






14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 31128位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 37867位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 9025位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
6
Feb
[SETI-50周年]送给外星人的礼物
By 苏剑林 | 2011-02-06 | 35008位读者 | 引用转载自2011年1月的《天文爱好者》 作者:钟晚晴
生命出现是天体演化的必然结果

探索地外文明
15世纪时,欧洲的文艺复兴运动引起了人们宇宙观的大革命。哥白尼学说的主要传播者之一,意大利思想家布魯诺毫不含糊地宣扬日心说并且提及“外星人”是否存在问题,他这样写到:“宇宙中存在着无数的太阳,存在着无数绕自己太阳运转的地球,就像我们的七个行星绕着我们的太陌运转似的……。在这些世界上居住着各种生物。”科学大师伽利略率先把望远镜指向星空,继而几百年以来有了一系列天文发现。太空视野的大幵阔常引发人类这样的追问:除了地球之外,茫茫宇宙中还存在别的文明星球吗?如果存在,能否找到人类的知音一智慧生命?
科学家通过研究地球化石发现,早在35亿年前地球上就已有了一种发育得比较高级的单细胞生物,即蓝藻类;根据恒星演化理论以及对地球上古老岩石和陨星物质分析知道,太阳和地球的形成比这种生物的出现至少还要早约十几亿年左右。太阳系自原始星云形成后大约经过50亿年地球上才有人类。此外,科学考察表明,在最近五亿年来(根据化石考查)已经有过五次生命大灭绝,人类是五亿年来最后一次灭绝以后从猿进化而来。天体的环境变化往往决定着许许多多生命的命运,例如6500万年前恐龙的绝灭,据说就是遭遇了寒冷的冰期或地球被一颗直径十几千米的小天体撞击的结果。
从20世纪初以来,天文学的研究成果是显著的,例如关于银河系的许多发现,河外星系及宇宙膨胀的发现,特别是后来发现类星体、星际分子、脉冲星、河外星系超新星爆发等等。在进入空间科学和电子计算机科学时代以来,人们对宇宙天体的研究更加深入,每年都有许多新的天体被发现、探究。
6
May
记录一次爬取淘宝/天猫评论数据的过程
By 苏剑林 | 2015-05-06 | 167836位读者 | 引用笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793
17
May
如何“扒”站?手把手教你爬百度百科~
By 苏剑林 | 2017-05-17 | 33042位读者 | 引用
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 201505位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
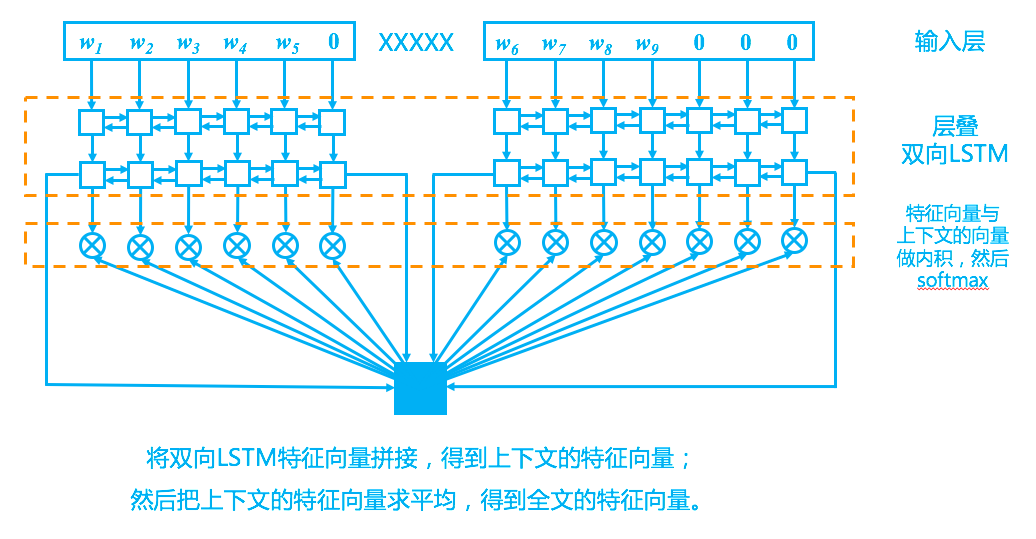
完形填空模型
6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 868396位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。

最近评论