






24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 59627位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 56704位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 112461位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 174343位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
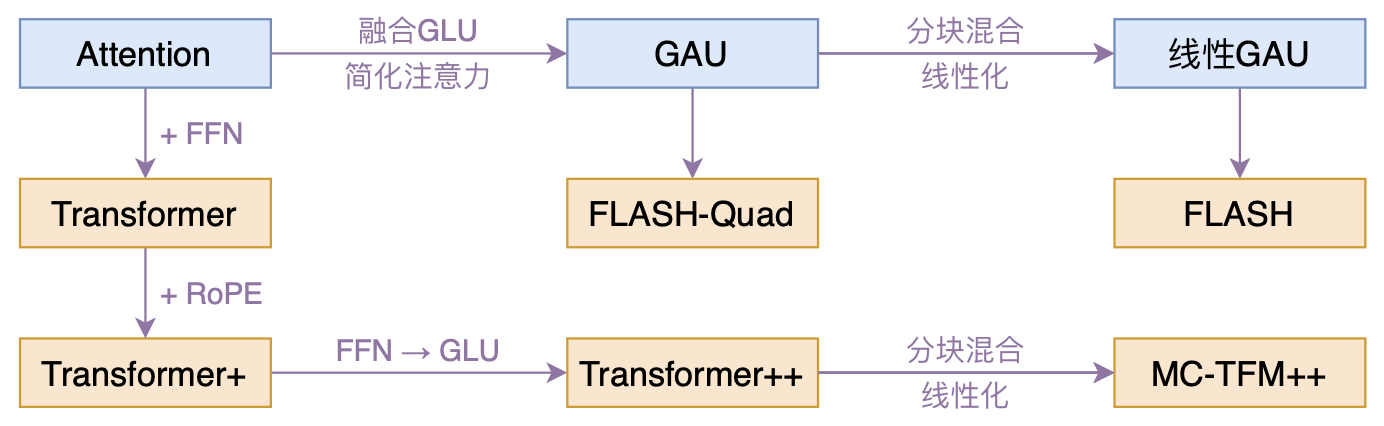
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
11
Apr
熵不变性Softmax的一个快速推导
By 苏剑林 | 2022-04-11 | 18305位读者 | 引用在文章《从熵不变性看Attention的Scale操作》中,我们推导了一版具有熵不变性质的注意力机制:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\kappa \log n}{d}QK^{\top}\right)V\label{eq:a}\end{equation}
可以观察到,它主要是往Softmax里边引入了长度相关的缩放因子$\log n$来实现的。原来的推导比较繁琐,并且做了较多的假设,不利于直观理解,本文为其补充一个相对简明快速的推导。
推导过程
我们可以抛开注意力机制的背景,直接设有$s_1,s_2,\cdots,s_n\in\mathbb{R}$,定义
$$p_i = \frac{e^{\lambda s_i}}{\sum\limits_{i=1}^n e^{\lambda s_i}}$$
31
Jan
Transformer升级之路:8、长度外推性与位置鲁棒性
By 苏剑林 | 2023-01-31 | 43218位读者 | 引用上一篇文章《Transformer升级之路:7、长度外推性与局部注意力》我们讨论了Transformer的长度外推性,得出的结论是长度外推性是一个训练和预测的不一致问题,而解决这个不一致的主要思路是将注意力局部化,很多外推性好的改进某种意义上都是局部注意力的变体。诚然,目前语言模型的诸多指标看来局部注意力的思路确实能解决长度外推问题,但这种“强行截断”的做法也许会不符合某些读者的审美,因为人工雕琢痕迹太强,缺乏了自然感,同时也让人质疑它们在非语言模型任务上的有效性。
本文我们从模型对位置编码的鲁棒性角度来重新审视长度外推性这个问题,此思路可以在基本不对注意力进行修改的前提下改进Transformer的长度外推效果,并且还适用多种位置编码,总体来说方法更为优雅自然,而且还适用于非语言模型任务。
10
Apr
从JL引理看熵不变性Attention
By 苏剑林 | 2023-04-10 | 29311位读者 | 引用在《从熵不变性看Attention的Scale操作》、《熵不变性Softmax的一个快速推导》中笔者提出了熵不变性Softmax,简单来说就是往Softmax之前的Attention矩阵多乘上一个$\log n$,理论上有助于增强长度外推性,其中$n$是序列长度。$\log n$这个因子让笔者联系到了JL引理(Johnson-Lindenstrauss引理),因为JL引理告诉我们编码$n$个向量只需要$\mathcal{O}(\log n)$的维度就行了,大家都是$\log n$,这两者有没有什么关联呢?
熵不变性
我们知道,熵是不确定性的度量,用在注意力机制中,我们将它作为“集中注意力的程度”。所谓熵不变性,指的是不管序列长度$n$是多少,我们都要将注意力集中在关键的几个token上,而不要太过分散。为此,我们提出的熵不变性Attention形式为
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\log_{512} n}{\sqrt{d}}QK^{\top}\right)V\label{eq:core}\end{equation}
12
May
Transformer升级之路:9、一种全局长度外推的新思路
By 苏剑林 | 2023-05-12 | 55644位读者 | 引用说到Transformer无法处理超长序列的原因,大家的第一反应通常都是Self Attention的二次复杂度。但事实上,即便忽略算力限制,常规的Transformer也无法处理超长序列,因为它们的长度外推性(Length Extrapolation)并不好,具体表现为当输入序列明显超过训练长度时,模型的效果通常会严重下降。
尽管已有一些相关工作,但长度外推问题离实际解决还比较远。本文介绍笔者构思的一种参考方案,它可能是目前唯一一种可以用在生成模型上、具备全局依赖能力的长度外推方法。
方法回顾
长度外推,也称为长度泛化(Length Generalization),此前我们在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》已经介绍过部分工作。然而,它们各有各的问题。

最近评论