






24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 62795位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
7
Feb
你的CRF层的学习率可能不够大
By 苏剑林 | 2020-02-07 | 147316位读者 | 引用CRF是做序列标注的经典方法,它理论优雅,实际也很有效,如果还不了解CRF的读者欢迎阅读旧作《简明条件随机场CRF介绍(附带纯Keras实现)》。在BERT模型出来之后,也有不少工作探索了BERT+CRF用于序列标注任务的做法。然而,很多实验结果显示(比如论文《BERT Meets Chinese Word Segmentation》)不管是中文分词还是实体识别任务,相比于简单的BERT+Softmax,BERT+CRF似乎并没有带来什么提升,这跟传统的BiLSTM+CRF或CNN+CRF的模型表现并不一样。

基于CRF的4标签分词模型示意图
这两天给bert4keras增加了用CRF做中文分词的例子(task_sequence_labeling_cws_crf.py),在调试过程中发现了CRF层可能存在学习不充分的问题,进一步做了几个对比实验,结果显示这可能是CRF在BERT中没什么提升的主要原因,遂在此记录一下分析过程,与大家分享。
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 448601位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
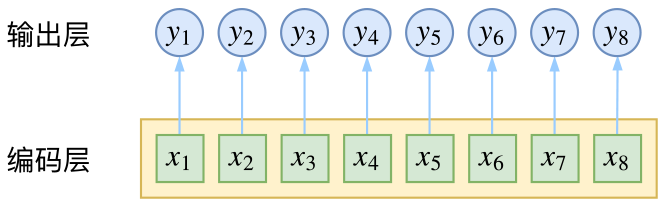
逐帧softmax并没有直接考虑输出的上下文关联
25
Nov
果壳中的条件随机场(CRF In A Nutshell)
By 苏剑林 | 2017-11-25 | 147956位读者 | 引用本文希望用尽可能简短的语言把CRF(条件随机场,Conditional Random Field)的原理讲清楚,这里In A Nutshell在英文中其实有“导论”、“科普”等意思(霍金写过一本《果壳中的宇宙》,这里东施效颦一下)。
网上介绍CRF的文章,不管中文英文的,基本上都是先说一些概率图的概念,然后引入特征的指数公式,然后就说这是CRF。所谓“概率图”,只是一个形象理解的说法,然而如果原理上说不到点上,你说太多形象的比喻,反而让人糊里糊涂,以为你只是在装逼。(说到这里我又想怼一下了,求解神经网络,明明就是求一下梯度,然后迭代一下,这多好理解,偏偏还弄个装逼的名字叫“反向传播”,如果不说清楚它的本质是求导和迭代求解,一下子就说反向传播,有多少读者会懂?)
好了,废话说完了,来进入正题。
逐标签Softmax
CRF常见于序列标注相关的任务中。假如我们的模型输入为$Q$,输出目标是一个序列$a_1,a_2,\dots,a_n$,那么按照我们通常的建模逻辑,我们当然是希望目标序列的概率最大
$$P(a_1,a_2,\dots,a_n|Q)$$
不管用传统方法还是用深度学习方法,直接对完整的序列建模是比较艰难的,因此我们通常会使用一些假设来简化它,比如直接使用朴素假设,就得到
$$P(a_1,a_2,\dots,a_n|Q)=P(a_1|Q)P(a_2|Q)\dots P(a_n|Q)$$

最近评论