






30
May
科学空间:2010年6月重要天象
By 苏剑林 | 2010-05-30 | 27954位读者 | 引用
20100626月球模拟
进入六月,除除了水星外肉眼可见的几颗大行星观测条件还不错。前半夜的主要观测目标是金星、火星和土星,他们之间的角距离也在逐渐缩小。后半夜木星升起,我们又有机会一睹这颗太阳系内最大行星的风采了。6月21日是夏至节气,当天北半球白昼是一年中最长的,而夜晚最短,且越往北越短。在北极圈以内地区当天太阳将不会落到地平线以下18度之内时,辉光都会影响到我们目视的极限星等,因此夏至前后一段时间北纬50度以上地区不太适合进行天文观测了。而对于北纬30至40度左右的观测者来说,这期间适合开展人造天体,特别是国际空间站的观测活动。
16
Nov
天体力学巨匠——拉普拉斯
By 苏剑林 | 2012-11-16 | 45824位读者 | 引用本文其实好几个月前就已经写好了,讲的是我最感兴趣的天体力学领域的故事,已经发表在2012年11月的《天文爱好者》上。

天体力学巨匠——拉普拉斯
作为一本天文科普杂志,《天文爱好者》着眼于普及天文,内容偏向于有趣的天体物理等,比较少涉及到天体力学。事实上,在天文发展史中,天体力学——研究天体纯粹在万有引力作用下演化的科学——占据了相当重要的地位。过去,天文就被划分为天体力学、天体物理以及天体测量学三个大块。只是在近现代,由于电子计算机的飞速发展,天体力学的多数问题都交给了计算机数值计算解决,因此这一领域逐渐淡出了人们视野。不过,回味当初那段天体力学史,依然让我们觉得激动人心。
首先引入“天体力学(Celestial mechanics)”这一术语的是法国著名数学家、天文巨匠拉普拉斯。他的全名为皮埃尔?西蒙?拉普拉斯(Pierre?Simon marquis de Laplace),因研究太阳系稳定性的动力学问题被誉为法国的牛顿和天体力学之父。他和生活在同一时代的法国著名数学家拉格朗日以及勒让德(Adrien-Marie Legendre)并称为“三L”。
神秘的少年时期
由于1925年的一场大火,很多拉普拉斯的生活细节资料都丢失了。根据W. W. Rouse Ball的说法,他可能是一个普通农民或农场工人的儿子,1749年3月23日出生于诺曼底卡尔瓦多斯省的伯蒙特恩奥格。少年时期,拉普拉斯凭借着自己的才能和热情,在富人邻居的帮助下完成了学业。他父亲希望这能使他将来以宗教为业,16岁时,他被送往卡昂大学读神学。但他很快在数学上显露头角。
欢聚兴隆,畅言科普
记信息时代的天文科普研讨会暨第三届宇宙驿站站长联谊会
在信息时代的今天,利用互联网相互交流以及查找各种资讯已经成为了许多天文爱好者的必经之道。同好们也许都浏览过牧夫天文论坛、星友空间站、空间天文网等天文科学网站,事实上,它们都源于一个共同的科普网站群体——宇宙驿站。正如她的名字所言,宇宙驿站是我们一大群天文爱好者在互联网上的“家”,她为我们这群热衷于网络科普的站长免费提供了稳定的网站空间。
宇宙驿站发起于2002年,是国家天文台LAMOST项目之一,迄今已经有近百位站长在上面“安家”。2013年6月28日到6月30日,我们这群站长齐聚兴隆,开展了一次别开生面的会议——“信息时代的天文科普研讨会暨第三届站长联谊会”。
25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 192602位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 83620位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
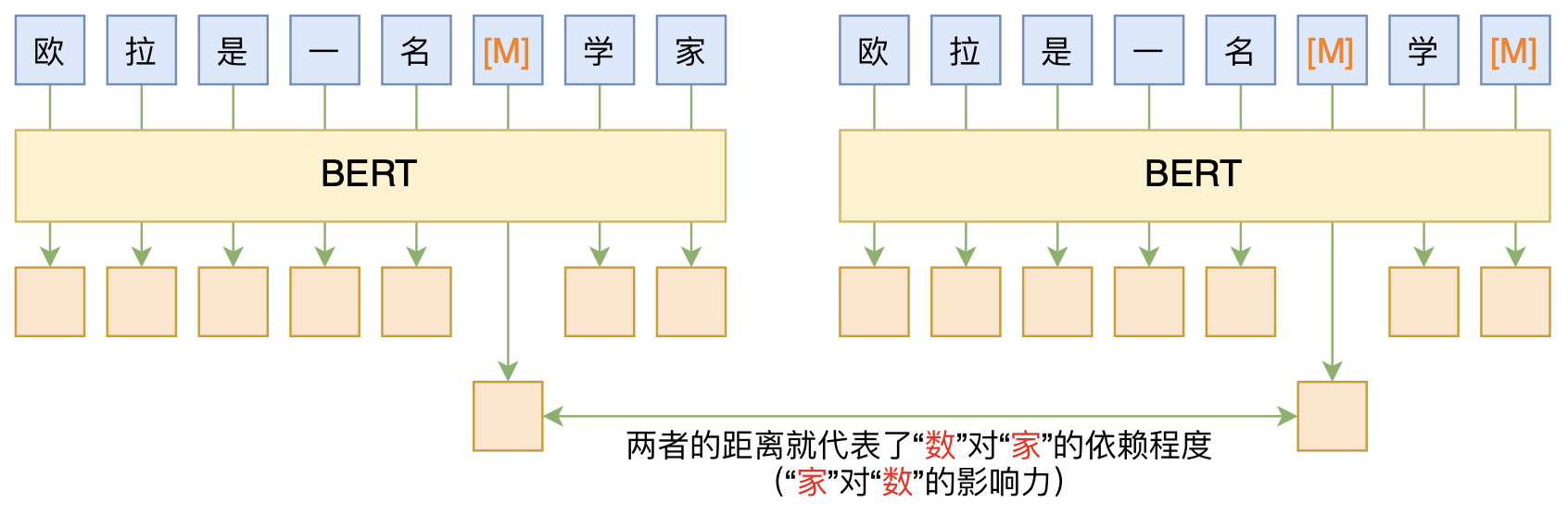
基于BERT的“token-token”相关度计算图示
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 52755位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
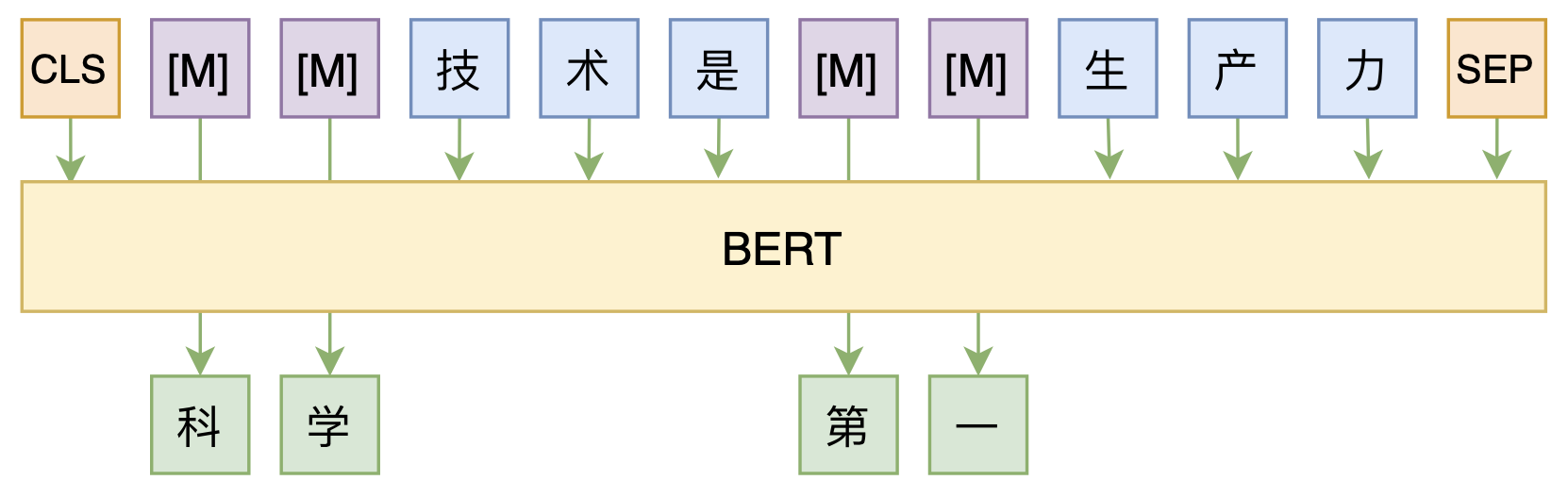
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 191704位读者 | 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第$k$个向量$\boldsymbol{x}_k$中加入位置向量$\boldsymbol{p}_k$变为$\boldsymbol{x}_k + \boldsymbol{p}_k$,其中$\boldsymbol{p}_k$只依赖于位置编号$k$。
9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 74341位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。

最近评论