






25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 188266位读者 |机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
先看效果 #
输入篇章:世界第二高山峰是乔戈里峰,位于中国境内。
生成问答:世界第二高山峰叫什么名字? 乔戈里峰
乔戈利峰是世界第几高峰 第二输入篇章:7月28日,泰国将迎来十世王玛哈·哇集拉隆功国王的68岁诞辰。
生成问答:泰国的十世王是谁 玛哈·哇集拉隆功国王
泰国的十世王玛哈·哇集拉隆多少岁? 68岁
泰国的玛哈·哇集拉隆功国王的生日是哪一天? 7月28日
玛哈·哇集拉隆功国王是哪个国家的 泰国输入篇章:泼水节,亦称宋干节,已有700年的历史,是傣族(中国)、德昂族最盛大的传统节日。
生成问答:泼水节又称为什么 宋干节
泼水节是我国哪一民族一年中最盛大的节日? 傣族
泼水节有多少年历史了? 700年
思路分析 #
本文的目标是完全端到端地实现“篇章 → 答案 + 问题”,包括答案的选取也是由模型自动完成,不需要人工规则。其实说起来也很简单,就是用“BERT + UniLM”的方式来构建一个Seq2Seq模型(UniLM的Attention Mask,加上BERT的预训练权重),如果读者还不了解UniLM,欢迎先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
笔者之前在文章《万能的seq2seq:基于seq2seq的阅读理解问答》中也给出过通过Seq2Seq模型来做阅读理解的实现,即直接用Seq2Seq模型来构建$p\big(\text{答案}\big|\text{篇章},\text{问题}\big)$,图示如下:
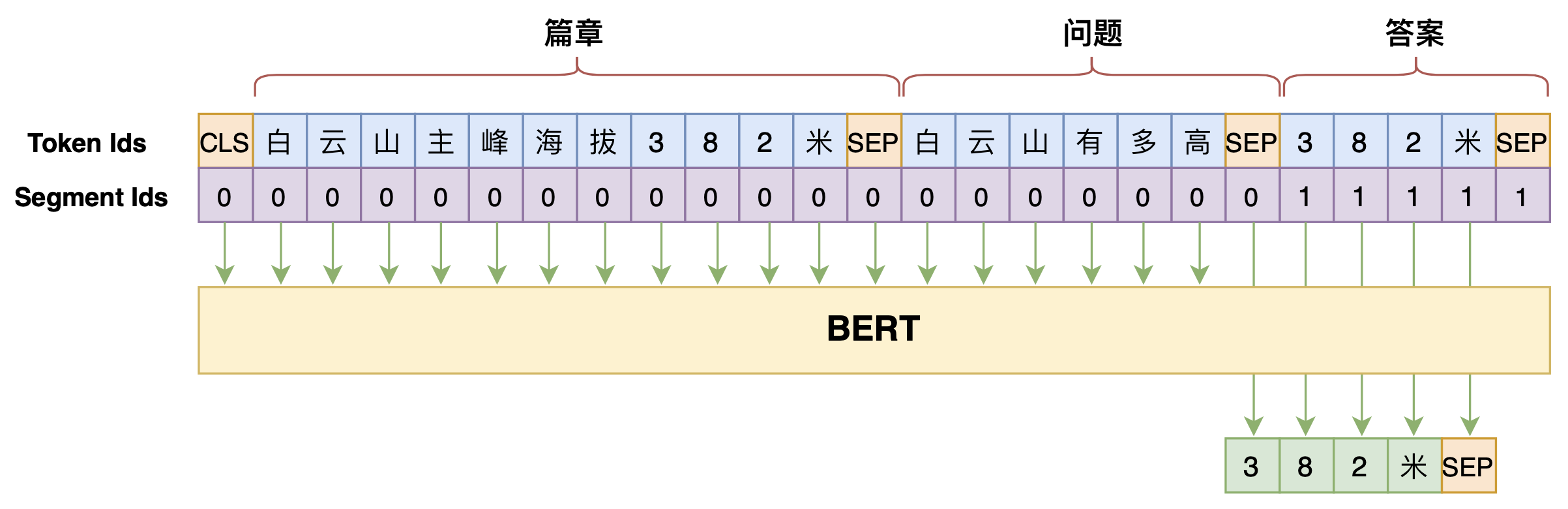
用Seq2Seq的思路做阅读理解
事实上,在上述模型的基础上稍微改动一下,将问题也列入生成的目标之中,就可以实现问答对生成了,即模型变为$p\big(\text{问题},\text{答案}\big|\text{篇章}\big)$,如下图:

稍微修改一下,用来做问答对生成
但是,直觉上不难想到“篇章 → 答案”、“篇章 + 答案 → 问题”的难度应该是低于“篇章 + 问题 → 答案”的,所以我们将问题和答案的生成顺序调换一下,变为$p\big(\text{答案},\text{问题}\big|\text{篇章}\big)$,最终的效果会更好:
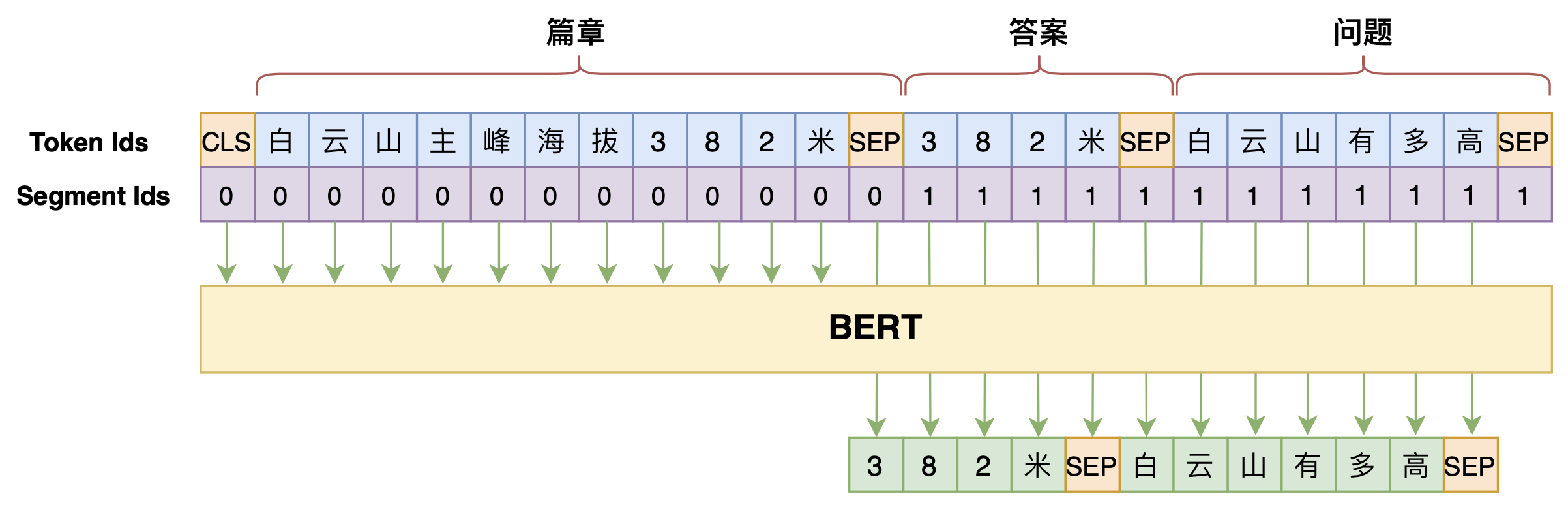
先生成答案,再生成问题,效果更好些
实现分析 #
模型就介绍到这里了,其实也没什么好说的,就是确定好哪些是输入、哪些是输出,然后“BERT + UniLM”套上去就行了。下面是笔者的参考实现:
这里值得讨论的是解码的思路。一般的Seq2Seq模型,解码到一个[SEP]就结束了,而本文的模型需要解码到两个[SEP]才能结束,截止到第一个[SEP]的是答案,而两个[SEP]之间的则是问题。理论上来说,从给定篇章中我们可以构建很多问答对,换句话说目标不是唯一的,所以我们不能用Beam Search之类的确定性解码算法,而是要用随机解码算法(相关概念可以参考《如何应对Seq2Seq中的“根本停不下来”问题?》中的“解码算法”一节)。
但问题是,如果完全使用随机解码算法,那么生成的问题会过于“天马行空”,也就是可能会出现一些跟篇章无关的内容,比如篇章是“我国火星探测器天问一号发射成功”,生成的问题可能是“我国第一颗人造卫星是什么”,虽然相关,但是过于发散了。所以,这里建议使用一个折中的策略:用随机解码来生成答案,然后用确定性解码来生成问题,这样能尽量保证问题的可靠性。当然,如果读者更关心生成问题的多样性,那么全部使用随机解码也行,反正就自己调试啦。
读者还需要注意的是,上述参考脚本中并没有对答案进行约束,那么生成的答案可能并不是篇章中的片段。毕竟这只是个参考实现,离实用还有一定距离,请有兴趣的读者根据自己的需求自行理解和修改代码。此外,由于问答对构建已经完全变成了一个Seq2Seq问题,所以用来提升Seq2Seq性能的技巧都可以用来提高问答对的生成质量,比如之前讨论过的《Seq2Seq中Exposure Bias现象的浅析与对策》,这些都交给读者自己尝试了。
文章小结 #
本文是一次端到端的问答对生成实践,主要是基于“BERT + UniLM”的Seq2Seq模型来直接根据篇章生成答案和问题,并讨论了关于解码的策略。总的来讲,本文的模型没有什么特殊之处,但是因为借助了BERT的预训练权重,最终生成的问答对质量颇有可圈可点之处。
转载到请包括本文地址:https://spaces.ac.cn/archives/7630
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jul. 25, 2020). 《学会提问的BERT:端到端地从篇章中构建问答对 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7630
@online{kexuefm-7630,
title={学会提问的BERT:端到端地从篇章中构建问答对},
author={苏剑林},
year={2020},
month={Jul},
url={\url{https://spaces.ac.cn/archives/7630}},
}

November 20th, 2020
苏神你好,请教一下,如果基于多轮问答来构造一段文本输出,比如基于多轮问诊生成一段病历描述,请问有什么好的思路吗
1. 准备标注数据
2. 套用seq2seq模型
April 7th, 2021
感谢分享,请问就是使用task_question_answer_generation_by_seq2seq.py代码中的默认超参达到文章开头提到的效果吗?
是。
July 8th, 2021
感谢分享,我想请问一下你的task_question_answer_generation_by_seq2seq.py代码中按照你本文的例子去生成问答对,如何可以做到生成这么多不同的对呢。
我尝试随机采样3个答案来生成问题,大部分情况出来的答案都是相同的。
补充:对于同一个passage,重复qag.generate后生成的问答对也基本相同的(用的本文的例子)
这本身就取决于你训练数据集的多样性,出现这样的结果,说明标注人员在标注数据的时候思维方向都很单一。
你可以尝试修改解码过程,将a、q的解码方式都改为random_sample
非常感谢回答。我想请问我用的是本文提供的百度知道和搜狗的数据集,如何可以复现您在文章中展示的效果呢
我就是直接训练复现的,并没有保留什么。可以多保留几轮模型,对比一下效果。
同学,请问你是否能实现展示的效果了呢?我也遇到了同样的问题,期待你的回复~
July 27th, 2021
苏神,我在训练的时候报了这个错误,这个是什么问题,搜了一下好像没有对应的解决办法,代码仍然在跑和更新权重。这个要怎么解决?
832/1000 [=======================>......] - ETA: 59s - loss: 0.7593Traceback (most recent call last):
File "qag_with_917.py", line 179, in
callbacks=[evaluator]
File "/dssg/home/zn_hwm/.local/lib/python3.7/site-packages/keras/engine/training.py", line 1147, in fit
initial_epoch=initial_epoch)
File "/dssg/home/zn_hwm/.local/lib/python3.7/site-packages/keras/legacy/interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "/dssg/home/zn_hwm/.local/lib/python3.7/site-packages/keras/engine/training.py", line 1732, in fit_generator
initial_epoch=initial_epoch)
File "/dssg/home/zn_hwm/.local/lib/python3.7/site-packages/keras/engine/training_generator.py", line 220, in fit_generator
reset_metrics=False)
File "/dssg/home/zn_hwm/.local/lib/python3.7/site-packages/keras/engine/training.py", line 1514, in train_on_batch
outputs = self.train_function(ins)
File "/dssg/home/zn_hwm/.conda/envs/corpus/lib/python3.7/site-packages/tensorflow/python/keras/backend.py", line 3253, in __call__
session = get_session(inputs)
File "/dssg/home/zn_hwm/.conda/envs/corpus/lib/python3.7/site-packages/tensorflow/python/keras/backend.py", line 462, in get_session
_initialize_variables(session)
File "/dssg/home/zn_hwm/.conda/envs/corpus/lib/python3.7/site-packages/tensorflow/python/keras/backend.py", line 873, in _initialize_variables
if not getattr(v, '_keras_initialized', False):
KeyboardInterrupt
我没看到这是什么错误,这是你自己ctrl+c引起的错误吧...
August 3rd, 2021
苏神你好呀,如果我是针对一个文段(可以提问好几个问答)来生成问答对的话,是不是比较难,因为模型最后生成的只有一个问答对。如果将文段分句后训练,又会出现分句会缺乏主语,或者有代词。这种问题怎么解决比较好?如果在分句后的句子开头都添加缺失的主语进行训练,训练完后,待生成问答对的句子也同样在开头添加对应的主语进行输入。这样可行吗?
理论上,(本文的)模型最后可以生成无穷多的问答对,不存在只生成一个的问题。
你好,你的工作有后续吗,主语缺失是如何解决的
September 7th, 2021
苏神,我这边标注了1k+条数据,然后都是比较类似的数据,后面测试的数据也是跟这些类似的。step_epoch是取数据量/batchsize?吗,epoch,step_epoch,学习率这些取值有什么建议的吗?
建议自行调试,形成自己的炼丹经验。
March 27th, 2022
那如果我问题和答案都是同一个解码方式,如果数据量大的话。那是不是可以直接答案和问题之间可以不用SEP间隔了?直接CLS passge SEP a+q SEP输入。还是说加个SEP的话,模型会更好的识别答案的结束位置?
就是为了区分答案的位置而已,你不用SEP用其他特殊标记也行。
December 29th, 2023
请问苏神,打标时,答案是不是越短越准确?问题也是同样的道理吧?
问题或答案可以间隔字或词提取吗?
现在可以直接用LLM提取了吧?
这篇文章的模型是生成式的,跟LLM本质上同理,所以理论上可以不连续,但实际效果如何是未知的。
感谢苏神!回头我对比一下
April 23rd, 2024
我想问一下基于unilm的掩码机制让只有编码器的nezha模型可以用于文本生成任务,那面对未登录词,怎么使用copy机制了?copy机制不是需要编码器和解码器?这里好像不太好区分unilm+nezha中的编码器和解码器
一般情况下使用subword-based的tokenizer,或者干脆使用目前比较流行的sentencepiece等,出现未登录词的概率几乎没有。
July 18th, 2024
你好,生成的答案太短了,,我调大max_a_len,会有错误tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [32,548,768] vs. [1,512,768]
训练集就只有这么短,调大也没用。
我自己的的数据集中,的answer很长,所以想调大,,但是总是维度不匹配,请问有啥思路吗
BERT的总长度不能超过512,看上去你的错误信息是因为超过了这个总长度。
另外就是如果有可能的话,直接用各种LLM api来生成效果更好。