






13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 88403位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
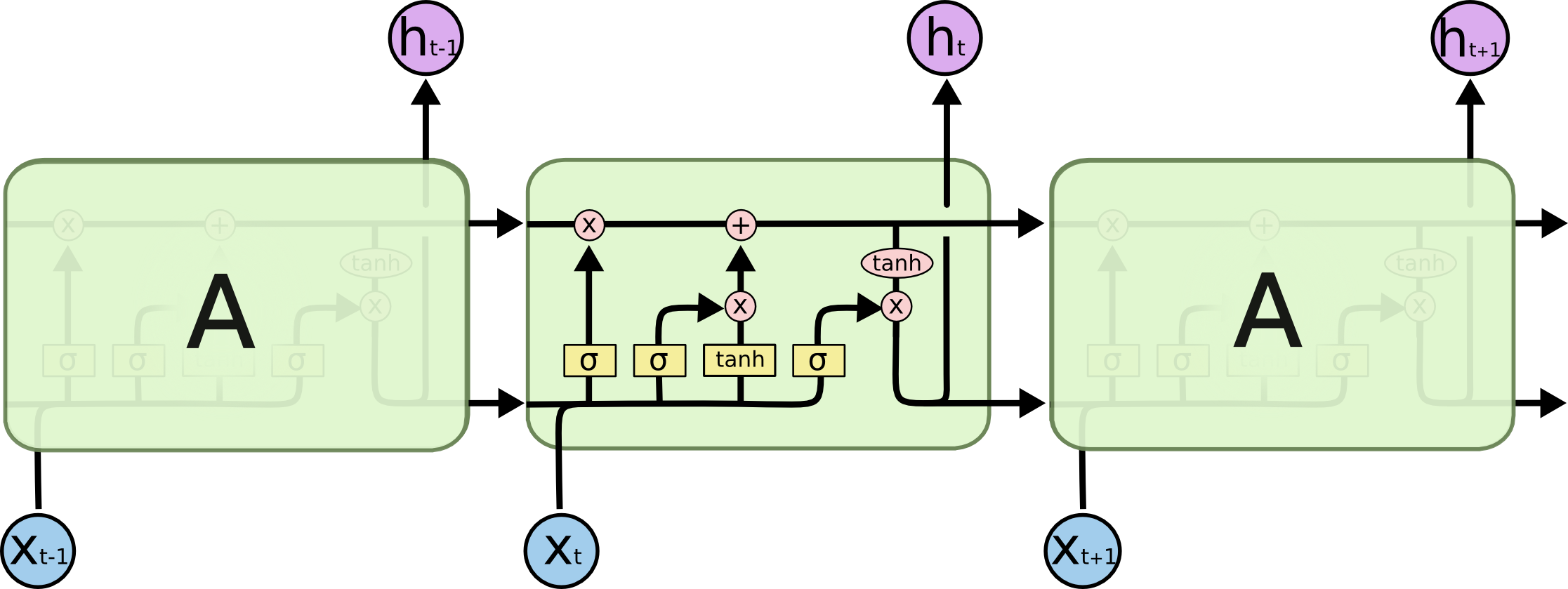
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 232856位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
24
Dec
RealFormer:把残差转移到Attention矩阵上面去
By 苏剑林 | 2020-12-24 | 92479位读者 | 引用大家知道Layer Normalization是Transformer模型的重要组成之一,它的用法有PostLN和PreLN两种,论文《On Layer Normalization in the Transformer Architecture》中有对两者比较详细的分析。简单来说,就是PreLN对梯度下降更加友好,收敛更快,对训练时的超参数如学习率等更加鲁棒等,反正一切都好但就有一点硬伤:PreLN的性能似乎总略差于PostLN。最近Google的一篇论文《RealFormer: Transformer Likes Residual Attention》提出了RealFormer设计,成功地弥补了这个Gap,使得模型拥有PreLN一样的优化友好性,并且效果比PostLN还好,可谓“鱼与熊掌兼得”了。
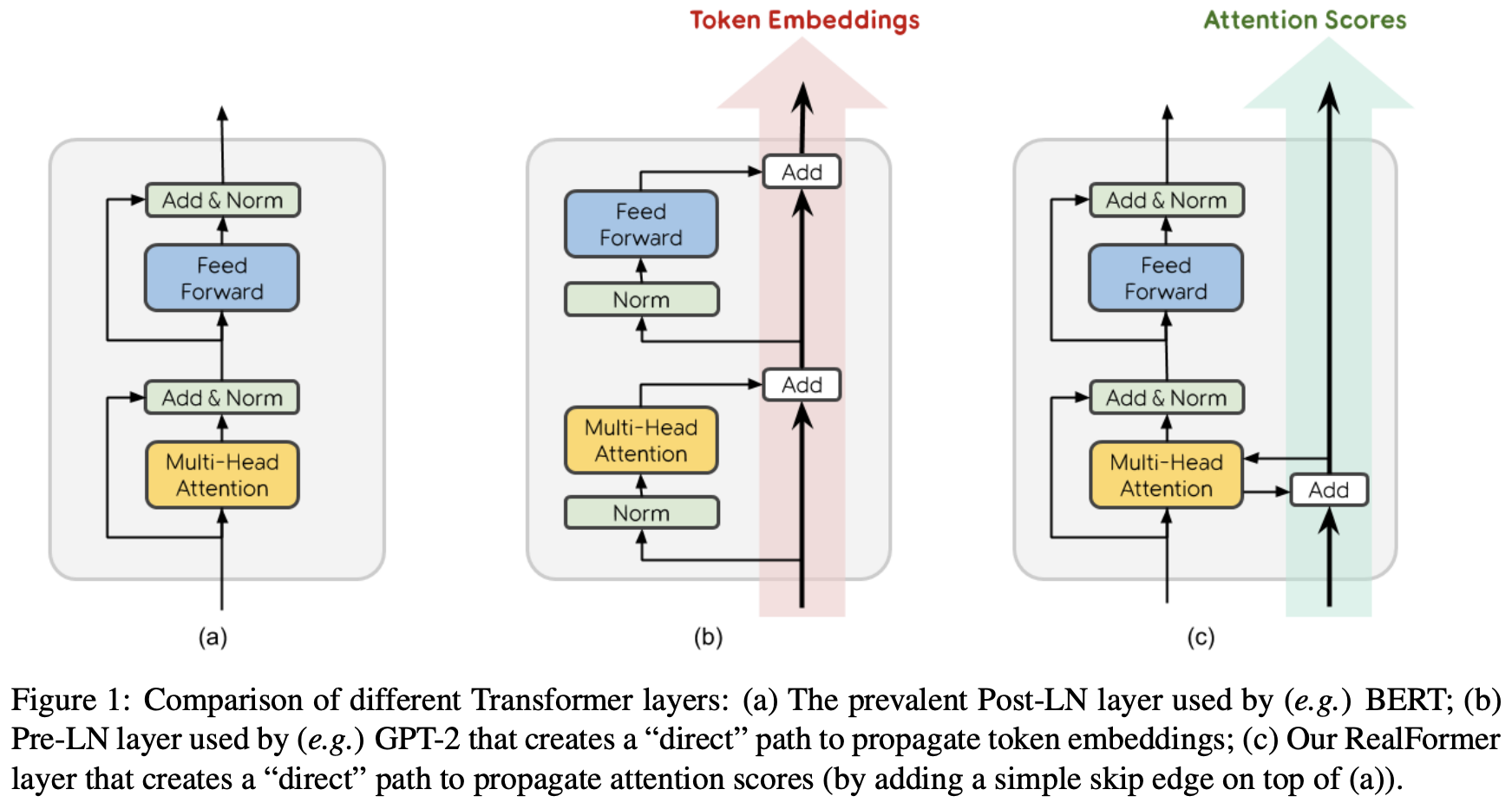
PostLN、PreLN和RealFormer结构示意图
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 207772位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
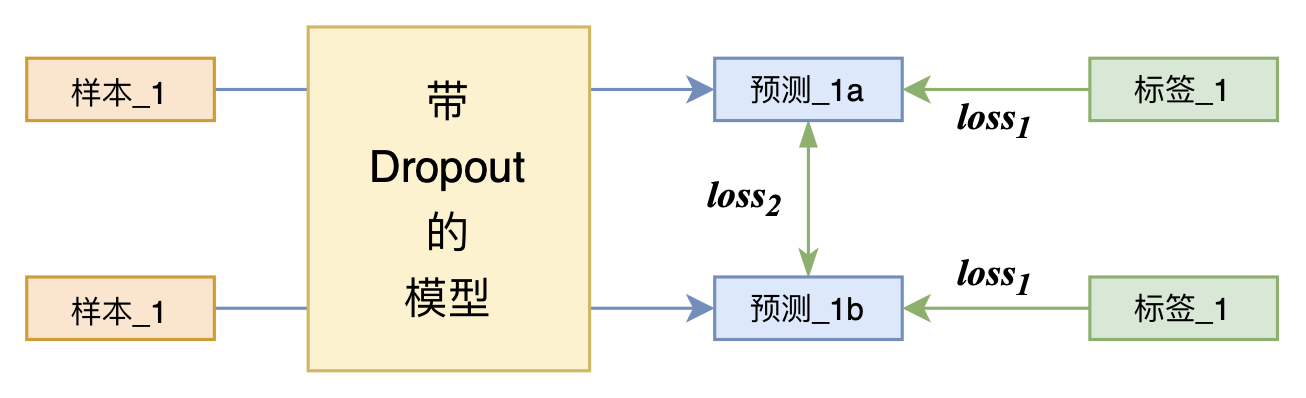
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
25
Feb
【搜出来的文本】⋅(四)通过增、删、改来用词造句
By 苏剑林 | 2021-02-25 | 46812位读者 | 引用“用词造句”是小学阶段帮助我们理解和运用词语的一个经典任务,从自然语言处理的角度来看,它是一个句子扩写或者句子补全任务,它其实要求我们具有不定向地进行文本生成的能力。然而,当前主流的语言模型都是单方向生成的(多数是正向的,即从左往右,少数是反向的,即从右往左),但用词造句任务中所给的若干个词未必一定出现在句首或者句末,这导致无法直接用语言模型来完成造句任务。
本文我们将介绍论文《CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling》,它使用MCMC采样使得单向语言模型也可以做到不定向生成,通过增、删、改操作模拟了人的写作润色过程,从而能无监督地完成用词造句等多种文本生成任务。
问题设置
无监督地进行文本采样,那么直接可以由语言模型来完成,而我们同样要做的,是往这个采样过程中加入一些信号$\boldsymbol{c}$,使得它能生成我们期望的一些文本。在本系列第一篇文章《【搜出来的文本】⋅(一)从文本生成到搜索采样》的“明确目标”一节中,我们就介绍了本系列的指导思想:把我们要寻找的目标量化地写下来,然后最大化它或者从中采样。
23
Mar
Transformer升级之路:2、博采众长的旋转式位置编码
By 苏剑林 | 2021-03-23 | 281249位读者 | 引用上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 301671位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
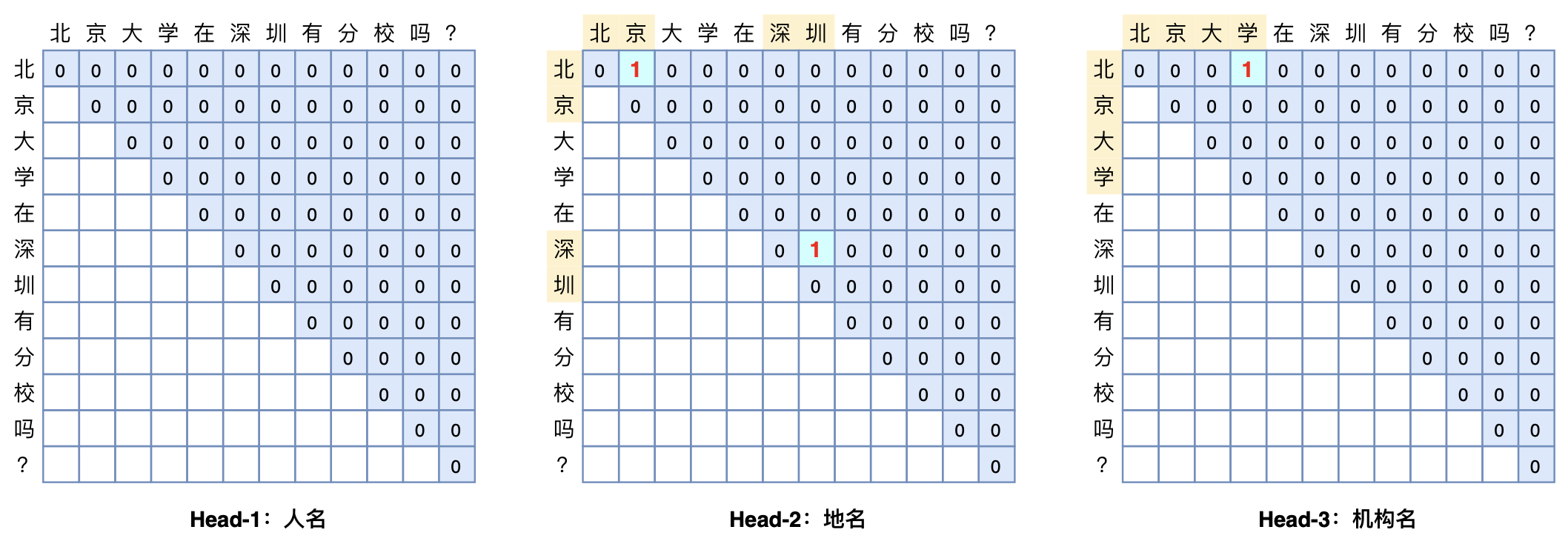
GlobalPointer多头识别嵌套实体示意图
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 132910位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}

最近评论