






20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 83723位读者 |生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型 #
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
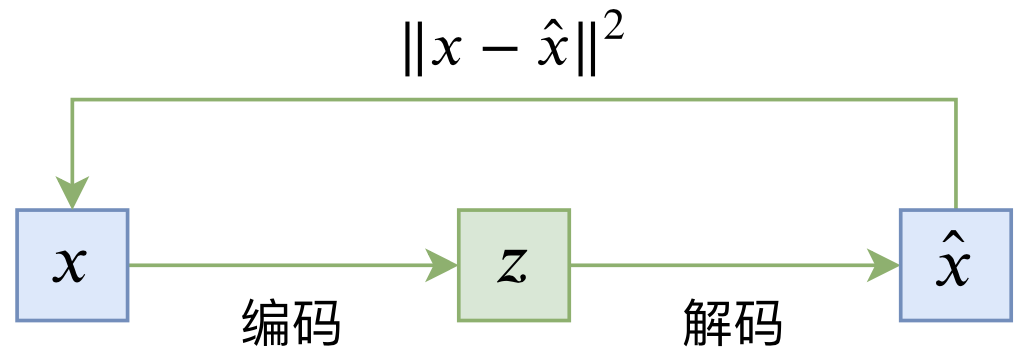
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
当训练完成后,我们自然可以针对每一幅图像$x$,得到它的编码$z=E(x)$以及重构图$\hat{x}=D(z)$,而当$x$与$\hat{x}$足够接近时,我们就可以认为$z$是$x$的有效表征,它已经充分包含了$x$的信息。
那么,生成模型又是什么情况呢?“生成”指的是随机生成,也就是说允许我们能随机构建一幅图像来,对于自编码器的解码器$D(z)$,并不是每一个$z$解码出来的$D(z)$都是一幅有意义的图像,因此普通的自编码器并不能视为生成模型。如果我们能够事先知道所有的$x$编码出来的$z=E(x)$所构成的分布,并且这个分布是一个易于采样分布,那么就可以实现随机采样生成了。
所以,从自编码器到生成模型,缺的那一步就是确定隐变量$z$的分布,更准确来说,是迫使隐变量$z$服从一个易于采样的简单分布,比如标准正态分布。VAE通过引入KL散度项来达到这一点,那么EAE又是怎么实现的呢?
正态分布与最大熵 #
我们知道,最大熵原理是一个相当普适的原理,它代表着我们对未知事件的最客观认知。最大熵原理的一个结论是:
在所有均值为0、方差为1的分布中,标准正态分布的熵最大。
如果读者还不了解最大熵的相关内容,可以参考旧作《“熵”不起:从熵、最大熵原理到最大熵模型(二)》。上述结论告诉我们,如果我们能有某种手段保证隐变量的均值为0和方差为1,那么我们只需要同时最大化隐变量的熵,就可以得到“隐变量服从标准正态分布”这个目的了,即
\begin{equation}\begin{aligned}&L_{EAE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2
\right] - \lambda H(Z)\\
&\text{s.t.}\,\,\text{avg}(E(x))=0,\,\text{std}(E(x))=1
\end{aligned}\end{equation}
其中$\lambda > 0$是超参数,而
\begin{equation}H(Z)=\mathbb{E}_{z\sim p(z)}[-\log p(z)]\end{equation}
是隐变量$z=E(x)$对应的熵,最小化$- \lambda H(Z)$意味着最大化$\lambda H(Z)$,即最大熵。
问题是如何保证这两个约束呢?如果计算隐变量的熵呢?
均值方差约束与BN #
先来解决第一个问题:如何达到——至少近似地达到——“隐变量的均值为0、方差为1”这个约束?因为只有满足这个约束的前提下,最大熵的分布才是标准正态的。解决这个问题的办法是我们熟悉的批归一化,也就是BN(Batch Normalization)。
在BN的训练阶段,我们会直接对每个变量减去其batch内的均值并且除以batch内标准差,这保证了训练阶段每个batch的变量均值确实为0,方差确实为1;然后,它会将每个batch内的均值方差滑动平均并缓存下来,用于推断阶段的预测。总而言之,就是将BN应用于隐变量,就可以使得隐变量(近似地)满足相应的均值方差约束。对了,要说明的是,本文说的BN层,不包括$\beta,\gamma$这两个可训练参数,如果在Keras中,则是要在初始化BN层时传入参数scale=False, center=False。
此时,我们就得到
\begin{equation}L_{EAE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(\mathcal{N}(E(x)))\right\Vert^2\right] - \lambda H(Z)\label{eq:eae}\end{equation}
这里的$\mathcal{N}(\cdot)$代表BN层。
熵的采样邻近估计 #
现在,来到了整个EAE模型的最后一部分、同时也是最硬核的一部分了,也就是如何估计熵$H(Z)$。理论上来说,为了算$H(Z)$我们需要知道$p(z)$,但我们现在只有样本$z_1, z_2, \dots, z_n$而不知道$p(z)$的表达式,在这种前提下对$H(Z)$做的估计叫做非参数估计。
先给结论:
熵的最邻近估计 设$z_1,z_2,\dots,z_n\in\mathbb{R}^d$是从$p(z)$采样出来的$n$个样本,记$\varepsilon(i)$为$z_i$到它最邻近的样本的距离,即$\varepsilon(i) = \min\limits_{j\neq i} \Vert z_i - z_j \Vert$,$B_d$是$d$维单位球的体积,$\gamma=0.5772\dots$是欧拉常数,则 \begin{equation}H(Z)\approx \frac{d}{n}\sum_{i=1}^n \log \varepsilon(i) + \log B_d + \log (n - 1) + \gamma \label{eq:1nn}\end{equation}
抛开跟优化不相关的常数,上述结论实际上就是说$H(Z)\sim \sum\limits_{i=1}^n \log \varepsilon(i)$,这就是我们需要添加到loss的项。
这个看上去很奇怪、实际上确实也不容易理解的结果是怎么得来的呢?事实上,它是一种重要的估计方法——$k$邻近方法——的经典例子。下面将会给出它的推导过程,该过程参考自论文《A non-parametric k-nearest neighbour entropy estimator》。
让我们考虑特定的样本$z_i$,设$z_{i(k)}$是它的第$k$个最邻近的样本,即将所有的$z_j (j\neq i)$按照$\Vert z_j - z_i\Vert$从小到大排列,第$k$个就是$z_{i(k)}$,记$\varepsilon_k(i) = \left\Vert z_i - z_{i(k)}\right\Vert$,我们现在考虑$\varepsilon_k(i)$的概率分布。
假设$\varepsilon \leq \varepsilon_k(i) \leq \varepsilon + d\varepsilon$,那么就意味着剩下的$n-1$个样本之中,有$k-1$个落在了“以$z_i$为球心、以$\varepsilon$为半径”的球内,有$n-k-1$个落在了“以$z_i$为球心、以$\varepsilon+d\varepsilon$为半径”的球外,剩下一个夹在两球之间,不难得到这种情况发生的概率是
\begin{equation}\binom{n-1}{1}\binom{n-2}{k-1}P_i(\varepsilon)^{k-1}(1 - P_i(\varepsilon + d\varepsilon))^{n-k-1}(P_i(\varepsilon + d\varepsilon) - P_i(\varepsilon))\label{eq:dp-1}\end{equation}
其中$\binom{n-1}{1}$代表着从$n-1$个样本中挑出$1$个样本夹在两球之间的组合数,而$\binom{n-2}{k-1}$则是从剩下的$n-2$个样本中挑出$k-1$个样本放到球内的组合数(剩下的$n-k-1$个自动就在球外了);$P_i(\varepsilon)$是单个样本位于球内的概率,即
\begin{equation}P_i(\varepsilon) = \int_{\Vert z - z_i\Vert \leq \varepsilon} p(z)dz\end{equation}
所以$P_i(\varepsilon)^{k-1}$是挑出来的$k-1$个样本都在球内的概率,$(1 - P_i(\varepsilon + d\varepsilon))^{n-k-1}$是$n-k-1$个样本都在球外的概率,$P_i(\varepsilon + d\varepsilon) - P_i(\varepsilon)$则是一个样本在球间的概率,所有项乘起来就是式$\eqref{eq:dp-1}$,而展开并只保留一阶项得到近似式:
\begin{equation}\binom{n-1}{1}\binom{n-2}{k-1}P_i(\varepsilon)^{k-1}(1 - P_i(\varepsilon))^{n-k-1}dP_i(\varepsilon)\label{eq:dp-2}\end{equation}
注意上式描述了一个合理的概率分布,因此它的积分必然为1。现在我们可以做个近似假设,值得注意的是,这是整个推导过程的唯一假设,而最终结果的可靠程度也取决于这个假设的成立程度:
\begin{equation}p(z_i) \approx \frac{1}{B_d \varepsilon_k(i)^d}\int_{\Vert z - z_i\Vert \leq \varepsilon} p(z)dz = \frac{P_i(\varepsilon)}{B_d \varepsilon_k(i)^d}\end{equation}
其中$B_d \varepsilon_k(i)^d$就是半径为$\varepsilon_k(i)$的球的体积。根据这个近似我们有$p(z_i) B_d \varepsilon_k(i)^d \approx P_i(\varepsilon)$,看上去不合理,因为左端相当于一个常数,右端则是关于$\varepsilon$的函数,两者怎么能一直保持近似?事实上,当$n$足够大的时候,采样出来的样本足够稠密,这时候$\varepsilon$会集中在一个比较小的范围内,而$\varepsilon_k(i)$是$\varepsilon$某次采样的值,所以我们可以认为$\varepsilon$会集中在$\varepsilon_k(i)$附近。虽然$P_i(\varepsilon)$关于$\varepsilon$是变化的,但下面我们还要对$\varepsilon$进行积分,所以我们只需要在$\varepsilon_k(i)$附近对$P_i(\varepsilon)$做好近似进行,不需要整体都可以很好地近似(即$\varepsilon \gg \varepsilon_k(i)$时,$\eqref{eq:dp-2}$几乎为0)。而在$\varepsilon_k(i)$附近我们可以认为概率变化是平缓的,所以$p(z_i) B_d \varepsilon_k(i)^d \approx P_i(\varepsilon)$。现在我们可以写出
\begin{equation}\log p(z_i) \approx \log P_i(\varepsilon) - \log B_d - d \log \varepsilon_k(i) \end{equation}
用$\eqref{eq:dp-2}$乘以上式两端,并对$\varepsilon$积分(积分区间为$[0,+\infty)$,或者等价于对$P_i$在$[0,1]$积分)。除$\log P_i(\varepsilon)$外,其余几项都是跟$\varepsilon$无关,所以积分后依然等于自身,而
\begin{equation}\begin{aligned}&\int_0^1 \binom{n-1}{1}\binom{n-2}{k-1}P_i(\varepsilon)^{k-1}(1 - P_i(\varepsilon))^{n-k-1} \log P_i(\varepsilon) d P_i(\varepsilon) \\
=&\psi(k)-\psi(n)\end{aligned}\end{equation}
其中$\psi$代表着双伽马函数。(别问我这些积分是怎么算出来的,我也不知道,但我知道用Mathematica软件能把它都算出来~)于是我们得到近似
\begin{equation}\log p(z_i) \approx \psi(k)-\psi(n) - \log B_d - d \log \varepsilon_k(i) \end{equation}
所以最终熵的近似为:
\begin{equation}\begin{aligned}H(Z)=&\, \mathbb{E}_{z\sim p(z)}[-\log p(z)]\\
\approx&\, -\frac{1}{n}\sum_{i=1}^n \log p(z_i)\\
\approx&\, \frac{d}{n}\sum_{i=1}^n \log \varepsilon_k(i) + \log B_d + \psi(n)-\psi(k)
\end{aligned}\label{eq:knn}\end{equation}
这是比式$\eqref{eq:1nn}$更一般的结果。事实上式$\eqref{eq:1nn}$是上式$k=1$时的特例,因为$\psi(1)=-\gamma$,而$\psi(n)= \sum\limits_{m=1}^{n-1}\frac{1}{m}-\gamma\approx \log(n-1)$,这些变换公式都可以在维基百科上找到。开头就已经提到过,$k$邻近方法是一种很有用的非参数估计方法,它还跟笔者之前介绍过的IMLE模型有关。但笔者本身也不熟悉$k$邻近方法,还需要多多学习,目前找到的资料是《Lectures on the Nearest Neighbor Method》。此外,关于熵的估计,还可以参考斯坦福的资料《Theory and Practice of Differential Entropy Estimation》。
进一步思考与分析 #
有了$\eqref{eq:1nn}$或$\eqref{eq:knn}$,式$\eqref{eq:eae}$所描述的EAE的loss就完成了,所以EAE模型也就介绍完毕了。剩下的是实验结果,就不详细介绍了,反正就是感觉生成的图像跟VAE差不多,但指标上更优一些。
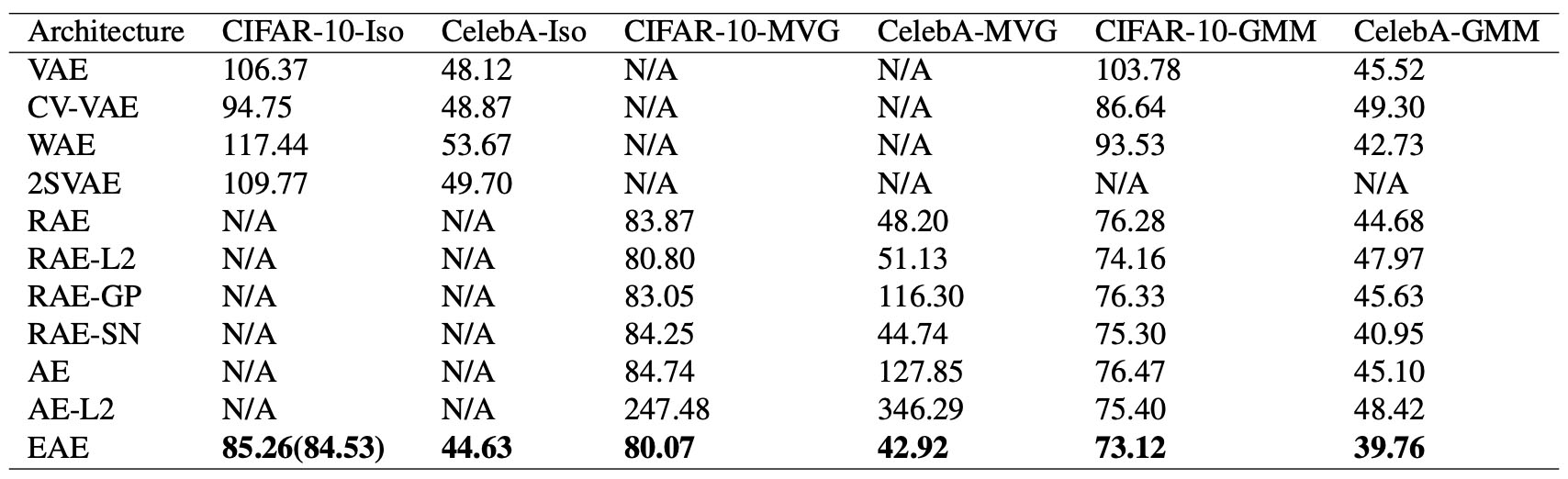
来自EAE论文的实验对比

来自EAE论文的效果图示
那EAE相比VAE的好处在哪呢?在VAE中,比较关键的一步是重参数(可以参考笔者的《变分自编码器(一):原来是这么一回事》),就是这一步降低了模型训练的方差(相比REINFORCE方差更小,可以参考笔者的《漫谈重参数:从正态分布到Gumbel Softmax》),从而使得VAE可以有效地训练下去。然而,虽然重参数降低了方差,但事实上方差依然不小,简单来说就是重参数这一步带来较大的噪声(尤其是训练早期),导致decoder无法很好地利用encoder的信息,典型的例子就是将VAE用在NLP时的“KL散度消失”现象。
但是EAE基本上不存在这个问题,因为EAE基本上就是普通的自编码器,多加的BN不会对自编码性能有什么影响,而多加的熵正则项原则上也只是增加隐变量的多样性,不会给编码信息的利用与重构带来明显困难。笔者认为,这就是EAE相对于VAE的优势所在。当然,笔者目前还没有对EAE进行太多实验,上述分析多为主观推断,请读者自行甄别。如果笔者有进一步的实验结论,到时会继续在博客与大家分享。
最后补上一个小结 #
本文介绍了一个称之为EAE的模型,主要是把BN层和最大熵塞进了普通的自编码器中,使得它具有生成模型的能力。原论文做的不少实验显示EAE比VAE效果更好,所以应该是一个值得学习和试用的模型。此外,EAE的关键部分是通过$k$邻近方法来估计熵,这部分比较硬核,但事实上也很有价值,值得对统计估计感兴趣的读者细细阅读。
转载到请包括本文地址:https://spaces.ac.cn/archives/7343
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 20, 2020). 《EAE:自编码器 + BN + 最大熵 = 生成模型 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7343
@online{kexuefm-7343,
title={EAE:自编码器 + BN + 最大熵 = 生成模型},
author={苏剑林},
year={2020},
month={Apr},
url={\url{https://spaces.ac.cn/archives/7343}},
}

October 1st, 2021
苏神,EAE的loss中加入的熵正则项在代码层面怎么实现啊?
就直接按照公式实现呀,哪部分有难度呢?
November 19th, 2021
直接使用KL散度不也可以实现“隐变量的均值为0、方差为1”这个约束?为什么还要用BN的方式?
如何实现?这里要求的是显式约束。
我想的是像VAE那样直接用KL将后验约束到先验正态上面去,不过貌似这里是用另一种更复杂的手段实现这件事情?
KL项那叫做惩罚项,不叫做约束,约束是指天然满足的,比如向量$\boldsymbol{u}=\boldsymbol{x}/\Vert \boldsymbol{x}\Vert$天然满足$\Vert \boldsymbol{u}\Vert=1$。
好的,感谢回答!不过不管它叫什么,KL起到的作用总是将“后验约束到正态”上面吧?
1、这不是“叫什么”的问题,这是“对与错”、“是与否”的问题,EAE要做的是带约束优化,不是带惩罚优化,这两个不能互相替换;
2、单独的KL没什么作用,它只是与重构项构成VAE的loss,没有重构项它什么也不是。
November 7th, 2022
苏老师好,想问一下,式子(5)里的d是什么的维度呢,和什么参数有关吗还是说随便定一个?
$d$就是你本身的数据维度啊,已经说得很清楚了,$z_1,z_2,\dots,z_n\in\mathbb{R}^d$。
我在vae的网络基础上改了一下,效果很差,甚至没有还原训练集的能力,也找不到eae相关代码 T_T ,这篇论文我找不到相关参考代码,苏老师有复现结果吗
我没复现过。你可以尝试先将最大熵的正则项设为零,看看能不能正常重构,然后慢慢增大权重。
感谢苏老师,实验结果问题主要出现在bn层上,不加最大熵和bn层就是最基础的Autoencoder,这个重构是没问题的,但是将bn层加在z上后,AE也不能重构了,苏老师有什么建议吗,是我bn层加的不对吗
大概率是你BN加得不对吧。EAE我没实现过,但是我实验过 https://kexue.fm/archives/7381 的方法,它也是加了BN,并且保留了正则项,在这种情况下,模型(就是一个VAE)都能完成重构,更不用说AE了。单纯加上BN,基本来说对重构是更有利的。
谢谢苏老师耐心解答,成功复现了,重构结果还可以,不过对其latent随机生成(randn)后直接decoder测试,EAE的生成能力就远不如VAE了
非主流模型,可能对训练细节的要求很高吧~
January 16th, 2023
苏神我想我问一下,有H(z)的表达了,为什么不直接进行采样计算,而需要用熵的采样临近估计呢
哪里有$H(z)$的表达式?
他可能是说(3)式得到的概率分布可以用采样的方法近似p(x)来求吗
December 26th, 2023
苏神,有个小疑问,BN 后的 z 不是已经是接近正态分布了吗
BN是稍微向标准正态分布靠近了一点,但离标准正态分布还差得远。