






2
Mar
MuP之上:3. 特殊情况特殊处理
By 苏剑林 | 2026-03-02 | 3468位读者 | 引用经过那么多篇相关博客的介绍,想必很多读者都对Muon优化器并不陌生——即便不清楚理论细节,应该也留下了一个“专为矩阵参数定制的优化器”的印象。然而,这个说法并不全对——比如对于输入端的Embedding层和输出段的LM Head来说,它们的参数虽然也都是矩阵,但并不适合用Muon(参考《Muon优化器指南:快速上手与关键细节》)。
为什么它们要被“区别对待”呢?本文将沿用首篇提出的三个稳定性指标,探讨不同类型的层的初始化规律及其对应的最速下降方向,从而回答这个问题。
前情回顾
在第一篇文章《MuP之上:1. 好模型的三个特征》中,我们提出了三个稳定性指标
16
Dec
让炼丹更科学一些(三):SGD的终点损失收敛
By 苏剑林 | 2025-12-16 | 9776位读者 | 引用目前我们已经有两篇文章讨论SGD的收敛性质,不过它们都只是损失值的收敛结果,所以它们只保证我们能找到最优的损失值,但不能保证找到最优值的所在位置$\boldsymbol{\theta}^*$,这是目前的结论跟实践之间的一个显著gap。直觉上,训练结束时的权重$\boldsymbol{\theta}_T$应该更接近理论最优的$\boldsymbol{\theta}^*$,我们也想知道理论上是否支撑这一点。
所以,这篇文章我们就将平均损失的收敛结果转化为终点损失的收敛结果,初步从理论上了解$\boldsymbol{\theta}_T$与$\boldsymbol{\theta}^*$差多远。
找出位置
我们从文章《让炼丹更科学一些(二):将结论推广到无界域》出发,它的核心结果是不等式
\begin{equation}\sum_{t=1}^T \eta_t \mathbb{E}[L(\boldsymbol{\theta}_t) - L(\boldsymbol{\varphi})]\leq \frac{\Vert\boldsymbol{\theta}_1 - \boldsymbol{\varphi}\Vert^2}{2} + \frac{G^2}{2}\sum_{t=1}^T \eta_t^2\label{leq:avg-2-mid3}\end{equation}
12
Dec
让炼丹更科学一些(二):将结论推广到无界域
By 苏剑林 | 2025-12-12 | 10941位读者 | 引用两年前,笔者打算开一个“科学炼丹”专题,本想着系统整理一下优化器的经典理论结果,但写了第一篇《让炼丹更科学一些(一):SGD的平均损失收敛》后,就一直搁置至今。主要原因在于,笔者总觉得这些经典优化结论所依赖的条件过于苛刻,跟实际应用相去甚远,尤其是进入LLM时代后,这些结论的参考价值似乎更加有限,所以就没什么动力继续写下去。
然而,近期在思考Scaling Law的相关问题时,笔者发现这些结论结果并非想象中那么“没用”,它可以为一些经验结果提供有益的理论洞见。因此,本文将重启该系列,继续推进这个专题文章的撰写,“偿还”之前欠下的“债务”。
结论回顾
记号方面我们沿用第一篇文章的,所以不再重复记号的介绍。第一篇文章的主要结论是:在适当的假设之下,SGD成立
\begin{equation}\frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta}_t) - \frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta}^*)\leq \frac{R^2}{2T\eta_T} + \frac{G^2}{2T}\sum_{t=1}^T\eta_t\label{leq:avg-1}\end{equation}
1
Aug
流形上的最速下降:1. SGD + 超球面
By 苏剑林 | 2025-08-01 | 29035位读者 | 引用类似“梯度的反方向是下降最快的方向”的描述,经常用于介绍梯度下降(SGD)的原理。然而,这句话是有条件的,比如“方向”在数学上是单位向量,它依赖于“范数(模长)”的定义,不同范数的结论也不同,Muon实际上就是给矩阵参数换了个谱范数,从而得到了新的下降方向。又比如,当我们从无约束优化转移到约束优化时,下降最快的方向也未必是梯度的反方向。
为此,在这篇文章中,我们将新开一个系列,以“约束”为主线,重新审视“最速下降”这一命题,探查不同条件下的“下降最快的方向”指向何方。
优化原理
作为第一篇文章,我们先从SGD出发,理解“梯度的反方向是下降最快的方向”这句话背后的数学意义,然后应用于超球面上的优化。不过在此之前,笔者还想带大家重温一下《Muon续集:为什么我们选择尝试Muon?》所提的关于优化器的“最小作用量原理(Least Action Principle)”。
30
Apr
一道概率不等式:盯着它到显然成立为止!
By 苏剑林 | 2025-04-30 | 27851位读者 | 引用前两天,QQ群里有群友抛出了一道不等式求证:
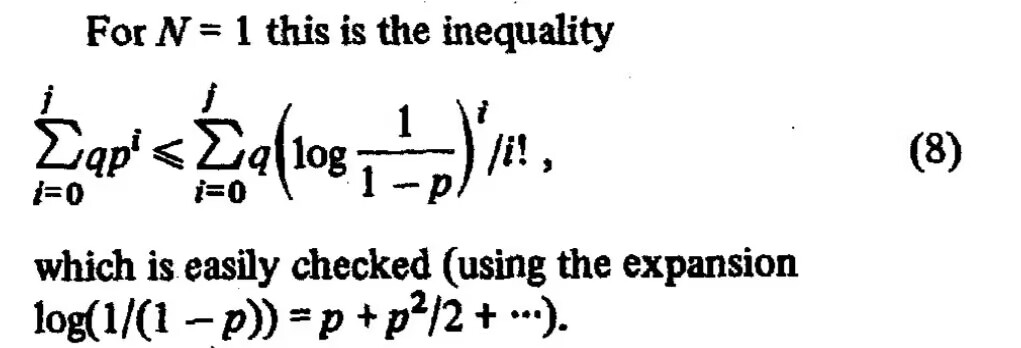
一道概率相关的不等式,出自《There is no fast single hashing algorithm》
简短的题目,加上“easily”的提示,让人觉得这似乎是显然成立的结果,然而提问者却表示尝试了很久仍未果。那么实际情况如何呢?是否真的是显然成立呢?
初步尝试
题目等价于证
\begin{equation}\sum_{i=0}^j p^i \leq \sum_{i=0}^j \left(\log\frac{1}{1-p}\right)^i/i!,\qquad p\in[0, 1)\label{eq:q}\end{equation}
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 187795位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
9
Jan
局部余弦相似度大,全局余弦相似度一定也大吗?
By 苏剑林 | 2024-01-09 | 53300位读者 | 引用在分析模型的参数时,有些情况下我们会将模型的所有参数当成一个整体的向量,有些情况下我们则会将不同的参数拆开来看。比如,一个7B大小的LLAMA模型所拥有的70亿参数量,有时候我们会将它当成“一个70亿维的向量”,有时候我们会按照模型的实现方式将它看成“数百个不同维度的向量”,最极端的情况下,我们也会将它看成是“七十亿个1维向量”。既然有不同的看待方式,那么当我们要算一些统计指标时,也就会有不同的计算方式,即局部计算和全局计算,这引出了局部计算的指标与全局计算的指标有何关联的问题。
本文我们关心两个向量的余弦相似度。如果两个大向量的维度被拆成了若干组,同一组对应的子向量余弦相似度都很大,那么两个大向量的余弦相似度是否一定就大呢?答案是否定的。特别地,这还跟著名的“辛普森悖论”有关。
问题背景
这个问题源于笔者对优化器的参数增量导致的损失函数变化量的分析。具体来说,假设优化器的更新规则是:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta_t \boldsymbol{u}_t\end{equation}
19
Dec
让炼丹更科学一些(一):SGD的平均损失收敛
By 苏剑林 | 2023-12-19 | 56135位读者 | 引用很多时候我们将深度学习模型的训练过程戏称为“炼丹”,因为整个过程跟古代的炼丹术一样,看上去有一定的科学依据,但整体却给人一种“玄之又玄”的感觉。尽管本站之前也关注过一些优化器相关的工作,甚至也写过《从动力学角度看优化算法》系列,但都是比较表面的介绍,并没有涉及到更深入的理论。为了让以后的炼丹更科学一些,笔者决定去补习一些优化相关的理论结果,争取让炼丹之路多点理论支撑。
在本文中,我们将学习随机梯度下降(SGD)的一个非常基础的收敛结论。虽然现在看来,该结论显得很粗糙且不实用,但它是优化器收敛性证明的一次非常重要的尝试,特别是它考虑了我们实际使用的是随机梯度下降(SGD)而不是全量梯度下降(GD)这一特性,使得结论更加具有参考意义。
问题设置
设损失函数是$L(\boldsymbol{x},\boldsymbol{\theta})$,其实$\boldsymbol{x}$是训练集,而$\boldsymbol{\theta}\in\mathbb{R}^N$是训练参数。受限于算力,我们通常只能执行随机梯度下降(SGD),即每步只能采样一个训练子集来计算损失函数并更新参数,假设采样是独立同分布的,第$t$步采样到的子集为$\boldsymbol{x}_t$,那么我们可以合理地认为实际优化的最终目标是
\begin{equation}L(\boldsymbol{\theta}) = \lim_{T\to\infty}\frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta})\label{eq:loss}\end{equation}

最近评论