






21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 75406位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
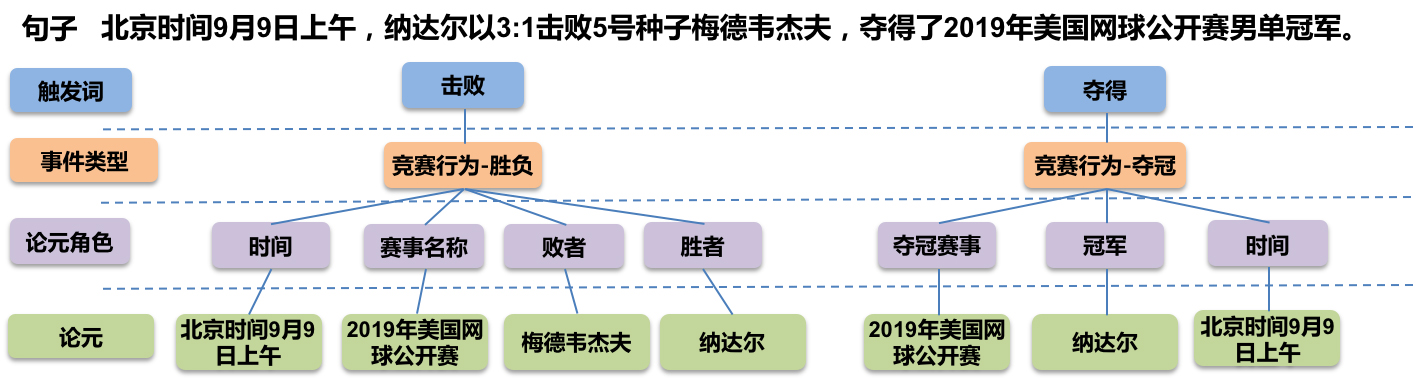
标准的事件抽取样本(图片来自百度DuEE的GitHub)
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 57042位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
10
May
logsumexp运算的几个不等式
By 苏剑林 | 2022-05-10 | 21887位读者 | 引用$\text{logsumexp}$是机器学习经常遇到的运算,尤其是交叉熵的相关实现和推导中都会经常出现,同时它还是$\max$的光滑近似(参考《寻求一个光滑的最大值函数》)。设$x=(x_1,x_2,\cdots,x_n)$,$\text{logsumexp}$定义为
\begin{equation}\text{logsumexp}(x)=\log\sum_{i=1}^n e^{x_i}\end{equation}
本文来介绍$\text{logsumexp}$的几个在理论推导中可能用得到的不等式。
基本界
记$x_{\max} = \max(x_1,x_2,\cdots,x_n)$,那么显然有
\begin{equation}e^{x_{\max}} < \sum_{i=1}^n e^{x_i} \leq \sum_{i=1}^n e^{x_{\max}} = ne^{x_{\max}}\end{equation}
各端取对数即得
\begin{equation}x_{\max} < \text{logsumexp}(x) \leq x_{\max} + \log n\end{equation}
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 66207位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
9
Nov
CoSENT(三):作为交互式相似度的损失函数
By 苏剑林 | 2022-11-09 | 30197位读者 | 引用在《CoSENT(一):比Sentence-BERT更有效的句向量方案》中,笔者提出了名为“CoSENT”的有监督句向量方案,由于它是直接训练cos相似度的,跟评测目标更相关,因此通常能有着比Sentence-BERT更好的效果以及更快的收敛速度。在《CoSENT(二):特征式匹配与交互式匹配有多大差距?》中我们还比较过它跟交互式相似度模型的差异,显示它在某些任务上的效果还能直逼交互式相似度模型。
然而,当时笔者是一心想找一个更接近评测目标的Sentence-BERT替代品,所以结果都是面向有监督句向量的,即特征式相似度模型。最近笔者突然反应过来,CoSENT其实也能作为交互式相似度模型的损失函数。那么它跟标准选择交叉熵相比孰优孰劣呢?本文来补充这部分实验。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 19159位读者 | 引用
25
Apr
注意力和Softmax的两点有趣发现:鲁棒性和信息量
By 苏剑林 | 2023-04-25 | 28577位读者 | 引用最近几周笔者一直都在思考注意力机制的相关性质,在这个过程中对注意力及Softmax有了更深刻的理解。在这篇文章中,笔者简单分享其中的两点:
1、Softmax注意力天然能够抵御一定的噪声扰动;
2、从信息熵角度也可以对初始化问题形成直观理解。
鲁棒性
基于Softmax归一化的注意力机制,可以写为
\begin{equation}o = \frac{\sum\limits_{i=1}^n e^{s_i} v_i}{\sum\limits_{i=1}^n e^{s_i}}\end{equation}
有一天笔者突然想到一个问题:如果往$s_i$中加入独立同分布的噪声会怎样?
23
May
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度
By 苏剑林 | 2023-05-23 | 74940位读者 | 引用在LLM时代还玩朴素贝叶斯(Naive Bayes)?
这可能是许多读者在看到标题后的首个想法。确实如此,当古老的朴素贝叶斯与前沿的LLM相遇时,产生了令人惊讶的效果——我们可以直接扩展现有LLM模型的Context处理长度,无需对模型进行微调,也不依赖于模型架构,具有线性效率,而且效果看起来还不错——这就是本文所提出的NBCE(Naive Bayes-based Context Extension)方法。
摸石过河
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个相对独立的Context集合(比如$n$个不同的段落,至少不是一个句子被分割为两个片段那种),假设它们的总长度已经超过了训练长度,而单个$S_k$加$T$还在训练长度内。我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,即估计$p(T|S_1, S_2,\cdots,S_n)$。

最近评论