






6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 160243位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 114906位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 224398位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
24
Apr
【语料】2500万中文三元组!
By 苏剑林 | 2017-04-24 | 87318位读者 | 引用闲聊
这两年,知识图谱、问答系统、聊天机器人等领域是越来越火了。知识图谱是一个很泛化的概念,在我看来,涉及到知识库的构建、检索、利用等机器学习相关的内容,都算知识图谱。当然,这也不是个什么定义,只是个人的直观感觉。
做知识图谱的读者都知道,三元组是结构化知识的一种方法,是做知识型问答系统的重要组成部分。对于英文领域,已经有一些较大的开源的三元组语料库,而很显然,中文目前还没有这样的语料库共享(哪怕有人爬取到了,也珍藏起来了)。笔者前段时间写了个百度百科的爬虫,爬了一段时间,抓了几百万个百度百科的词条。其中不少词条含有一些结构化的信息,直接抽取出来,就是有效的“三元组”了,可以用来做知识图谱。本文分享的三元组语料正是由此而来,共有2500万个三元组。

百度百科的三元组
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 200488位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
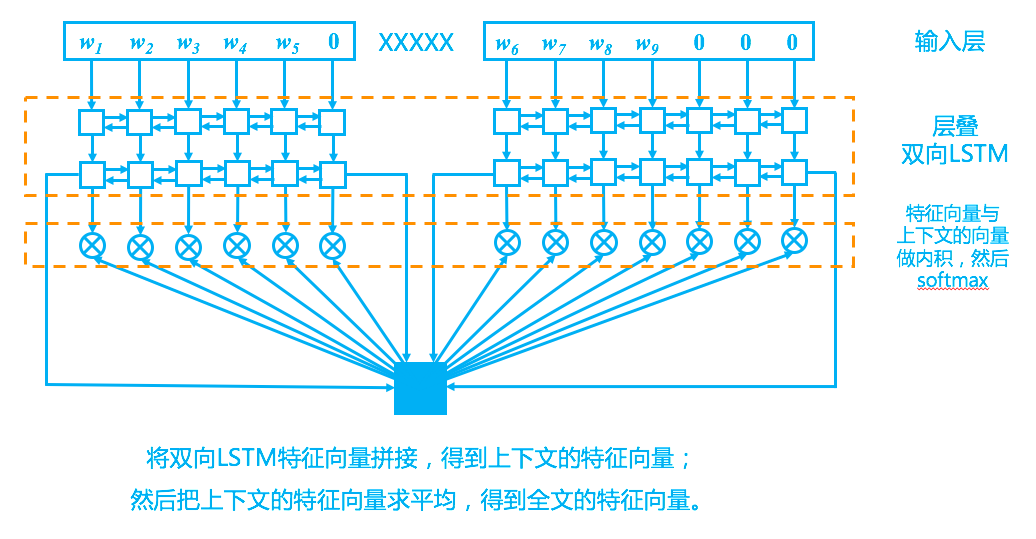
完形填空模型
16
Jul
Linux下的误删大坑与简单的恢复技巧
By 苏剑林 | 2017-07-16 | 28444位读者 | 引用
6
Oct
从马尔科夫过程到主方程(推导过程)
By 苏剑林 | 2017-10-06 | 72755位读者 | 引用主方程(master equation)是对随机过程进行建模的重要方法,它代表着马尔科夫过程的微分形式,我们的专业主要工具之一就是主方程,说宏大一点,量子力学和统计力学等也不外乎是主方程的一个特例。
然而,笔者阅读了几个著作,比如《统计物理现代教程》,还有我导师的《生物系统的随机动力学》,我发现这些著作对于主方程的推导都很模糊,他们在着力解释结果的意义,但并不说明结果的思想来源,因此其过程难以让人信服。而知乎上有人提问《如何理解马尔科夫过程的主方程的推导过程?》但没有得到很好的答案,也表明了这个事实。
马尔可夫过程
主方程是用来描述马尔科夫过程的,而马尔科夫过程可以理解为运动的无记忆性,说通俗点,就是下一刻的概率分布,只跟当前时刻有关,跟历史状态无关。用概率公式写出来就是(这里只考虑连续型概率,因此这里的$p$是概率密度):
$$\begin{equation}\label{eq:maerkefu}p(x,\tau)=\int p(x,\tau|y,t) p(y,t) dy\end{equation}$$
这里的积分区域是全空间。这里的$p(x,\tau|y,t)$称为跃迁概率,即已经确定了$t$时刻来到了$y$位置后、在$\tau$时刻达到$x$的概率密度,这个式子的物理意义是很明显的,就不多做解释了。
29
Jan
网站更新记录(2018年01月)
By 苏剑林 | 2018-01-29 | 30052位读者 | 引用也许读者会发现,这几天访问科学空间可能出现不稳定的情况,原因是我这几天都在对网站进行调整。
这次的调整幅度很大,不过从外表上可能很难发现,特此记录留念一下。主要的更新内容包括:
1、主题的优化:本博客用的geekg主题其实比较老了,去年花钱请人对它进行了第一次大升级,加入了响应式设计,这几天主要解决该主题的一些历史遗留问题,包括图片显示、边距、排版等细微调整;
2、内部的优化:大幅度减少了插件的使用,把一些基本的功能(如网站目录、归档页)等都内嵌到主题中,减少了对插件的依赖,也提升了可用性;
3、文章的优化:其实这也是个历史遗留问题,主要是早期写文章的时候比较随意,html代码、公式的LaTeX代码等都不规范,因此早期的文章显示效果可能比较糟糕,于是我就做了一件很疯狂的事情——把800多篇文章都过一遍!经过了两天多的时间,基本上修复了早期文章的大部分问题;
4、域名的优化:网站全面使用https!网站放在阿里云上面,可是阿里云有一套自以为是的监管系统,无故屏蔽我的一些页面。为了应对阿里云的恶意屏蔽,只好转向https,当然,这不会对读者平时访问造成影响,因为跳转https是自动的。目前两个域名spaces.ac.cn和kexue.fm都会自动跳转到https。

最近评论