






12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 43388位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
26
Jan
Transformer升级之路:16、“复盘”长度外推技术
By 苏剑林 | 2024-01-26 | 67718位读者 | 引用回过头来看,才发现从第7篇《Transformer升级之路:7、长度外推性与局部注意力》开始,“Transformer升级之路”这个系列就跟长度外推“杠”上了,接连9篇文章(不算本文)都是围绕长度外推展开的。如今,距离第7篇文章刚好是一年多一点,在这一年间,开源社区关于长度外推的研究有了显著进展,笔者也逐渐有了一些自己的理解,比如其实这个问题远不像一开始想象那么简单,以往很多基于局部注意力的工作也不总是有效,这暗示着很多旧的分析工作并没触及问题的核心。
在这篇文章中,笔者尝试结合自己的发现和认识,去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。
问题定义
顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等,LongBench就是就属于这类榜单。
21
Feb
“闭门造车”之多模态思路浅谈(一):无损输入
By 苏剑林 | 2024-02-21 | 140387位读者 | 引用这篇文章分享一下笔者关于多模态模型架构的一些闭门造车的想法,或者说一些猜测。
最近Google的Gemini 1.5和OpenAI的Sora再次点燃了不少人对多模态的热情,只言片语的技术报告也引起了大家对其背后模型架构的热烈猜测。不过,本文并非是为了凑这个热闹才发出来的,事实上其中的一些思考由来已久,最近才勉强捋顺了一下,遂想写出来跟大家交流一波,刚好碰上了两者的发布。
事先声明,“闭门造车”一词并非自谦,笔者的大模型实践本就“乏善可陈”,而多模态实践更是几乎“一片空白”,本文确实只是根据以往文本生成和图像生成的一些经验所做的“主观臆测”。
问题背景
首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗?
13
May
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
By 苏剑林 | 2024-05-13 | 66488位读者 | 引用前几天,幻方发布的DeepSeek-V2引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multi-head Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。
接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为$\boldsymbol{x}_1,\boldsymbol{x}_2,\cdots,\boldsymbol{x}_l$,其中$\boldsymbol{x}_i\in\mathbb{R}^d$,那么MHA可以形式地记为
18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 42203位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 141027位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 42333位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 194322位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
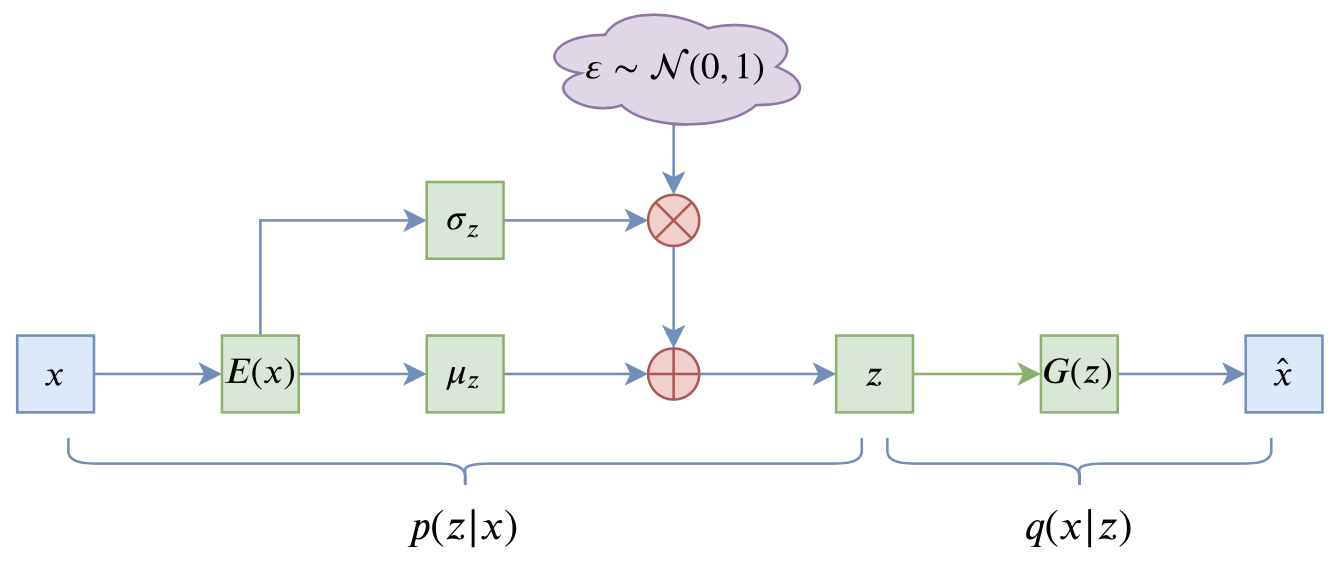
VAE训练流程图示

最近评论