






20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 53453位读者 | 引用生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
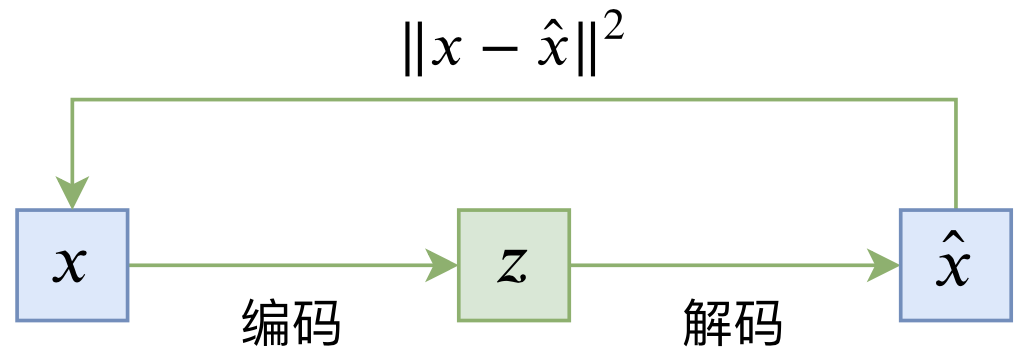
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 63443位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
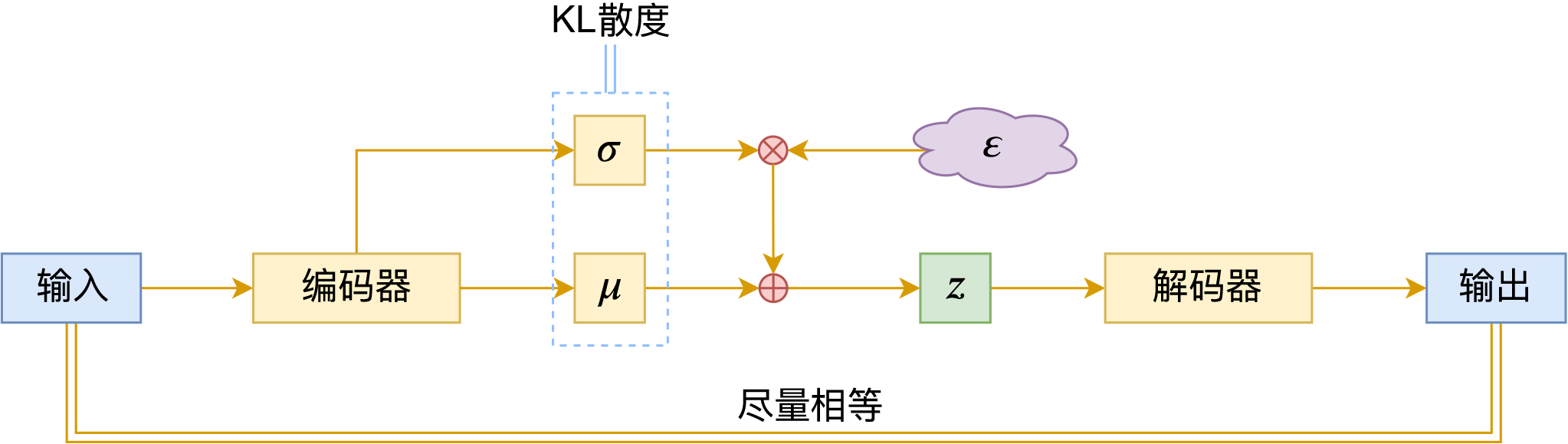
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 102383位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 199682位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
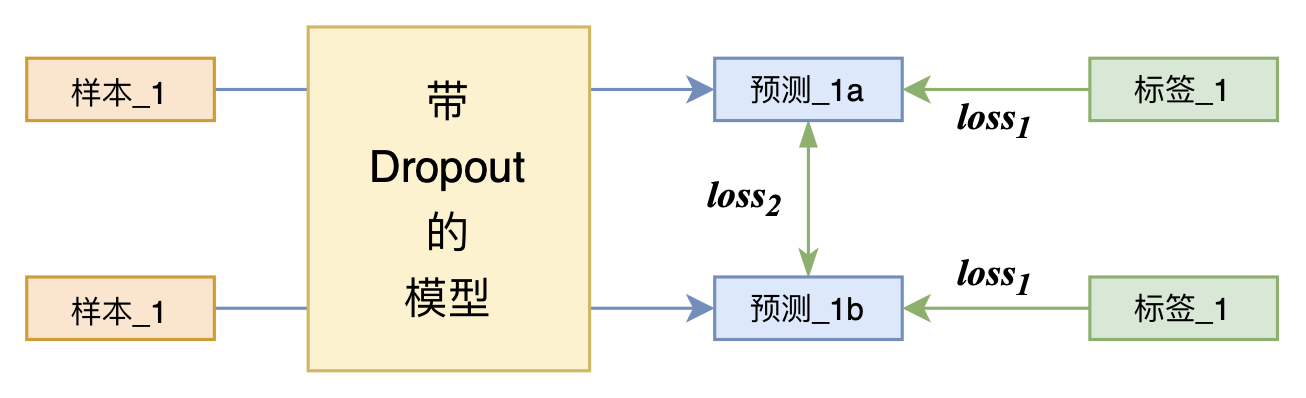
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 122982位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}
1
Sep
从三角不等式到Margin Softmax
By 苏剑林 | 2021-09-01 | 32182位读者 | 引用在《基于GRU和AM-Softmax的句子相似度模型》中我们介绍了AM-Softmax,它是一种带margin的softmax,通常用于用分类做检索的场景。当时通过图示的方式简单说了一下引入margin是因为“分类与排序的不等价性”,但没有比较定量地解释这种不等价性的来源。
在这篇文章里,我们来重提这个话题,从距离的三角不等式的角度来推导和理解margin的必要性。
三角不等式
平时,我们说的距离一般指比较直观的“欧氏距离”,但在数学上距离,距离又叫“度量”,它有公理化的定义,是指定义在某个集合上的二元函数$d(x,y)$,满足:
13
Oct
EMO:基于最优传输思想设计的分类损失函数
By 苏剑林 | 2023-10-13 | 49328位读者 | 引用众所周知,分类任务的标准损失是交叉熵(Cross Entropy,等价于最大似然MLE,即Maximum Likelihood Estimation),它有着简单高效的特点,但在某些场景下也暴露出一些问题,如偏离评价指标、过度自信等,相应的改进工作也有很多,此前我们也介绍过一些,比如《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》、《如何训练你的准确率?》、《缓解交叉熵过度自信的一个简明方案》等。由于LLM的训练也可以理解为逐token的分类任务,默认损失也是交叉熵,因此这些改进工作在LLM流行的今天依然有一定的价值。
在这篇文章中,我们介绍一篇名为《EMO: Earth Mover Distance Optimization for Auto-Regressive Language Modeling》的工作,它基于最优传输思想提出了新的改进损失函数EMO,声称能大幅提高LLM的微调效果。其中细节如何?让我们一探究竟。
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 15478位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}

最近评论