






8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 67660位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。
16
Jul
“让Keras更酷一些!”:层中层与mask
By 苏剑林 | 2019-07-16 | 125093位读者 | 引用这一篇“让Keras更酷一些!”将和读者分享两部分内容:第一部分是“层中层”,顾名思义,是在Keras中自定义层的时候,重用已有的层,这将大大减少自定义层的代码量;另外一部分就是应读者所求,介绍一下序列模型中的mask原理和方法。
层中层
在《“让Keras更酷一些!”:精巧的层与花式的回调》一文中我们已经介绍过Keras自定义层的基本方法,其核心步骤是定义build和call两个函数,其中build负责创建可训练的权重,而call则定义具体的运算。
拒绝重复劳动
经常用到自定义层的读者可能会感觉到,在自定义层的时候我们经常在重复劳动,比如我们想要增加一个线性变换,那就要在build中增加一个kernel和bias变量(还要自定义变量的初始化、正则化等),然后在call里边用K.dot来执行,有时候还需要考虑维度对齐的问题,步骤比较繁琐。但事实上,一个线性变换其实就是一个不加激活函数的Dense层罢了,如果在自定义层时能重用已有的层,那显然就可以大大节省代码量了。
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 40772位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 70732位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
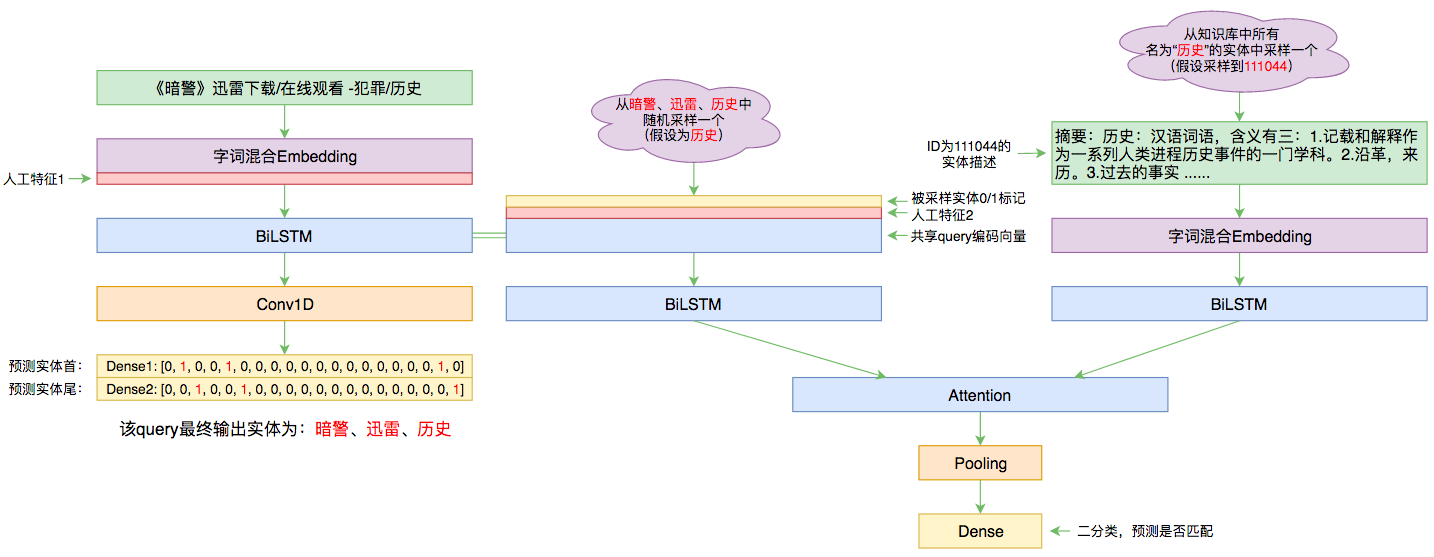
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 187023位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 69555位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 85361位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 75267位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。

最近评论