,我们就去优化那个指标。对于分类问题来说,最朴素的指标当然就是准确率,但准确率并没有办法提供有效的梯度,所以不能直接来训练。
13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 87586位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
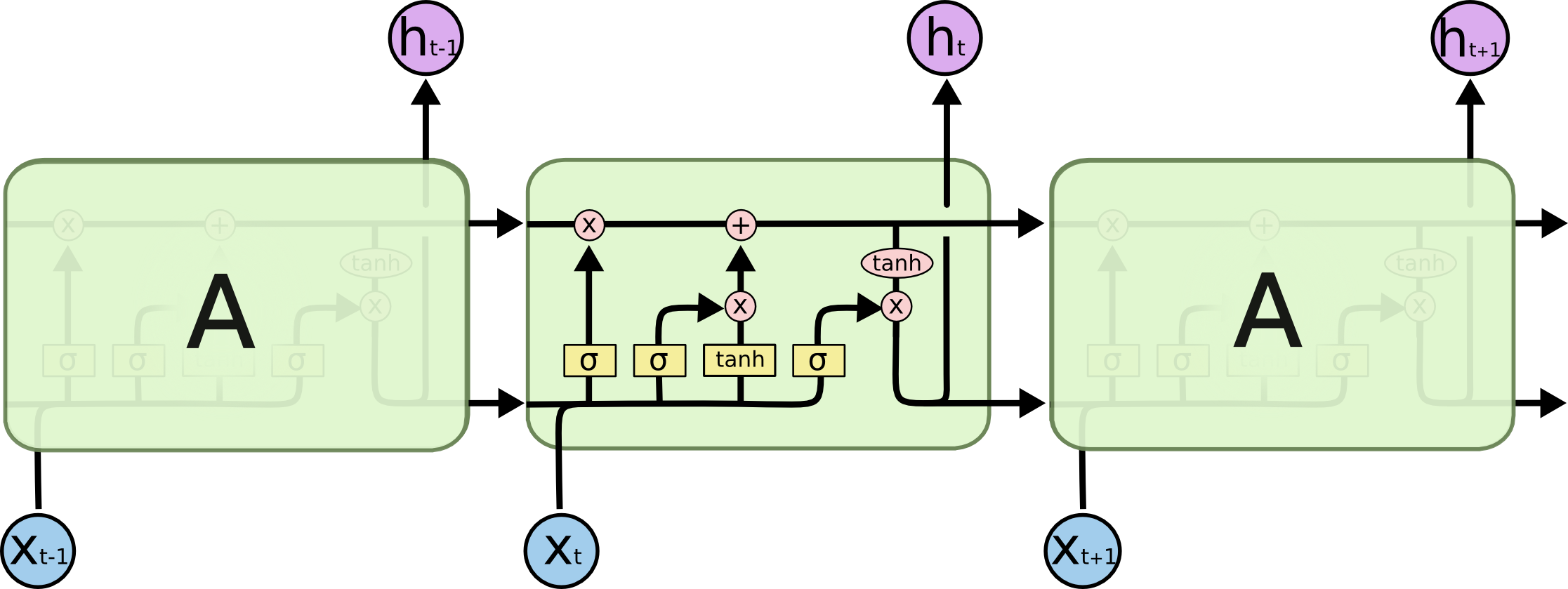
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 19104位读者 | 引用
5
Jun
重温SSM(二):HiPPO的一些遗留问题
By 苏剑林 | 2024-06-05 | 20208位读者 | 引用书接上文,在上一篇文章《重温SSM(一):线性系统和HiPPO矩阵》中,我们详细讨论了HiPPO逼近框架其HiPPO矩阵的推导,其原理是通过正交函数基来动态地逼近一个实时更新的函数,其投影系数的动力学正好是一个线性系统,而如果以正交多项式为基,那么线性系统的核心矩阵我们可以解析地求解出来,该矩阵就称为HiPPO矩阵。
当然,上一篇文章侧重于HiPPO矩阵的推导,并没有对它的性质做进一步分析,此外诸如“如何离散化以应用于实际数据”、“除了多项式基外其他基是否也可以解析求解”等问题也没有详细讨论到。接下来我们将补充探讨相关问题。
离散格式
假设读者已经阅读并理解上一篇文章的内容,那么这里我们就不再进行过多的铺垫。在上一篇文章中,我们推导出了两类线性ODE系统,分别是:
\begin{align}
&\text{HiPPO-LegT:}\quad x'(t) = Ax(t) + Bu(t) \label{eq:legt-ode}\\[5pt]
&\text{HiPPO-LegS:}\quad x'(t) = \frac{A}{t}x(t) + \frac{B}{t}u(t) \label{eq:legs-ode}\end{align}
其中$A,B$是与时间$t$无关的常数矩阵,HiPPO矩阵主要指矩阵$A$。在这一节中,我们讨论这两个ODE的离散化。
1
Mar
科学空间|Scientific Spaces 介绍
By 苏剑林 | 2009-03-01 | 393665位读者 | 引用中山大学基础数学研究生,本科为华南师范大学。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文、计算机,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜Feynman。爱好阅读,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也开开数据“挖掘机”。明明要学基础数学,偏偏不务正业,沉溺神经网络,妄想人工智能,曾未在ACL、AAAI、COLING等会议上发表一篇文章。近期还挣扎在NLP大坑,在科学空间(https://kexue.fm)期待大家的拯救。
历史内容
华南师范大学数学系学生。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜费曼。长期阅读《天文爱好者》和《环球科学》,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也当当电工。近期主要学习理论物理,在科学空间期待大家的指教。
名称:科学空间|Scientific Spaces
网址:http://kexue.fm
站长:苏剑林
信念:探索我们的世界,聆听我们的自然
网站历史
2009.03.01 网站初步建立,刚开始的时候使用的是BoBlog以及宇宙驿站的空间,内容定位:科学转载。 2009.03.28 开始进行大规模推广,访问量开始提高 2009.03-05 期间进行过多次改变,特别是Blog程序的转换,内容上的改革等

最近评论