






3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 87058位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
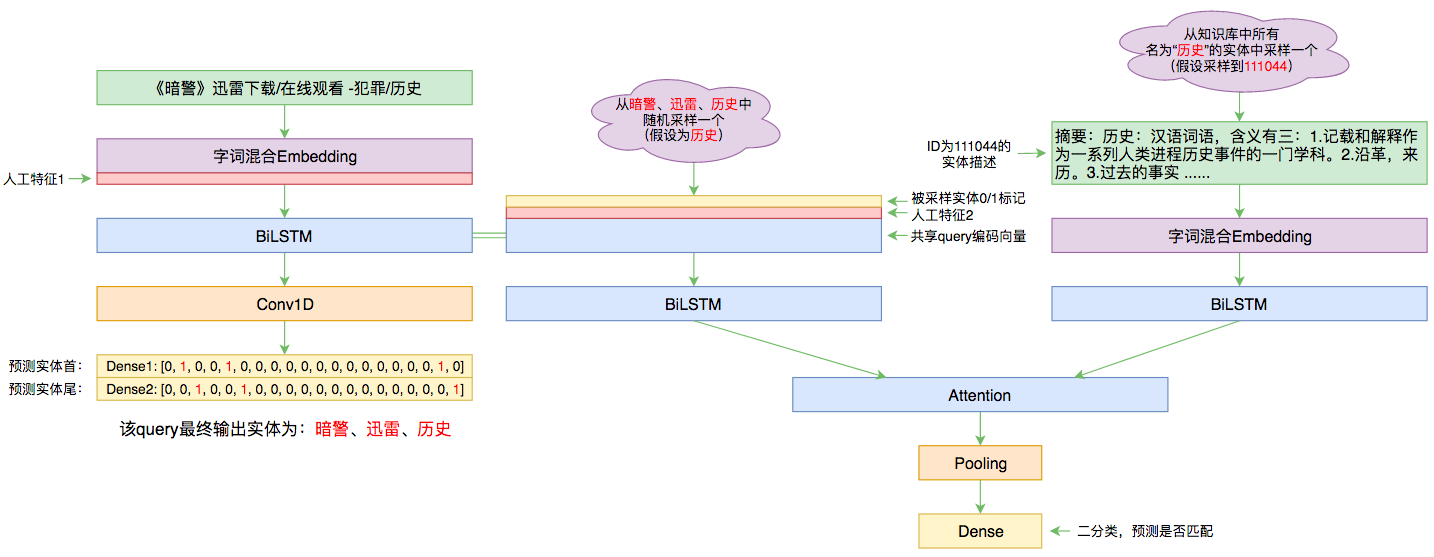
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 208408位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
28
Feb
生成扩散模型漫谈(十八):得分匹配 = 条件得分匹配
By 苏剑林 | 2023-02-28 | 30034位读者 | 引用在前面的介绍中,我们多次提及“得分匹配”和“条件得分匹配”,它们是扩散模型、能量模型等经常出现的概念,特别是很多文章直接说扩散模型的训练目标是“得分匹配”,但事实上当前主流的扩散模型如DDPM的训练目标是“条件得分匹配”才对。
那么“得分匹配”与“条件得分匹配”具体是什么关系呢?它们两者是否等价呢?本文详细讨论这个问题。
得分匹配
首先,得分匹配(Score Matching)是指训练目标:
\begin{equation}\mathbb{E}_{\boldsymbol{x}_t\sim p_t(\boldsymbol{x}_t)}\left[\left\Vert\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t) - \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t,t)\right\Vert^2\right]\label{eq:sm}\end{equation}
其中$\boldsymbol{\theta}$是训练参数。很明显,得分匹配是想学习一个模型$\boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t,t)$来逼近$\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t)$,这里的$\nabla_{\boldsymbol{x}_t}\log p_t(\boldsymbol{x}_t)$我们就称为“得分”。
14
Jul
当生成模型肆虐:互联网将有“疯牛病”之忧?
By 苏剑林 | 2023-07-14 | 50944位读者 | 引用众所周知,不管是文本还是视觉领域,各种生成模型正在以无法阻挡的势头“肆虐”互联网。虽然大家都明白,实现真正的通用人工智能(AGI)还有很长的路要走,但这并不妨碍人们越来越频繁地利用生成模型来创作和分享内容。君不见,很多网络文章已经配上了Stable Diffusion模型生成的插图;君不见,很多新闻风格已经越来越显现出ChatGPT的影子。看似无害的这种趋势,正悄然引发了一个问题:我们是否应该对互联网上充斥的生成模型数据保持警惕?
近期发表的论文《Self-Consuming Generative Models Go MAD》揭示了一种令人担忧的可能性,那就是生成模型正在互联网上的无节制扩张,可能会导致一场数字版的“疯牛病”疫情。本文一起学习这篇论文,探讨其可能带来的影响。
20
Nov
Transformer升级之路:15、Key归一化助力长度外推
By 苏剑林 | 2023-11-20 | 54789位读者 | 引用大体上,我们可以将目前Transformer的长度外推技术分为两类:一类是事后修改,比如NTK-RoPE、YaRN、ReRoPE等,这类方法的特点是直接修改推理模型,无需微调就能达到一定的长度外推效果,但缺点是它们都无法保持模型在训练长度内的恒等性;另一类自然是事前修改,如ALIBI、KERPLE、XPOS以及HWFA等,它们可以不加改动地实现一定的长度外推,但相应的改动需要在训练之前就引入,因此无法不微调地用于现成模型,并且这类方法是否能够Scale Up还没得到广泛认可。
在这篇文章中,笔者将介绍一种意外发现的长度外推方案——“KeyNorm”——对Attention的Key序列做L2 Normalization,很明显它属于事前修改一类,但对Attention机制的修改非常小,因此看上去非常有希望能够Scale Up。
最初动机
之所以说“意外发现”,是因为该改动的原始动机并不是长度外推,而是尝试替换Scaled Dot-Product Attention中的Scale方式。我们知道,Attention的标准定义是(本文主要考虑Causal场景)
\begin{equation}\boldsymbol{o}_i = \frac{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)\boldsymbol{v}_j}{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)},\quad \boldsymbol{q}_i,\boldsymbol{k}_j\in\mathbb{R}^d\label{eq:sdpa}\end{equation}
6
Apr
2010年4月全球天文月(One People,One Sky)
By 苏剑林 | 2010-04-06 | 79664位读者 | 引用
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 39488位读者 | 引用
12
Sep
微积分学习(二):导数
By 苏剑林 | 2009-09-12 | 20641位读者 | 引用自从上次写了关于微积分中的极限学习后,就很长的时间没有与大家探讨微积分的学习了(估计有20多天了吧)。启事,我自己也是从今年的9月下旬才开始系统地学习微积分的,到现在也就一个月的时间吧。学习的内容有:集合、函数、极限、导数、微分、积分。不过都是一元微积分,多元的微积分正在紧张地进修中......
现在不妨和大家探讨一下关于微积分中的最基本内容——“导数”的学习。
其实,用最简单的说法,如果存在函数$f(x)$,那么它的导数(一阶导数)为
$$\lim_{\Delta x->0} f'(x)=\frac{f(x+\Delta x)-f(x)}{\Delta x}$$

最近评论