






29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 100186位读者 |在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
ALBERT #
ALBERT来自论文《ALBERT: A Lite BERT for Self-supervised Learning of Language Representations》,顾名思义它认为自己的特点就是Lite,那么这个Lite的具体含义是什么呢?不少国内朋友对ALBERT的印象是又小又快又好,事实真的如此吗?
特点 #
简单来说,ALBERT其实就是一个参数共享的BERT,相当于将函数$y=f_n(f_{n-1}(\cdots(f_1(x))))$改为了$y=f(f(\cdots(f(x))))$,其中$f$代表模型的每一层,这样本来有$n$层参数,现在只有1层了,因此参数量大大减少,或者说保存下来的模型权重体积很小,这是Lite的第一个含义;然后,由于参数总量变少了,模型训练所需的时间和显存也会相应变小,这是Lite的第二个含义。此外,当模型很大时,参数共享将会是模型的一个很强的正则化手段,所以相比BERT没那么容易过拟合,最终其大模型有一定的性能提升,这是ALBERT的亮点。
预测 #
要注意,我们没说到预测速度。很明显,在预测阶段参数共享不会带来加速,因为模型反正就是一步步前向计算,不会关心当前的参数跟过去的参数是否一样,而且就算一样也加速不了(因为输入也不一样了)。所以,同一规格的ALBERT和BERT预测速度是一样的,甚至真要较真的话,其实ALBERT应该更慢一些,因为ALBERT对Embedding层用了矩阵分解,这一步会带来额外的计算量,虽然这个计算量一般来说我们都感知不到。
训练 #
而对于训练速度,虽然会有所提升,但是并没有想象中那么明显。参数量可以缩小到原来的$1/n$,并不意味着训练速度也提升为原来的$n$倍,在笔者之前的实验里边,base版本的ALBERT相比同样是base的BERT,训练速度大概只是快10%~20%,显存的缩小幅度也类似,如果模型更小(tiny/small版),那么这个差距将会进一步缩小,换句话说,ALBERT的训练优势只有在大模型才明显,对于不大的模型,这个优势依然是难以有明显感知的。
效果 #
至于效果,其实ALBERT的原论文已经说得很清楚,如下表所示。参数共享会限制模型的表达能力,因此ALBERT的xlarge版才能持平BERT的large版,而要稳定超过它则需要xxlarge版,换句话说,只要版本规格小于xlarge,那么同一规格的ALBERT效果都是不如BERT的。中文任务上的评测结果也是类似的,可以参考这里和这里。而且笔者之前还做过更极端的实验:加载ALBERT的权重,但是放开参数共享的约束,把ALBERT当BERT用,效果也会有提升!(参考《抛开约束,增强模型:一行代码提升albert表现》)所以,小规格ALBERT不如BERT基本是实锤的了。
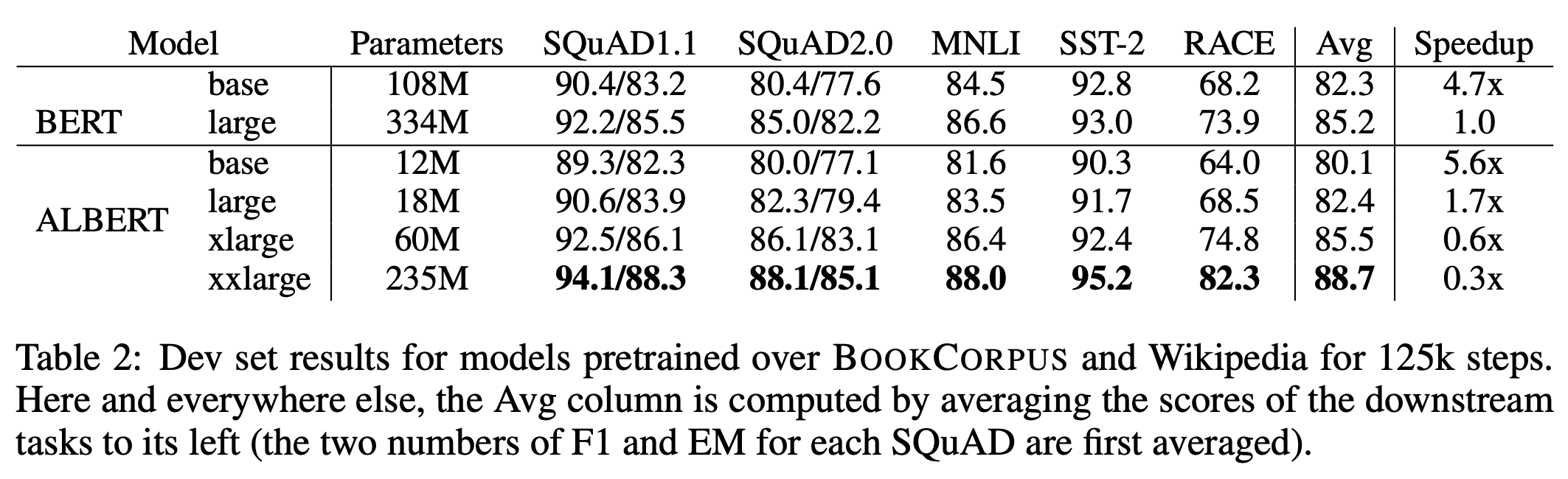
ALBERT实验结果
结论 #
所以,总结出来的建议就是:如果不到xlarge版,那么没必要用ALBERT,同一速度的ALBERT效果比BERT差,同一效果的ALBERT速度比BERT慢。现在BERT也都有tiny/small版了,比如我司开源的,基本上一样快而且效果更好,除非你是真的需要体积小这个特点。
那xlarge版是什么概念?有些读者还没尝试过BERT,因为机器跑不起来;多数读者显存有限,只跑过base版的BERT,没跑过或者跑不起large版的。而xlarge是比large更大的,对设备的要求更高,所以说白了,对于大部分读者来说都没必要用ALBERT的。
那为什么会有ALBERT又快又好的说法传出来呢?除了一些自媒体的不规范宣传外,笔者想很大程度上是因为brightmart同学的推广了。
不得不说,brightmart同学为ALBERT在国内的普及做出来不可磨灭的贡献,早在ALBERT的英文版模型都还没放出来的时候,brightmart就训练并开源了ALBERT中文版(albert_zh),并且还一鼓作气训练了tiny、small、base、large、xlarge多个版本,当时BERT就只有base和large版本,而ALBERT有tiny和small版本,大家一试发现确实比BERT快很多,所以不少人就留下了ALBERT很快的印象。事实上ALBERT很快跟ALBERT没什么关系,重点是tiny/small,对应的BERT tiny/small也很快...
当然,你可以去思考ALBERT参数共享起作用的更本质的原因,也可以去研究参数共享之后如何提高预测速度,这些都是很有价值的问题,只是不建议你用低于xlarge版本的ALBERT。
ELECTRA #
ELECTRA则来自论文《ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators》。说实话,ELECTRA真是一个一言难尽的模型,它刚出来的时候让很多人兴奋过,后来正式发布开源后又让很多人失望过,目前的实战表现虽然不能说差,却也不能说多好。
特点 #
ELECTRA的出发点是觉得BERT的MLM模型随机选择一部分Token进行Mask的这个操作过于简单了,想要增加一下它的难度。所以它借鉴了GAN的思想,用普通的方式训练一个MLM模型(生成器),然后根据MLM模型对输入句子进行采样替换,将处理后的句子输入到另外一个模型(判别器)中,判断句子哪些部分是被替换过的,哪些部分是被没被替换的。生成器和判别器是同步训练的,因此随着生成器的训练,判断难度会慢慢增加,直观想象有利于模型学到更有价值的内容。最后只保留判别器的Encoder来用,生成器一般就不要了。
由于这种渐进式的模式使得训练过程会更有针对性,所以ELECTRA的主要亮点是训练效率更高了,按照论文的说法能够用1/4的时间甚至更少来达到同样规格的BERT的效果,这是ELECTRA的主要亮点。
理论 #
然而,在笔者看来,ELECTRA是一个在理论上站不住脚的模型。
为什么这样说呢?ELECTRA的思想源于GAN,但是在CV中,我们有把训练好的GAN模型的判别器拿来Finetune下游任务的例子吗?至少笔者没看到过。事实上,这是理论上不成立的,拿原始GAN来说,它的判别器最优解是$D(x)=\frac{p(x)}{p(x)+q(x)}$,其中$p(x),q(x)$分别是真假样本的分布。假设训练是稳定的,并且生成器具有足够强的拟合能力,那么随着模型的训练,假样本会逐渐趋于真样本,所以$q(x)$趋于$p(x)$,那么$D(x)$就趋于常数$1/2$。也就是说,理论上最后的判别器只是一个常值函数,你怎么能保证它提取出好的特征来呢?
虽然ELECTRA不完全是GAN,但在这一点上是一致的,所以ELECTRA强调作为生成器的MLM模型不能太过复杂(不然像上面说的判别器就退化为常数了),论文说是在生成器的大小在判别器的$1/4$到$1/2$之间效果是最好的。这就开始“玄学”起来了,刚才我们只论证了太好不行,没法论证为什么差一点就行,也没法论证差多少才行,以及不清楚为什么生成器和判别器同步训练会更好,现在这些都变成了纯粹“炼丹”的东西了。
效果 #
当然,我说它理论上站不住脚,并不是说它效果不好,更不是说相关评测造假了。由于对生成器的能力做了约束,因此ELECTRA训练的结果还是有一定意义的,其效果还算过得去,只不过是让我们经历了一个“期望越大,失望越大”的过程罢了。
ELECTRA的论文首先出现在ICLR 2020的投稿中,当时的结果让大家都很震惊,大概就是small版的ELECTRA模型远超small版的BERT,甚至直逼base版,而base版的ELECTRA达到了large版BERT的水平。结果当代码和权重放出后,Github上所显示的成绩却让人“大跌眼镜”——基本下降了2个百分点。后来作者出来澄清了,说论文上写的是dev集而Github上写的是test集,大家才稍微理解了一点,不过这样的话,ELECTRA相比BERT在效果上就变得没有什么亮点了。(参考从《ELECTRA: 超越BERT, 19年最佳NLP预训练模型》到《谈谈我对ELECTRA源码放出的看法》)
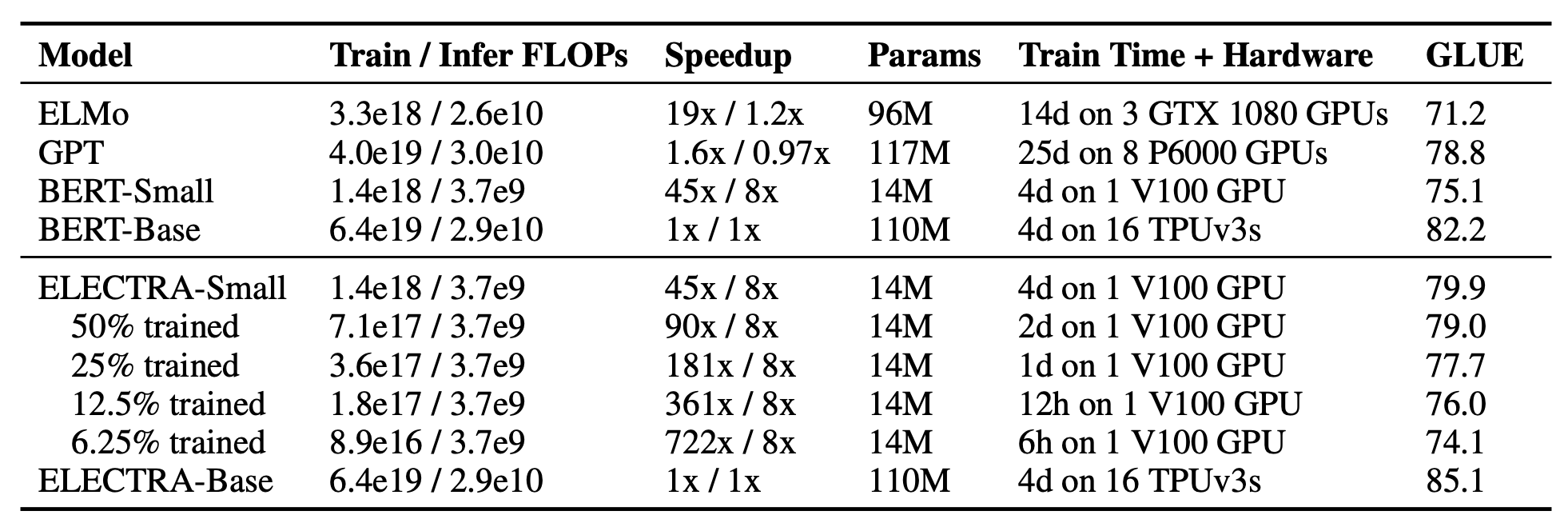
ELECTRA在论文上报告的结果
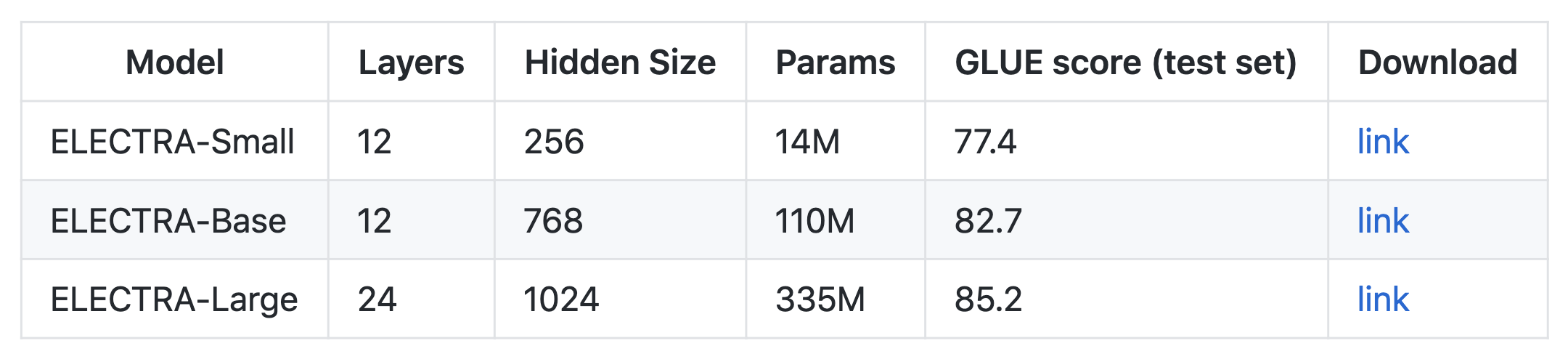
ELECTRA在Github上报告的结果
事实上,ELECTRA在中文任务上的评测更加准确地反映了这一点,比如哈工大开源的Chinese-ELECTRA中,ELECTRA在各个任务上与同级别的BERT相差无几了,有个别任务有优势,但是并未出现那种“碾压式”的结果。
失彼 #
可能有读者会想,就算效果差不多,但人家预训练快了,好歹也是个优点嘛,这点确实不否认。但是这两天Arxiv的一篇新论文表明,ELECTRA的“效果差不多”可能只是在简单任务上的假象,如果构建复杂一点的任务,它还是会被BERT“吊打”。
这篇论文的名字是《Commonsense knowledge adversarial dataset that challenges ELECTRA》,作者基于SQuAD 2.0数据集用同义词替换的方式构建了一个新的数据集QADS,然后按照作者的测试,在SQuAD 2.0上能达到88%的ELECTRA large模型在QADS上只有22%了,而有意思的是BERT都能做到60%多。当然这篇论文看起来还很粗糙,还没得到权威肯定,所以也不能尽信,但其结果已经能引起我们对ELECTRA的反思了。之前论文《Probing Neural Network Comprehension of Natural Language Arguments》的一个“not”就把BERT拉下了神坛,看来ELECTRA也会有这种问题,而且可能还更严重。
抛开其它证据不说,其实笔者觉得,ELECTRA最终抛弃了MLM本身就是一个“顾此失彼”的操作:你说你的出发点是MLM太简单,你就想办法提高MLM难度就是了,你把MLM换成判别器干嘛呢?直接用一个生成器网络来改进MLM模型(而不是将它换成判别器)是有可能,前段时间微软的论文《Variance-reduced Language Pretraining via a Mask Proposal Network》就提供了这样的一种参考方案,它让生成器来选择要Mask掉的位置,而不是随机选,虽然我没有重复它的实验,但它的整个推理过程都让人觉得很有说服力,不像ELECTRA纯拍脑袋的感觉。此外,笔者还想再强调一下,MLM是很有用的,它不单单是一个预训练任务,还是一个有实用价值的模型,比如《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》。
结论 #
所以,说了那么多,结论就是:ELECTRA的预训练速度是加快了,但从目前的实验来看,它相比同级别的BERT在下游任务上的效果并没有突出优势,可以试用,但是效果变差了也不用太失望。此外,如果你需要用到MLM部分的权重(比如用来做UniLM的文本生成,参考这里),那么也不能用ELECTRA,因为ELECTRA的主体是判别器,它不是MLM模型;而ELECTRA中作为生成器的MLM模型,则比判别器简化,可能存在拟合能力不足、学习不充分等问题,并不是一个很好的预训练MLM模型。
至于ELECTRA背后的思想,即针对MLM随机Mask这一步过于简单进行改进,目前看来方向是没有错误的,但是将生成式模型换成判别式模型的有效性依然还需要进一步验证,如果有兴趣深入分析的读者,倒是可以进一步思考研究。
文章小结 #
本文记录了笔者对ALBERT和ELECTRA的看法与思考,主要是综合笔者自己的一些实验结果,以及参考了一些参考文献,希望比较客观地表达清楚这两个模型的优缺点,让读者在做模型选择的时候心里更有底一些。这两个模型在特定的场景下都有其可取之处,但也存在一些限制,清楚这些限制及其来源有助于读者更好地使用这两个模型。
笔者没有刻意中伤某个模型的意思,如果有什么理解不当之处,欢迎大家留言讨论。
转载到请包括本文地址:https://spaces.ac.cn/archives/7846
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Oct. 29, 2020). 《用ALBERT和ELECTRA之前,请确认你真的了解它们 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7846
@online{kexuefm-7846,
title={用ALBERT和ELECTRA之前,请确认你真的了解它们},
author={苏剑林},
year={2020},
month={Oct},
url={\url{https://spaces.ac.cn/archives/7846}},
}

July 21st, 2023
苏神好,
“所以q(x)趋于p(x),那么D(x)就趋于常数1/2。也就是说,理论上最后的判别器只是一个常值函数,你怎么能保证它提取出好的特征来呢?”
对这句话的下述理解不知是否正确,请指教。
随着生成器和判别器在博弈过程中共同成长,各自能力会分别得到逐步提升,假设这个训练过程稳定,不发生模式塌陷或其他导致训练失败的情况,最终训练成功后,虽然D(x)趋于常数1/2,但判别器的训练成绩已经在很高的水平,这时判别器隐藏层还是能够提取较好的特征。
模型是会偷懒的,当要输出常数2时,内部特征究竟是否良好,我是真无法判断。
July 15th, 2024
你好苏神,假设我要从头训练bert系列模型,在一个私有的小数据集上(大概10w样本),是否选择albert模型可以缓解数据量减少的缺陷?
直觉上这个场景用albert也没任何好处,拿个普通的roberta去继续预训练就好。