






20
Jun
重温SSM(三):HiPPO的高效计算(S4)
By 苏剑林 | 2024-06-20 | 28063位读者 | 引用前面我们用两篇文章《重温SSM(一):线性系统和HiPPO矩阵》和《重温SSM(二):HiPPO的一些遗留问题》介绍了HiPPO的思想和推导——通过正交函数基对持续更新的函数进行实时逼近,其拟合系数的动力学正好可以表示为一个线性ODE系统,并且对于特定的基底以及逼近方式,我们可以将线性系统的关键矩阵精确地算出来。此外,我们还讨论了HiPPO的离散化和相关性质等问题,这些内容奠定了后续的SSM工作的理论基础。
接下来,我们将介绍HiPPO的后续应用篇《Efficiently Modeling Long Sequences with Structured State Spaces》(简称S4),它利用HiPPO的推导结果作为序列建模的基本工具,并从新的视角探讨了高效的计算和训练方式,最后在不少长序列建模任务上验证了它的有效性,可谓SSM乃至RNN复兴的代表作之一。
基本框架
S4使用的序列建模框架,是如下的线性ODE系统:
\begin{equation}\begin{aligned}
x'(t) =&\, A x(t) + B u(t) \\
y(t) =&\, C^* x(t) + D u(t)
\end{aligned}\end{equation}
29
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(二)
By 苏剑林 | 2024-07-29 | 24273位读者 | 引用前两周笔者写了《对齐全量微调!这是我看过最精彩的LoRA(一)》(当时还没有编号“一”),里边介绍了一个名为“LoRA-GA”的LoRA变体,它通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的$W_1$,所以当时就有读者提出了“后面的$W_2,W_3,\cdots$不管了吗?”的疑问,当时笔者也没想太深入,就单纯觉得对齐了第一步后,后面的优化也会严格一条较优的轨迹走。
有趣的是,LoRA-GA才出来没多久,arXiv上就新出了《LoRA-Pro: Are Low-Rank Adapters Properly Optimized?》,其所提的LoRA-Pro正好能回答这个问题!LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
本文接着上一篇文章的记号和内容进行讲述,所以这里仅对上一节的内容做一个简单回顾,不再详细重复介绍。LoRA的参数化方式是
\begin{equation}W = (W_0 - A_0 B_0) + AB\end{equation}
18
Nov
Adam的epsilon如何影响学习率的Scaling Law?
By 苏剑林 | 2024-11-18 | 12902位读者 | 引用上一篇文章《当Batch Size增大时,学习率该如何随之变化?》我们从多个角度讨论了学习率与Batch Size之间的缩放规律,其中对于Adam优化器我们采用了SignSGD近似,这是分析Adam优化器常用的手段。那么一个很自然的问题就是:用SignSGD来近似Adam究竟有多科学呢?
我们知道,Adam优化器的更新量分母会带有一个$\epsilon$,初衷是预防除零错误,所以其值通常很接近于零,以至于我们做理论分析的时候通常选择忽略掉它。然而,当前LLM的训练尤其是低精度训练,我们往往会选择偏大的$\epsilon$,这导致在训练的中、后期$\epsilon$往往已经超过梯度平方大小,所以$\epsilon$的存在事实上已经不可忽略。
因此,这篇文章我们试图探索$\epsilon$如何影响Adam的学习率与Batch Size的Scaling Law,为相关问题提供一个参考的计算方案。
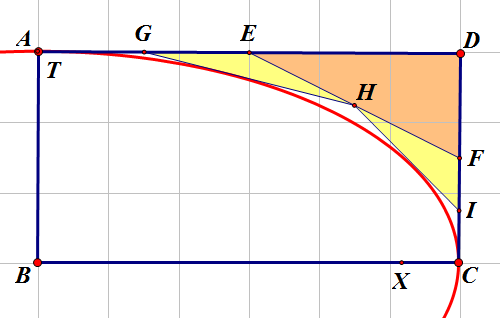
8
Apr
2^29363731-1不是素数!
By 苏剑林 | 2013-04-08 | 23554位读者 | 引用
2^29363731-1
很小的时候就开始对素数感兴趣了,后来是在一本《未解之谜》上看到了梅森素数、完全数、孪生素数等等东西,觉得甚是好玩。在初中买了计算机之后,就关注到了Prime 95这个梅森素数的分布式计算程序,以前也尝试过运行它,不过由于那时候计算机配置较低,一般都是运行到20%左右就没有坚持下去了。
上大学入手了一台四核的笔记本,就在去年10月份左右再次运行了这个程序,由于是四核,一次性可以同时测试四个数字。经过半年的运行,今天终于测试完了第一个数字:$2^{29363731}-1$。正如预料中的,这不是一个素数。不管怎样,它是我第一个完成的测试,也算是自己的一个独立的成果啦,呵呵,自娱自乐一番。
4
Jun
当概率遇上复变:随机游走与路径积分
By 苏剑林 | 2014-06-04 | 23818位读者 | 引用我们在上一篇文章中已经看到,随机游走的概率分布是正态的,而在概率论中可以了解到正态分布(几乎)是最重要的一种分布了。随机游走模型和正态分布的应用都很广,我们或许可以思考一个问题,究竟是随机游走造就了正态分布,还是正态分布造就了随机游走?换句话说,哪个更本质些?个人就自己目前所阅读到的内容来看,随机游走更本质些,随机游走正好对应着普遍存在的随机不确定性(比如每次测量的误差),它的分布正好就是正态分布,所以正态分布才应用得如此广泛——因为随机不确定性无处不在。
下面我们来考虑随机游走的另外一种描述方式,原则上来说,它更广泛,更深刻,其大名曰“路径积分”。
9
Jun
路径积分系列:5.例子和综述
By 苏剑林 | 2016-06-09 | 22727位读者 | 引用路径积分方法为解决某些随机问题带来了新视角.
一个例子:股票价格模型
考虑有风险资产(如股票),在$t$时刻其价格为$S_t$,考虑的时间区间为$[0,T]$,0表示初始时间,$T$表示为到期日. $S_t$看作是随时间变化的连续时间变量,并服从下列随机微分方程:
$$dS_t^0=rS_t^0 dt;\quad dS_t=S_t(\mu dt+\sigma dW_t).\tag{70}$$
其中,$\mu$和$\sigma$是两个常量,$W_t$是一个标准布朗运动.
关于$S_t$的方程是一个随机微分方程,一般解决思路是通过随机微积分. 随机微积分有别于一般的微积分的地方在于,随机微积分在做一阶展开的时候,不能忽略$dS_t^2$项,因为$dW_t^2=dt$. 比如,设$S_t=e^{x_t}$,则$x_t=\ln S_t$
$$\begin{aligned}dx_t=&\ln(S_t+dS_t)-\ln S_t=\frac{dS_t}{S_t}-\frac{dS_t^2}{2S_t^2}\\
=&\frac{S_t(\mu dt+\sigma dW_t)}{S_t}-\frac{[S_t(\mu dt+\sigma dW_t)]^2}{2S_t^2}\\
=&\mu dt+\sigma dW_t-\frac{1}{2}\sigma^2 dW_t^2\quad(\text{其余项均低于}dt\text{阶})\\
=&\left(\mu-\frac{1}{2}\sigma^2\right) dt+\sigma dW_t\end{aligned}
,\tag{71}$$
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 154045位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
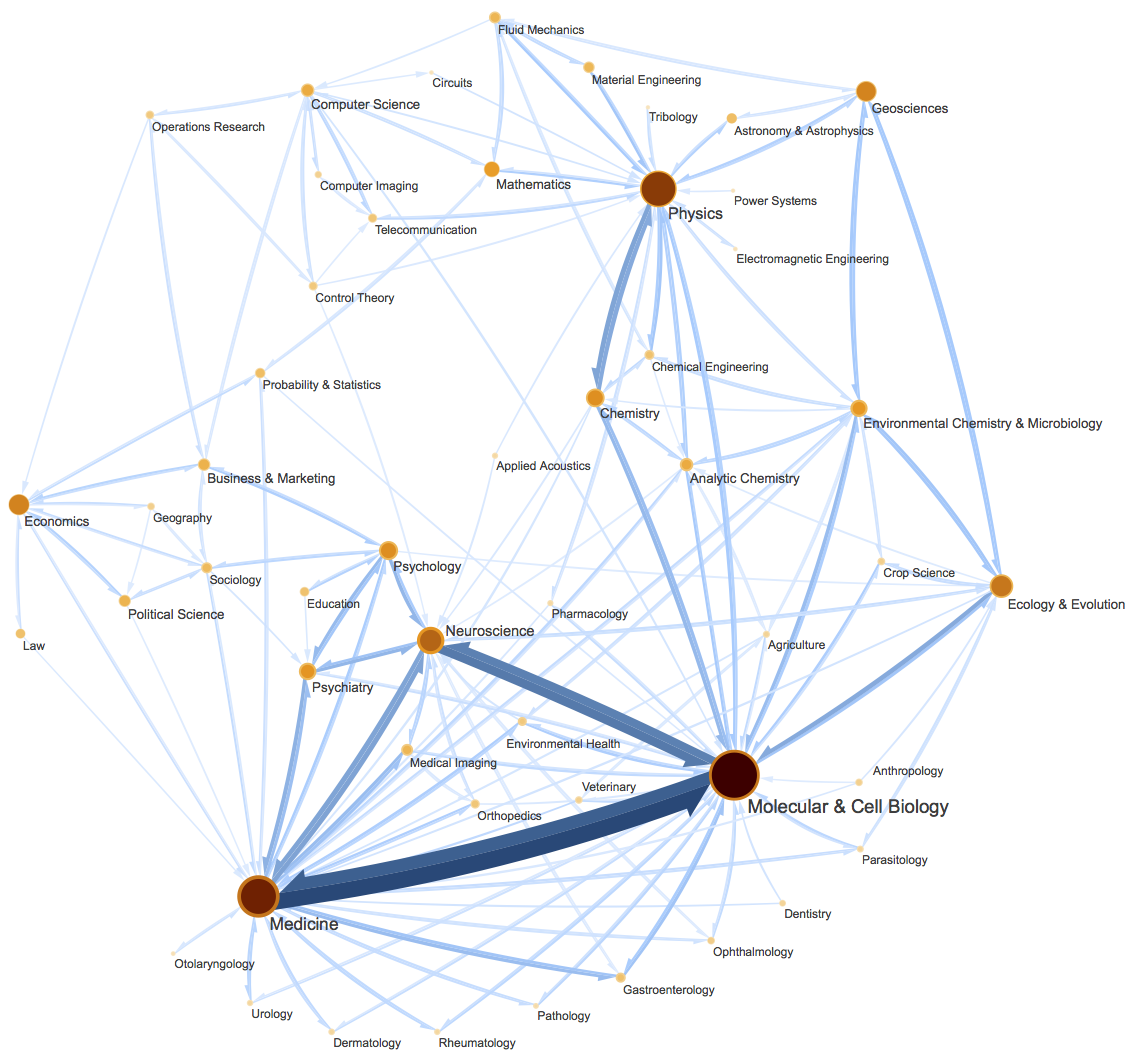
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)

最近评论