






24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 87263位读者 |大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙 #
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
《MLP-Mixer: An all-MLP Architecture for Vision》 - Google Research
《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》 - 清华大学
《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》 - 牛津大学
《Are Pre-trained Convolutions Better than Pre-trained Transformers?》 - Google Research
《ResMLP: Feedforward networks for image classification with data-efficient training》 - Facebook AI
《FNet: Mixing Tokens with Fourier Transforms》 - Google Research
《Pay Attention to MLPs》 - Google Research
以上论文是按照出现在arixv上的时间排序的。可以看到主力军依旧是Google大佬。想当年一手促成了“Attention is all you need”趋势的也是Google,现在“重拳出击”Transformer的还是Google,Google大佬真可谓一直挖坑不断啊。
把酒话桑麻 #
那么这系列工作究竟能带来什么启发呢?我们要不要赶紧跟上这系列工作呢?在这部分内容中,我们就来简要地梳理一下上述几篇论文,看看它们是何方神圣,是否有可能造成新一股模型潮流?
Synthesizer #
要解读上述MLP相关的工作,就不得不提到去年五月Google发表在《Synthesizer: Rethinking Self-Attention in Transformer Models》的Synthesizer。而事实上,如果你已经了解了Synthesizer,那么上面列表中的好几篇论文都可以一笔带过了。
在之前的博客《Google新作Synthesizer:我们还不够了解自注意力》中,我们已经对Synthesizer做了简单的解读。撇开缩放因子不说,那么Attention的运算可以分解为
\begin{equation}\boldsymbol{O}=\boldsymbol{A}\boldsymbol{V},\quad \boldsymbol{A}=softmax(\boldsymbol{B}),\quad \boldsymbol{B}=\boldsymbol{Q}\boldsymbol{K}^{\top}\end{equation}
其中$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$是输入序列的变换,这个了解Self Attention的读者应该都清楚,不再详写。Synthesizer则是对几种$\boldsymbol{B}$的新算法做了实验,其中最让人深刻的一种名为Random,就是将整个$\boldsymbol{B}$当作一个参数矩阵(随机初始化后更新或者不更新)。
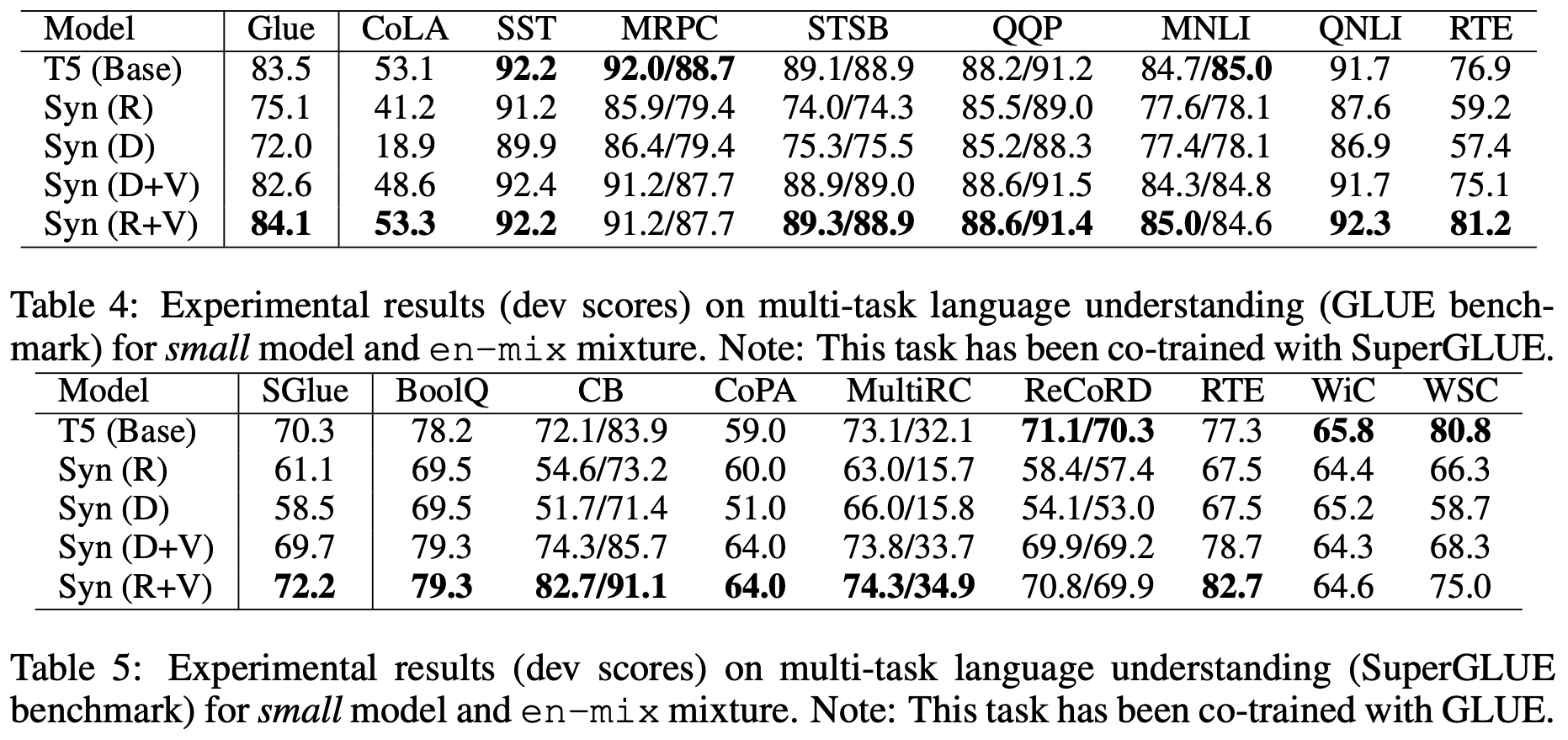
Synthesizer的“预训练+微调”实验结果。实验的baseline是T5,其中“R”即为Random模式,相当于MLP。
在Random的情况下,Attention矩阵不再是随样本变化的了,也就是所有样本公用同一个Attention矩阵,但是它依然能取得不错的效果,这在当时确实对大家对Attention的固有理解造成了强烈冲击。Synthesizer的实验相当丰富,包括“机器翻译”、“自动摘要”、“对话生成”、“预训练+微调”等,可以说,上面列罗的多数论文,实验都没有Synthesizer丰富。
MLP-Mixer #
Synthesizer也许没想到,一年之后,它换了个名字,然后火起来了。
论文《MLP-Mixer: An all-MLP Architecture for Vision》所提出来的MLP-Mxier,其实就是Synthesizer的Random模式并去掉了softmax激活,也就是说,它将$\boldsymbol{B}$设为可训练的参数矩阵,然后直接让$\boldsymbol{A}=\boldsymbol{B}$。模型就这样已经介绍完了,除此之外的区别就是MLP-Mxier做CV任务而Synthesizer做NLP任务而已。
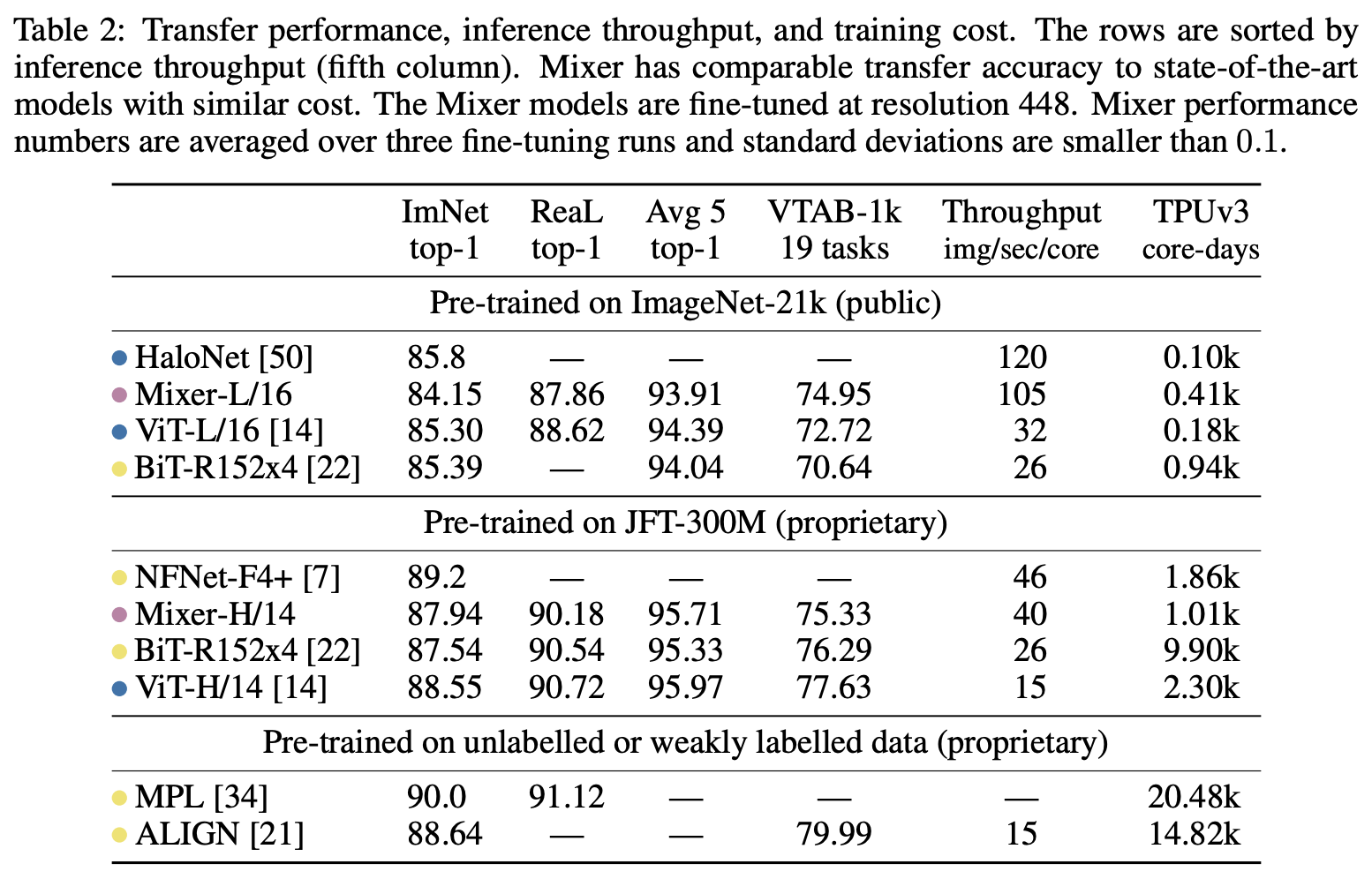
MLP-Mixer的部分实验结果
对了,为啥这模型叫MLP-Mxier呢,因为作者把这种直接可训练的Attention模式起了个名字叫做“token-mixing MLP”,把原来的FFN改叫做“channel-mixing MLP”(以前叫做Position-wise FC),不管叫啥,反正就是号称只是MLP,所以模型也叫做MLP-Mxier。
而事实上,笔者认为这个更标准的叫法是窗口为1的一维卷积,但不管是这篇论文还是之前的《Attention Is All You Need》,都是宁愿把这些常规操作自己另起个名字,也要选择性地减少甚至无视与卷积的联系,可谓是为了“A Good Title Is All You Need”而煞费苦心了。
其实这一点也遭到了LeCun的批评,如果真的是标准的MLP,那应该要将输入展平为一个一维向量,然后再接变换矩阵~
External Attention #
从类比的角度看,Synthesizer的Random模式或者MLP-Mxier,相当于将Attention中的$\boldsymbol{Q}$和$\boldsymbol{K}$都设为参数矩阵了,而《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》所提出的External Attention,则是把$\boldsymbol{K}$和$\boldsymbol{V}$设为(固定大小的)参数矩阵了,实验任务同样是CV的。
本来这也没什么,毕竟深度学习就是效果为王,效果好了就能成文。但是个人认为External Attention很多说法就禁不住推敲的。
首先,它把自己称为“两个线性层”,刻意淡化它跟Attention的联系(说出它是Attention的特例很丢人?);然后它又说“通过引入两个外部记忆单元(也就是设为参数的$\boldsymbol{K}$和$\boldsymbol{V}$),隐式地学习了整个数据集的特征”,这种说法也不能算错,然而其实任意模型的任意参数都可以这样解释,这并不是External Attention的特性;还有它说能实现线性的复杂度,那得固定$\boldsymbol{K},\boldsymbol{V}$的长度,这种情况下其实应该跟也同样是线性复杂的LinFormer比比才更有说服力(论文比了Performer,但是Performer的降低复杂度思路是不一样的,LinFormer更有可比性)。
抛开这些文字上的不说,External Attention的工作机制似乎有点迷。不难想到External Attention对每个特征的编码是孤立的,如果换到NLP来说,那就是说每个词都独立编码的,根本不与上下文产生联系,所以肯定是不work的,那为什么在CV中会work呢?
Stack of FFN #
至于论文《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》,其实跟MLP-Mixer是高度重合的,不过它写起来就实在多了。它就是将输入过一个常规的FFN,然后将输出转置,再过一个FFN,最后转置回来,这样如果本身就熟悉Transformer的话,我们很快就清楚它做了啥。
这篇论文本身就很短,一共只有4页,还包括1页代码和半页参考文献,正文其实就只有2.5页,更像是一个简报。也许作者本身也想在这个方面深挖一下,结果Google的MLP-Mixer先出来了,那么做下去也没意思了,遂草草完事发出。(这部分故事纯粹是笔者自己的猜测。)
Pre-trained CNN #
事实上,CNN才是最早尝试(在Seq2Seq任务中)取代RNN的模型,Facebook的《Convolutional Sequence to Sequence Learning》其实更早发表,只不过很快就被Google的《Attention Is All You Need》抢了风头,后来GPT、BERT等模型发布之后,Transformer类模型就成了当前主流,CNN很少被深入研究了。
论文《Are Pre-trained Convolutions Better than Pre-trained Transformers?》则帮助我们验证了“CNN+预训练”的有效性。论文结果显示,不管是直接用下游数据监督训练,还是先预训练然后微调,基于膨胀卷积或动态卷积的CNN模型都略优于Transformer模型,并且在速度上CNN模型还更加快。对了,这篇论文已经中了ACL2021,所以这篇论文的成文其实更早,只不过这个月才放出来而已。
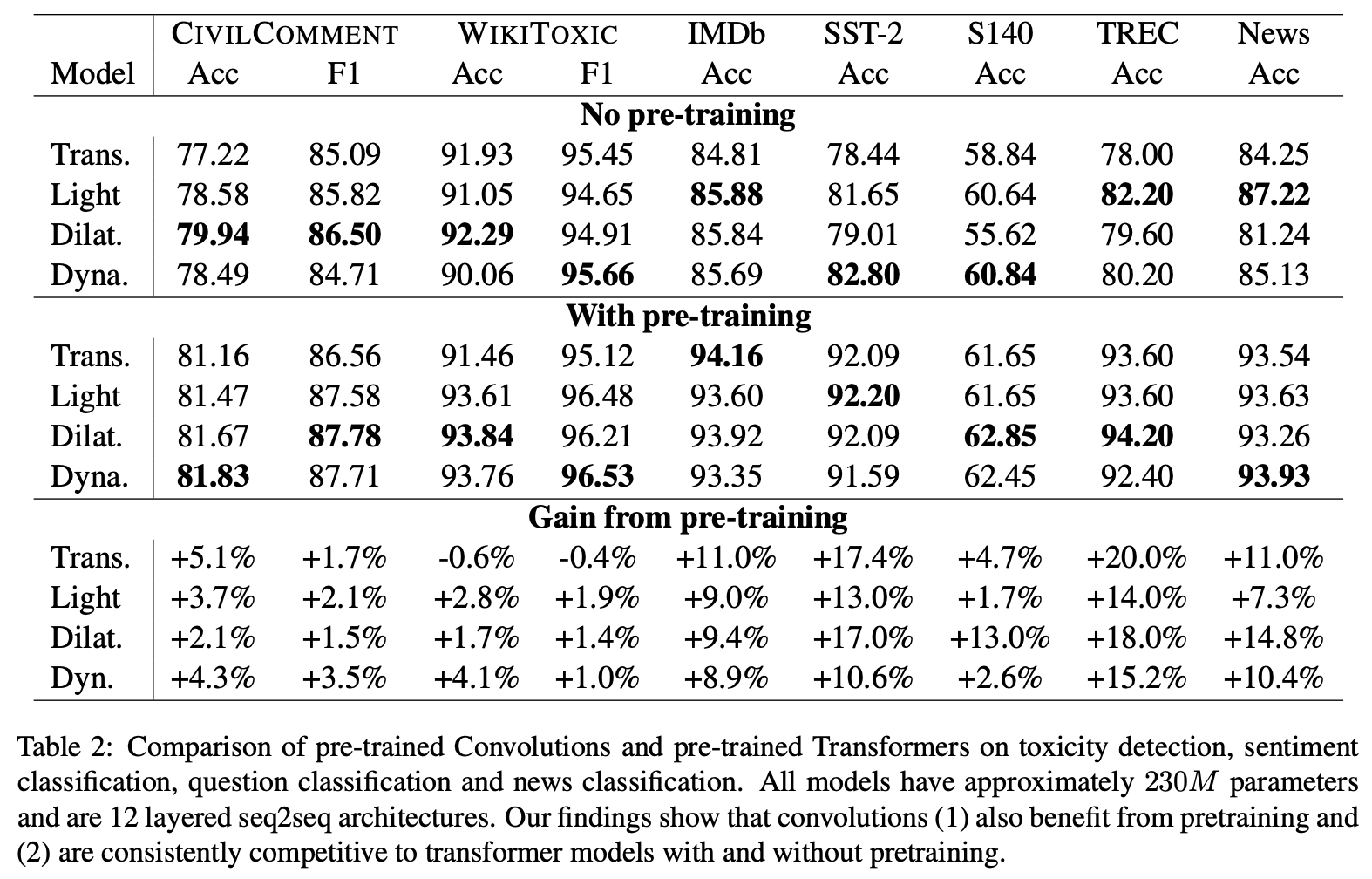
不管有无预训练,CNN都体现出了自己的优势
这篇论文给我们的主要启发是:预训练改进与模型改进不应该混为一谈,预训练技术本身往往能给各种模型都带来提升,不应该一提到预训练就想到Transformer,也不应该只把预训练跟Transformer结合。事实上,笔者之前也比较喜欢CNN,曾通过“膨胀门卷积(DGCNN)”的设计在多个任务上取得不错的效果,而这篇论文则再次肯定了CNN的价值。不过尽管如此,笔者可能依然不会投入主要精力转向CNN的研究。
首先,理论上来说,CNN就无法捕捉足够远的长程依赖,这是根本缺陷,虽然通过膨胀卷积等方式,可以快速增大CNN的感受野,但也只是比较大,不是Transformer理论上的一步到位;其次,如果单纯看提高效率角度,Transformer本身也有很多优化空间,如果只是为了执行效率而转向CNN,那这个理由似乎不那么有说服力;还有,Transformer的$\mathcal{O}(n^2)$的复杂度本身也带来更多的折腾空间(比如像UniLM),可以玩出更多的花样(比如像K-BERT)。
总的来说,我们不能否定CNN的价值,但如果当前已经比较专注Transformer了,那么就没必要分出太多精力去转向CNN了。
ResMLP #
至于Facebook在《ResMLP: Feedforward networks for image classification with data-efficient training》提出的ResMLP,跟前述的MLP-Mixer和Stack of FFN也没有本质区别,其文字描述也跟Stack of FFN很相似,忽略细微的细节差异,甚至可以认为它们三个就是同一个模型。最后,ResMLP的实验任务同样是CV的。
FNet #
就笔者看来,《FNet: Mixing Tokens with Fourier Transforms》所提出的FNet,是列表的七篇论文中最有意思的一篇。某种意义上来说,FNet也是MLP-Mixer的一个特例,但它是一个非常有意思的特例:MLP-Mixer的注意力矩阵是直接参数优化而来的,FNet的参数矩阵是直接通过傅里叶变换得到的!所以,FNet的“注意力层”是没有任何优化参数的!
其实我们也可以从注意力的角度来理解FNet。抛开归一化因子不看,那么注意力运算大致可以写为:
\begin{equation}\boldsymbol{O}=\boldsymbol{A}\boldsymbol{V},\quad \boldsymbol{A}=\exp(\boldsymbol{B}),\quad \boldsymbol{B}=\boldsymbol{Q}\boldsymbol{K}^{\top}\end{equation}
这里的$\boldsymbol{Q},\boldsymbol{K}$本来是$n\times d$的矩阵,FNet说:$\boldsymbol{Q},\boldsymbol{K}$可以换成$n\times 1$矩阵:
\begin{equation}\boldsymbol{Q}=\boldsymbol{K}=\begin{pmatrix}0 \\ 1 \\ 2 \\ \vdots \\ n - 1\end{pmatrix}\end{equation}
是的,你没看错,它就是要将它粗暴地换成$0\sim n-1$组成的$n\times 1$矩阵。当然,这样一来越到后面$\exp(\boldsymbol{B})$就指数爆炸了。为了避免这种情况,FNet就改为
\begin{equation}\boldsymbol{A}=\exp(\text{i}\boldsymbol{B})\end{equation}
也就是搞成虚指数就不会爆炸了!就这么粗暴,这就得到了基于傅里叶变换的FNet。原论文对序列长度和特征维度两个方向都做了傅里叶变换,然后只保留实数部分,就用这个运算取代了自注意力。对于傅里叶变换的实现,我们有称之为“快速傅里叶变换(FFT)”的算法,效率是$\mathcal{O}(n\log n)$,所以FNet也能有效处理长序列。
FNet的部分效果如下表。其实从预训练和下游任务的效果上来看,FNet并没有什么优势,不过它在Long-Range Arena(一个测试模型长程能力的评测榜单)上的效果倒是不错。
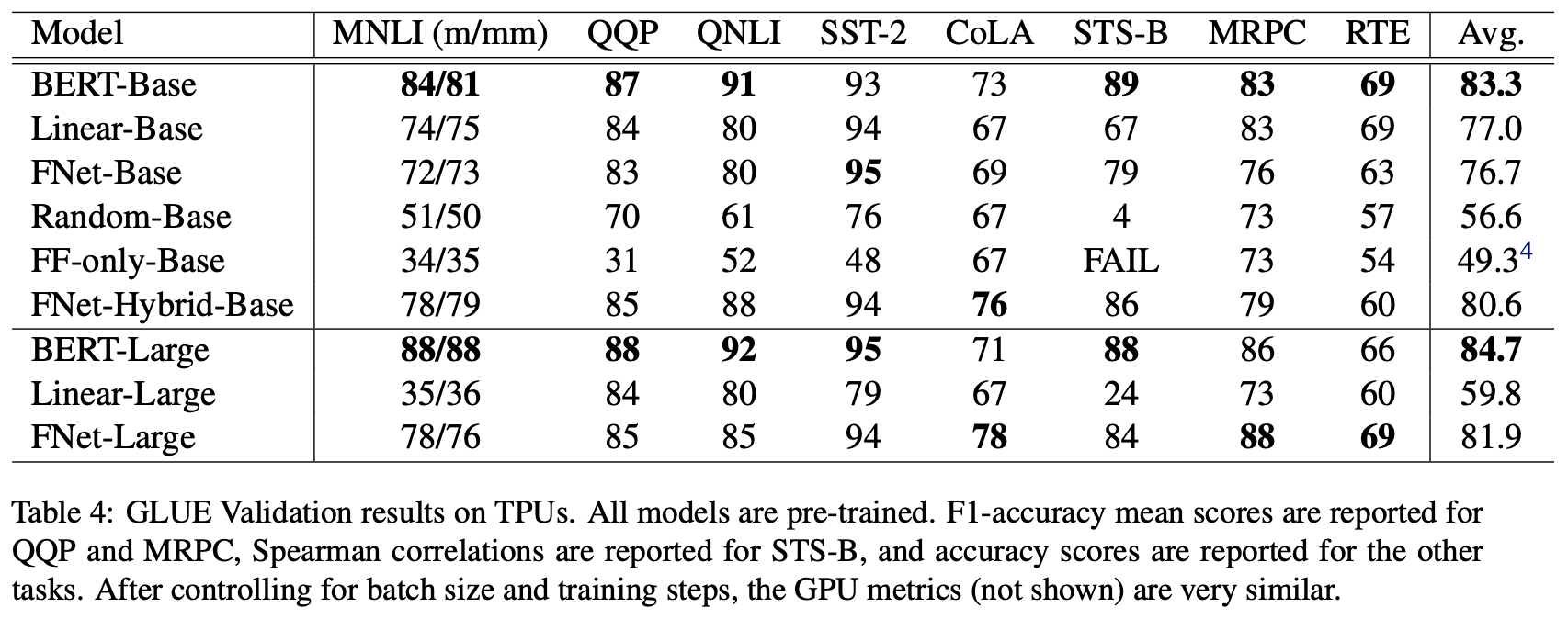
FNet的“预训练+微调”实验结果
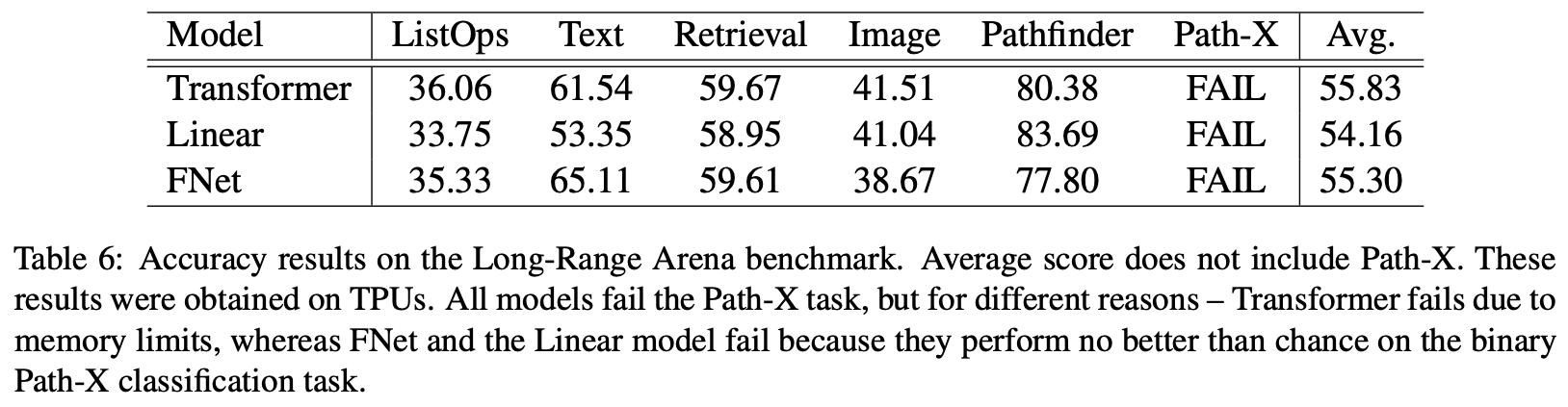
FNet的Long-Range Arena实验结果
当然,FNet这么粗暴的做法能行本来就已经是个奇迹了,它给我们带来的最大冲击无疑是:就这样都行?傅里叶变换为什么能行?笔者也不知道答案。网上有些评论说,这说明了注意力机制其实就是一种坐标基的变换,而傅里叶变换也是一种基的变换,两者的作用是类似的。这个说法确实有点本质的感觉,在ICLR2021中也有篇论文《Is Attention Better Than Matrix Decomposition?》用SVD代替Attention也能取得不错的效果,这说明基变换的说法确实存在(SVD也是一种基变换),但是基变换的同时如何保持时序性、哪种基变换更适合,这些问题完全没有头绪。
gMLP / aMLP #
最后《Pay Attention to MLPs》所给我们带来的gMLP、aMLP是比较常规的新结构探索工作,算是MLP-Mixer的增强版。gMLP的g是“gate”的意思,简单来说gMLP就是将MLP-Mixer跟门控机制结合起来,而aMLP的a是“attention”的意思,它将attention与gMLP结合起来。
具体来说,gMLP大致是如下运算:
\begin{equation}\begin{aligned}
&[\boldsymbol{X}_1, \boldsymbol{X}_2] = \boldsymbol{X} \\
&\boldsymbol{Y} = \boldsymbol{W}\boldsymbol{X}_2 + \boldsymbol{b} \\
&\boldsymbol{O} = \boldsymbol{X}_1 \otimes \boldsymbol{Y}
\end{aligned}\end{equation}
简单来说,就是将输入沿着特征维度分为两半,然后将其中一半传入MLP-Mixer,作为另一半的gate。而aMLP则是将MLP-Mixer和一个简单的单头Self Attention结合来作为gate:
\begin{equation}\begin{aligned}
&[\boldsymbol{X}_1, \boldsymbol{X}_2] = \boldsymbol{X} \\
&\boldsymbol{Y}_1 = \boldsymbol{W}\boldsymbol{X}_2 + \boldsymbol{b} \\
&\boldsymbol{Y}_2 = SelfAttention(\boldsymbol{X}) \\
&\boldsymbol{O} = \boldsymbol{X}_1 \otimes (\boldsymbol{Y}_1 + \boldsymbol{Y}_2)
\end{aligned}\end{equation}
论文做的实验比较全面,包括CV和NLP的。从论文所报告的效果来看,gMLP略差于标准的Self Attention,而aMLP则是普遍优于Self Attention,这进一步肯定了门控机制的价值。只不过不管是gMLP还是aMLP,人工堆砌的味道太重了,要水一篇paper还可以,但个人认为没有给模型的发展方向带来什么新的启发。

gMLP,aMLP的NLP部分实验结果
前路在何方 #
通过以上阅读,我们可以知道,MLP-Mixer、Stack of FFN、ResMLP这三个模型,事实上可以看成是去年的Synthesizer的一个特例,甚至从技术上来说,它们还不如Synthesizer的内容丰富,因此真算不上什么有意思的工作;至于它的改进版gMLP / aMLP,则是非常常规的结构炼丹工作,只要算力足够我们都可以去做,所以也确实没什么意思;External Attention号称两个线性层,事实上就是Attention的变式,其生效机制和实验对比也不够明朗;比较有意思的就是CNN预训练和FNet这两个工作了,一个让我们解耦了“预训练改进”和“模型改进”两个概念,一个提出的傅里叶变换也有效给我们带来了较大的思想冲击。
整体而言,这些工作离成熟还远得很,最多是初步验证了有效性,连优雅也说不上。比如,除了FNet,这些所谓的“all in MLP”的模型,都没有办法比较优雅处理变长输入,像MLP-Mixer、Stack of FFN、ResMLP纯粹在(固定大小的)图像上实验,所以不用考虑这个问题,像Synthesizer / gMLP / aMLP虽然做了NLP的实验,但看上去都是强行截断的,算不上漂亮。所以,这系列工作一定程度上是开拓了新的思路,但其实带来了更多有待解答的问题。
那么我们要不要跟呢?个人认为没必要投入多少精力进去,平时大致关注一下就行了。抛开前面说的优雅性问题不说,这些工作的实用性本身就值得商榷。像将Attention换成MLP的改进,最大的优点无非就是提速,没错,是会快一点,但理论复杂度还是$\mathcal{O}(n^2)$,这说明其实没有本质改进,况且提速的同时通常还会降低一点性能。如果单从“提速并降低一点性能”的追求来看,Transformer可做的工作也非常多(最直接的就是减少一两层),没必要换成MLP,而换成MLP探索自由度降低了不少。当然,从“拓荒”的学术角度来看,多角度尝试各种新模型是有意义的,但这也不宜掺入过多的人造因素在里边,不然就变成了一个在结构上过拟合任务的过程了,难登大雅之堂。
此外,对于NLP来说,我们可能比较关心的是“预训练+微调”这一块的性能,而很遗憾,从Synthesizer开始的一系列NLP实验表明,将Attention换成MLP后的模型也许在某个任务上能取得有竞争性的结果,但是其迁移性往往不好,也就是说可能单看预训练效果还不错,但是“预训练+微调”多数就比不上Transformer了。这也不难理解,因为它们把Attention矩阵参数化,那么该矩阵更有可能跟具体任务强相关了,不像Transformer那样自适应生成的Attention矩阵那样具有更好的适应能力。
曲终人散时 #
本文盘点了最近的一些“非主流”工作,主要是通过以MLP为主的非Transformer结构来取代Transformer并获得了有竞争力的结果。总的来说,这些工作看起来形形色色,但都有迹可循,有“新瓶装旧酒”之感,能给人新启示的并不多。
全文仅乃笔者的闭门造车之言,仅代表笔者的个人观点,如有不当之处,还请读者海涵斧正。
转载到请包括本文地址:https://spaces.ac.cn/archives/8431
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 24, 2021). 《 也来盘点一些最近的非Transformer工作 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8431
@online{kexuefm-8431,
title={ 也来盘点一些最近的非Transformer工作},
author={苏剑林},
year={2021},
month={May},
url={\url{https://spaces.ac.cn/archives/8431}},
}

July 28th, 2021
能展开 FNet 的解释吗?原文中这样描述:
> Essentially, we replace the self-attention sublayer of each Transformer encoder layer with a Fourier sublayer, which applies a 2D DFT to its (sequence length, hidden dimension) embedding input – one 1D DFT along
the sequence dimension, $F_{seq}$, and one 1D DFT along the hidden dimension, $F_h$:
$y = \mathcal{R} (F_{seq} (F_h(x)))$
用本文中的 $Q, K, V, O$ notation,设 $F_m \in \mathbb{R}^{m \times m}$ 为对长度为 $m$ 序列的 1DFT的矩阵表示,Fnet 把 $O = attention(V, Q=V, K=V)$ 替换成了 $O = Real(F_n V F_d^T)$。这个并不能写成 $O = AV$的形式吧?
先不看取实部这个操作,你的$F_n$不就相当于$A$了么?所以形式不就是$AV$?
$F_d$怎么解释呢?不能移到 $V$ 前面变成 $AV$ 的形式。
$AV$ 本质上是对 V 的 column vector 做线性变换。
$VA$ 则是对 V 的 row vector 做线性变换。
按原文中的描述,这个要对 both column and row vector 做线性变化。我的理解是不能写成 $O=AV$ 的形式。
那是你根本没好好了解Attention。当前主流的Attention机制,在$AV$之后都会对channel维度做一个全连接变换,也就是$AVW$的形式,只不过这一步太平凡了,一般不做特别讨论罢了。
August 29th, 2022
现在有更多MLP文章出来了,苏神有关注吗?
不关注。