






13
Nov
【生活杂记】炒锅的尽头是铁锅
By 苏剑林 | 2023-11-13 | 53718位读者 | 引用
铁锅(网络图)
很多会下厨的同学估计都纠结过一件事情,那就是炒锅的选择。
对于炒锅的纠结,归根结底是不粘与方便的权衡。最简单的不粘锅自然是带涂层的不粘锅,如果家里的热源只有电磁炉,并且炒菜习惯比较温和,那么涂层不粘锅往往是最佳选择了。不过,一旦有了明火的燃气灶,又或者是比较喜欢爆炒,那么涂层锅可能就不是那么适合了,毕竟温度过高涂层总有脱落的风险,此时一般就考虑无涂层不粘锅。
无涂层不粘锅也有五花八门的选择,比如朴素的铁锅、带蜂窝纹的不锈钢锅、有钛锅、纯钛锅等等,价格大体上也单调递增。不过用到最后,我觉得大部分人都会回归到朴素的铁锅。
17
Jul
【生活杂记】用电饭锅来煮米汤
By 苏剑林 | 2024-07-17 | 14035位读者 | 引用
29
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(二)
By 苏剑林 | 2024-07-29 | 20967位读者 | 引用前两周笔者写了《对齐全量微调!这是我看过最精彩的LoRA(一)》(当时还没有编号“一”),里边介绍了一个名为“LoRA-GA”的LoRA变体,它通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的$W_1$,所以当时就有读者提出了“后面的$W_2,W_3,\cdots$不管了吗?”的疑问,当时笔者也没想太深入,就单纯觉得对齐了第一步后,后面的优化也会严格一条较优的轨迹走。
有趣的是,LoRA-GA才出来没多久,arXiv上就新出了《LoRA-Pro: Are Low-Rank Adapters Properly Optimized?》,其所提的LoRA-Pro正好能回答这个问题!LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
本文接着上一篇文章的记号和内容进行讲述,所以这里仅对上一节的内容做一个简单回顾,不再详细重复介绍。LoRA的参数化方式是
\begin{equation}W = (W_0 - A_0 B_0) + AB\end{equation}
5
Aug
两道无穷级数:自然数及其平方的倒数和
By 苏剑林 | 2009-08-05 | 60641位读者 | 引用
16
Oct
以自然数幂为系数的幂级数
By 苏剑林 | 2010-10-16 | 31157位读者 | 引用$\sum_{i=0}^{\infty} a_i x^i=a_0+a_1 x+a_2 x^2+a_3 x^3+...$
最近为了数学竞赛,我研究了有关数列和排列组合的相关问题。由于我讨厌为某个问题而设计专门的技巧,所以我偏爱通用的方法,哪怕过程相对麻烦。因此,我对数学归纳法(递推法)和生成函数法情有独钟。前者只需要列出问题的递归关系,而不用具体分析,最终把问题转移到解函数方程上来。后者则巧妙地把数列${a_n}$与幂级数$\sum_{i=0}^{\infty} a_i x^i$一一对应,巧妙地通过代数运算或微积分运算等得到结果。这里我们不用考虑该级数的敛散性,只需要知道它对应着哪一个“母函数”(母函数展开泰勒级数后得到了级数$\sum_{i=0}^{\infty} a_i x^i$)。显然,这两种方法的最终,都是把问题归结为代数问题。
28
Nov
《自然极值》系列——4.费马点问题
By 苏剑林 | 2010-11-28 | 85798位读者 | 引用通过上面众多的文字描述,也许你还不大了解这两个原理有何美妙之处,也或者你已经迫不及待地想去应用它们却不知思路。为了不至于让大家产生“审美疲劳”,接下来我们将试图利用这两个原理对费马点问题进行探讨,看看原理究竟是怎么发挥作用的。运用的关键在于:如何通过适当的变换将其与光学或势能联系起来。
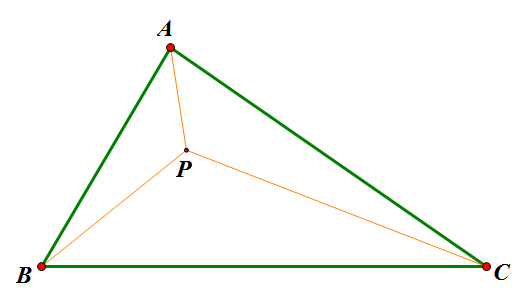
费马点问题
传统费马点问题是指在ΔABC中寻找点P,使得$AP+BP+CP$最小的问题;而广义的费马点则改成使$k_1 AP+k_2 BP+k_3 CP$最小。这是很具有现实意义的,是“在三个村庄之间建立一个中转站,如何才能使运送成为最低”之类的最优问题。我们将从光学和势能两个角度对这个问题进行探讨(也许有的读者已经阅读过了利用重力的原理来求解费马点,但是我想光学的方法依然会是你眼前一亮的。)
10
Dec
《自然极值》系列——6.最速降线的解答
By 苏剑林 | 2010-12-10 | 61478位读者 | 引用通过上一小节的小故事,我们已经能够基本了解最速降线的内容了,它就是要我们求出满足某一极值条件的一个未知函数,由于函数是未知的,因此这类问题被称为“泛分析”。其中还谈到,伯努利利用费马原理巧妙地得出了答案,那么我们现在就再次回顾历史,追寻伯努利的答案,并且寻找进一步的应用。
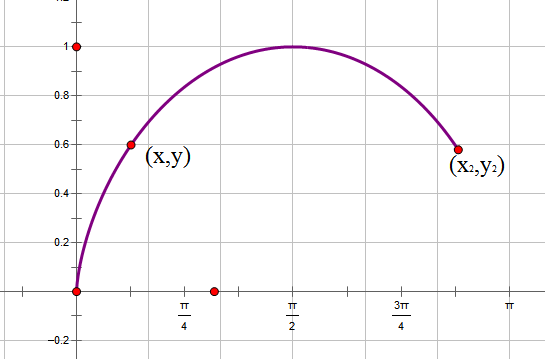
最速降线-1
为了计算方便,我们把最速降线倒过来,把初始点设置在原点。在下落过程中,重力势能转化为动能,因此,在点(x,y)处有$\frac{1}{2} mv^2=mgy\Rightarrow v=\sqrt{2gy}$,由于纯粹为了探讨曲线形状,所以我们使g=0.5,即$v=\sqrt{y}$。在点(x,y)处所走的路程为$ds=\sqrt{dy^2+dx^2}=\sqrt{\dot{y}^2+1}dx$,所以时间为$dt=\frac{ds}{v}=\frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$,于是最速降线问题就是求使$t=\int_0^{x_2} \frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$最小的函数。
3
Mar
指数梯度下降 + 元学习 = 自适应学习率
By 苏剑林 | 2022-03-03 | 29151位读者 | 引用前两天刷到了Google的一篇论文《Step-size Adaptation Using Exponentiated Gradient Updates》,在其中学到了一些新的概念,所以在此记录分享一下。主要的内容有两个,一是非负优化的指数梯度下降,二是基于元学习思想的学习率调整算法,两者都颇有意思,有兴趣的读者也可以了解一下。
指数梯度下降
梯度下降大家可能听说得多了,指的是对于无约束函数$\mathcal{L}(\boldsymbol{\theta})$的最小化,我们用如下格式进行更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\end{equation}
其中$\eta$是学习率。然而很多任务并非总是无约束的,对于最简单的非负约束,我们可以改为如下格式更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t \odot \exp\left(- \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\right)\label{eq:egd}\end{equation}
这里的$\odot$是逐位对应相乘(Hadamard积)。容易看到,只要初始化的$\boldsymbol{\theta}_0$是非负的,那么在整个更新过程中$\boldsymbol{\theta}_t$都会保持非负,这就是用于非负约束优化的“指数梯度下降”。

最近评论