






28
Aug
Lion/Tiger优化器训练下的Embedding异常和对策
By 苏剑林 | 2023-08-28 | 28906位读者 | 引用打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$\pm 100$的级别。
经过分析,笔者发现类似现象并不会在Adam中出现,这是Tiger或者Lion这种带符号函数$\text{sign}$的优化器特有的问题,对此文末提供了两种参考解决方案。本文将记录笔者的分析过程,供大家参考。
现象
接下来,我们的分析都以Tiger优化器为例,但分析过程和结论同样适用于Lion。
22
Oct
从梯度最大化看Attention的Scale操作
By 苏剑林 | 2023-10-22 | 68416位读者 | 引用我们知道,Scaled Dot-Product Attention的Scale因子是$\frac{1}{\sqrt{d}}$,其中$d$是$\boldsymbol{q},\boldsymbol{k}$的维度。这个Scale因子的一般解释是:如果不除以$\sqrt{d}$,那么初始的Attention就会很接近one hot分布,这会造成梯度消失,导致模型训练不起来。然而,可以证明的是,当Scale等于0时同样也会有梯度消失问题,这也就是说Scale太大太小都不行。
那么多大的Scale才适合呢?$\frac{1}{\sqrt{d}}$是最佳的Scale了吗?本文试图从梯度角度来回答这个问题。
已有结果
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经推导过标准的Scale因子$\frac{1}{\sqrt{d}}$,推导的思路很简单,假设初始阶段$\boldsymbol{q},\boldsymbol{k}\in\mathbb{R}^d$都采样自“均值为0、方差为1”的分布,那么可以算得
\begin{equation}\mathbb{V}ar[\boldsymbol{q}\cdot\boldsymbol{k}] = d\end{equation}
12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 44234位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 12005位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
10
Apr
备忘:椭圆坐标与复三角函数
By 苏剑林 | 2011-04-10 | 49140位读者 | 引用
5
Dec
科学空间:2009年12月重要天象
By 苏剑林 | 2009-12-05 | 22510位读者 | 引用
4
Feb
大气光学质量(Airmass)
By 苏剑林 | 2010-02-04 | 35842位读者 | 引用天文学中有一个名词Airmass,注意这并非Air mass(空气质量),这是指天顶距等于z的方向上大气光学厚度和天顶方向大气光学厚度之比,我目前也找不到它的中文名称究竟是什么,反正觉得如果译成“大气质量”很怪,就暂且翻译成“大气厚度指数”好了。现在知道它叫做“大气光学质量”了,一般用X表示,如下图中,$X={BC}/{AC}$。
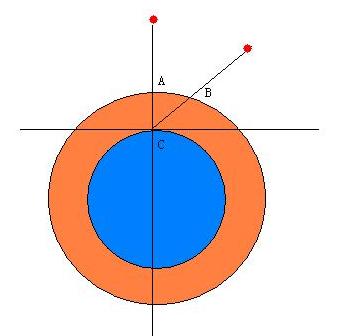
星光传播示意图
在一片较小的区域内,大气层和地面都可以视为平行平面,这时有一个很好的近似公式:
$$X=\sec z$$
对于现在的中学教材来说,有的读者可能不了解\sec为何物,实际上:$\sec z=\frac{1}{\cos z}$
27
Mar


最近评论