






5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 89396位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 84099位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 46714位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}
20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 73906位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 95910位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 48967位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 91393位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
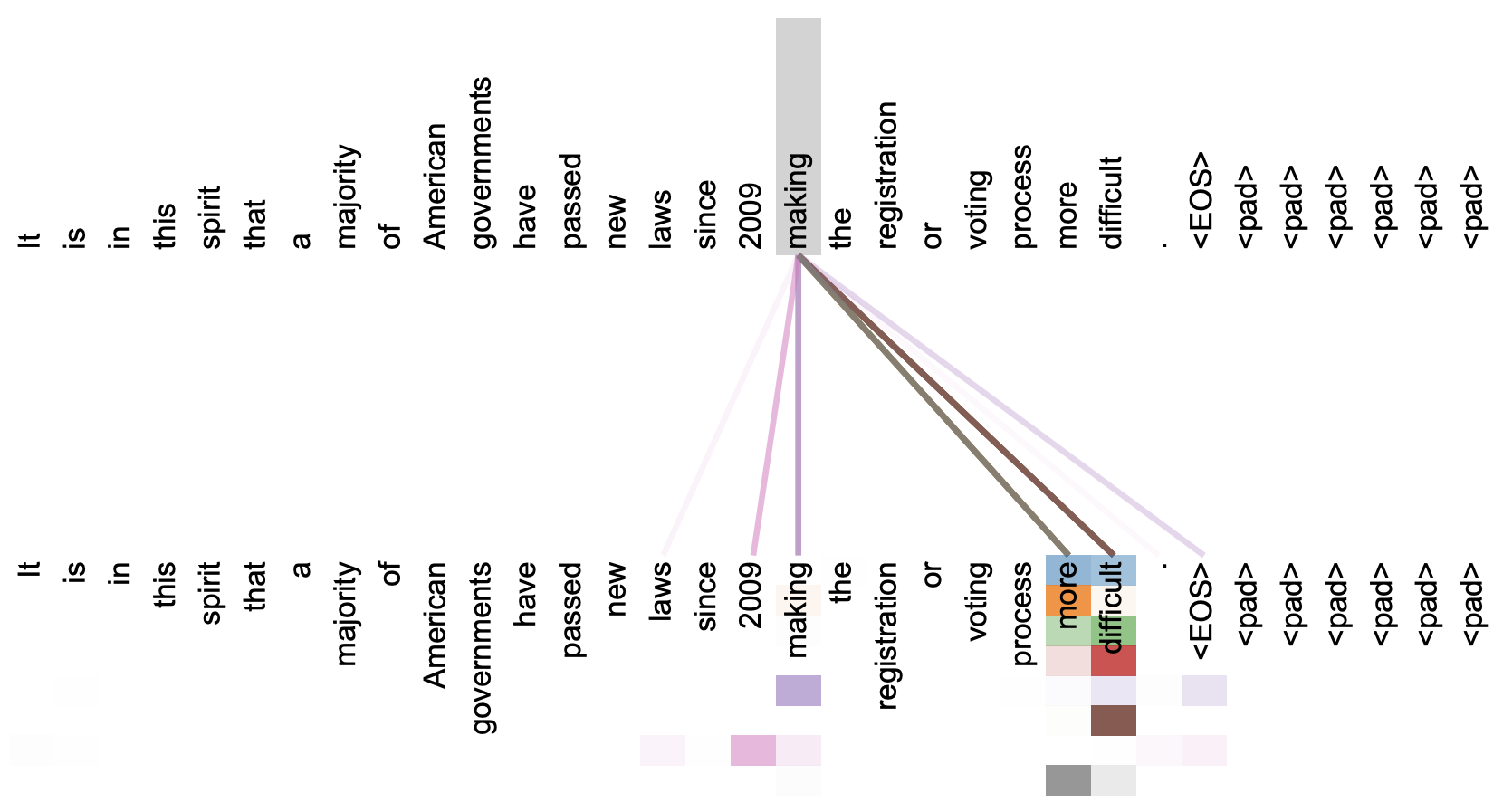
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 159031位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}

最近评论