






14
Jul
澳洲恐龙洞穴揭示气候变化
By 苏剑林 | 2009-07-14 | 23568位读者 | 引用
14
Dec
端到端的腾讯验证码识别(46%正确率)
By 苏剑林 | 2016-12-14 | 66953位读者 | 引用最新结果请参考:http://kexue.fm/archives/4503/
前段时间有幸得到了一个网友提供的一批带标签的腾讯验证码样本(验证码样板:http://captcha.qq.com/getimage),于是抽了点时间,测试了一下验证码识别的模型。

腾讯验证码
样本
这批验证码比较简单,4位的英文字母,有大小写,但输入的时候不区分大小写,图案有一定的混淆,传统的基于分割的方案估计比较难办。端到端的方案是,直接将验证码输入,做几个卷积层,然后连接几个分类器(26分类),然后就直接输出四个字母标签了。其实还真没有什么好说的,有样本就能做了,而且这个框架是通用的,可以用到区分大小写的情形(52分类),也可以用到英文数字混合的情形(再加10个类别而已)。
13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 52419位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 102125位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 28001位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 176999位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
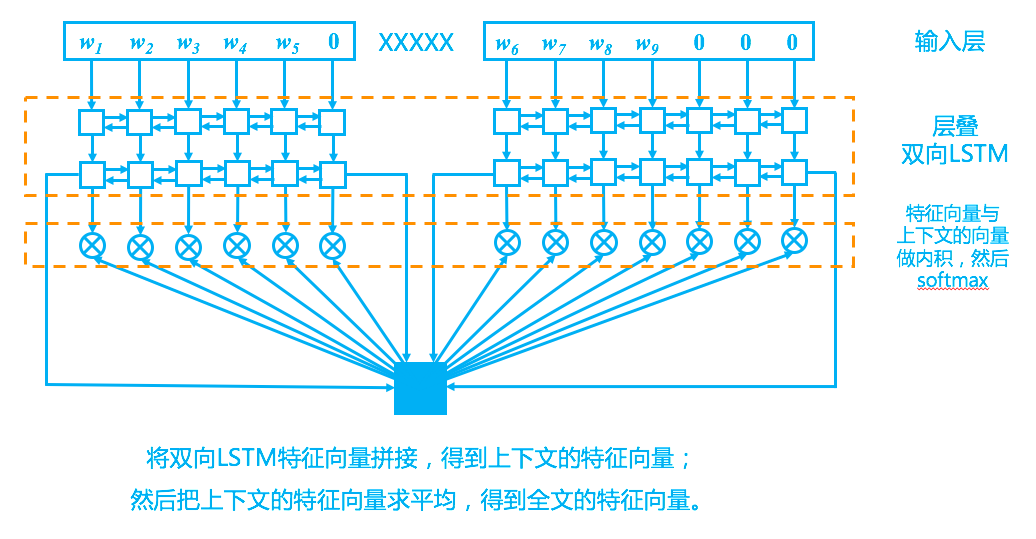
完形填空模型
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 375018位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
13
Oct
基于fine tune的图像分类(百度分狗竞赛)
By 苏剑林 | 2017-10-13 | 24796位读者 | 引用
baidu_jingsai
前两年百度的大数据竞赛都是自然语言处理方面的,今年画风一转,变成了图像的细颗粒度分类,赛题内容就是将宠物狗归为100类中的其中一类。这个任务本身是很平凡的,做法也很常规,无外乎就是数据扩增、imagenet模型的fine tune、模型集成三个方面。笔者并不擅长于模型集成,只做了前面两个步骤,成绩也非常一般(准确率80%上下)。但感觉里边的某些代码可能对读者有帮助,遂共享一翻。下面结合着代码来讲解。
比赛官网(随时有失效的可能):http://js.baidu.com
模型
模型主要用tensorflow+keras实现。首先自然是导入各种模块
#! -*- coding:utf-8 -*-
import numpy as np
from scipy import misc
import tensorflow as tf
from keras.applications.xception import Xception,preprocess_input
from keras.layers import Input,Dense,Lambda,Embedding
from keras.layers.merge import multiply
from keras import backend as K
from keras.models import Model
from keras.optimizers import SGD
from tqdm import tqdm
import glob
np.random.seed(2017)
tf.set_random_seed(2017)

最近评论