






最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
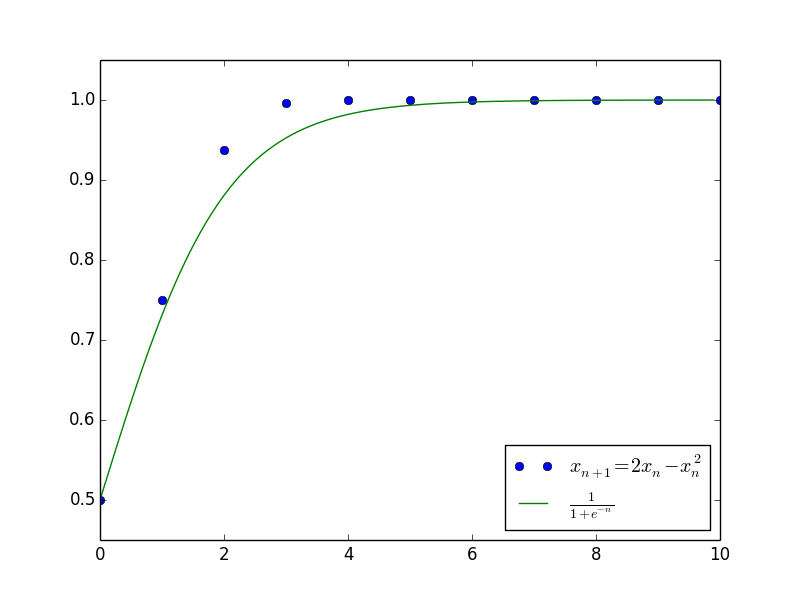
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
9
Jan
《量子力学与路径积分》习题解答V0.4
By 苏剑林 | 2016-01-09 | 31865位读者 | 引用
流年
《量子力学与路径积分》的习题解答终于艰难地推进到了0.4版本,目前已经基本完成了前7章的习题。
今天已经是2016年1月9号了,2015年已经远去,都忘记跟大家说一声新年快乐了,实在抱歉。在这里补充一句:祝大家新年快乐,事事如意!。
笔者已经大四了,现在是临近期末考,又临近毕业。最近忙的事情有很多,其中之一是我加入了一个互联网小公司的创业队伍中,负责文本挖掘,偶尔也写写爬虫,等等,感觉自己进去之后,增长了不少见识,也增加了不少技术知识,较之我上一次实习,又有不一样的高度。现在里边有好几样事情排队着做,可谓忙得不亦悦乎了。还有,我也开始写毕业论文了,早点写完能够多点时间,学学自己喜欢的东西,毕业论文我写的是路径积分相关的内容,自我感觉写得还是比较清楚易懂的,等时机成熟了,发出来,向大家普及路径积分^_^。此外,每天做点路径积分的习题,也要消耗不少时间,有些比较难的题目,基本一道就做几个早上才能写出比较满意的答案。总感觉想学的想做的事情有很多,可是时间很少。
9
Apr
一个非线性差分方程的隐函数解
By 苏剑林 | 2016-04-09 | 40919位读者 | 引用问题来源
笔者经常学习的数学研发论坛曾有一帖讨论下述非线性差分方程的渐近求解:
$$a_{n+1}=a_n+\frac{1}{a_n^2},\, a_1=1$$
原帖子在这里,从这帖子中我获益良多,学习到了很多新技巧。主要思路是通过将两边立方,然后设$x_n=a_n^3$,变为等价的递推问题:
$$x_{n+1}=x_n+3+\frac{3}{x_n}+\frac{1}{x_n^2},\,x_1=1$$
然后可以通过巧妙的技巧得到渐近展开式:
$$x_n = 3n+\ln n+a+\frac{\frac{1}{3}(\ln n+a)-\frac{5}{18}}{n}+\dots$$
具体过程就不提了,读者可以自行到上述帖子学习。
然而,这种形式的解虽然精妙,但存在一些笔者不是很满意的地方:
1、解是渐近的级数,这就意味着实际上收敛半径为0;
2、是$n^{-k}$形式的解,对于较小的$n$难以计算,这都使得高精度计算变得比较困难;
3、当然,题目本来的目的是渐近计算,但是渐近分析似乎又没有必要展开那么多项;
4、里边带有了一个本来就比较难计算的极限值$a$;
5、求解过程似乎稍欠直观。
当然,上面这些缺点,有些是鸡蛋里挑骨头的。不过,也正是这些缺点,促使我寻找更好的形式的解,最终导致了这篇文章。
30
May
路径积分系列:1.我的毕业论文
By 苏剑林 | 2016-05-30 | 28169位读者 | 引用之前承诺过会把毕业论文共享出来,让大家批评指正,却一直偷懒没动。事实上,毕业论文的主要内容就是路径积分的一些入门级别的内容,标题为《随机游走、随机微分方程与偏微分方程的路径积分方法》。我的摘要是这样写的:
本文从随机游走模型出发,得到了关于随机游走模型的一般结果;然后基于随机游走模型引入了路径积分,并且通过路径积分方法,实现了随机游走、随机微分方程与抛物型微分方程的相互转化,并给出了一些计算案例.
路径积分方法是量子理论的一种形式,但实际上它可以抽象为一个有用的数学工具,本文的主要方法正是抽象后的路径积分;其次,量子力学中有一个相当典型的抛物型偏微分方程——薛定谔方程,物理学家已经对它进行了大量的研究,有众多的成果;而随机微分方程是一个微分方程的拓展,在物理、工程、金融等很多方面都有重要应用,这个领域中也有很多研究方法;最后,随机游走是一个简单而重要的模型,它是很多扩散模型的基础,而且具有容易使用计算机模拟的特性. 因此,实现三者的转化是很有意义的.
本文有一些新的内容,比如现有文献比较少研究的不对称随机游走方面、以及现有文献比较含糊的对路径积分的介绍等,可以供同好参考,希望借此方式,能够让一些读者以更简洁明了的方式理解路径积分. 但是本文主要是陈述性的,旨在在国内推广路径积分方法. 在国外,路径积分方法得到了相当的重视,它源于量子力学,但应用已经不仅仅限于量子力学,如著作[1],因此,推广路径积分方法、增加路径积分的中文资料,是很有意义和很有必要的事情.
本文所有推导和例子均以一维为例,相应的多维问题可以类似地计算。
30
May
路径积分系列:2.随机游走模型
By 苏剑林 | 2016-05-30 | 54512位读者 | 引用随机游走模型形式简单,但通过它可以导出丰富的结果,它是物理中各种扩散模型的基础之一,它也等价于随机过程中的布朗运动.
笔者所阅的文献表明,数学家已经对对称随机游走问题作了充分研究[2],也探讨了随机游走问题与偏微分方程的关系[3],并且还研究过不对称随机游走问题[4]. 然而,已有结果的不足之处有:1、在推导随机游走问题的概率分布或者偏微分方程之时,所用的方法不够简洁明了;2、没有研究更一般的不对称随机游走问题.
本章弥补了这一不足,首先通过母函数和傅里叶变换的方法,推导出了不对称随机游走问题所满足的偏微分方程,并且提出,由于随机游走容易通过计算机模拟,因此通过随机游走来模拟偏微分方程的解是一种有效的数值途径.
模型简介
本节通过一个本质上属于二项分布的走格子问题来引入随机游走.
考虑实数轴上的一个粒子,在$t=0$时刻它位于原点,每秒钟它以相等的概率向前或向后移动一格($+1$或$-1$),问$n$秒后它所处位置的概率分布.
9
Jun
路径积分系列:4.随机微分方程
By 苏剑林 | 2016-06-09 | 28688位读者 | 引用本章将路径积分用于随机微分方程,并且得到了与不对称随机游走一样的结果,从而证明了它与该模型的等价性.
将路径积分用于随机微分方程的研究,这一思路由来已久. 费曼在他的著作[5]中,已经建立了路径积分与线性随机微分方程的关系. 而对于非线性的情况,也有不少研究,但比较混乱,如文献[8]甚至给出了错误的结果.
本文从路径积分的离散化概念出发,明确地建立了两个路径积分微元的雅可比行列式关系,从而对非线性随机微分方程也建立了路径积分. 本文的结果跟文献[9]的结果是一致的.
概念
本文所研究的仅仅是随机常微分方程,它与一般的常微分方程的区别在于布朗运动项的引入,如常见的一类随机微分方程为
$$dx(t)=p(x(t),t)dt + \sqrt{\alpha} dW_t.\tag{48}$$
其中$W_t$代表着一个标准的布朗运动. 由于引入了随机项,所以解$x(t)$不再是确定的,而是有一定的概率分布.
在对随机微分方程中,感兴趣的量有很多,比如关于$x$的某个量的期望、方差,或者稳定性,等等. 随机微分方程领域中有各种分析的技巧,但是显然,直接求出$x(t)$的概率分布后对概率分布进行研究,是最理想最容易的方案. 路径积分正是给出了求概率分布的一个方法.
9
Jun
路径积分系列:5.例子和综述
By 苏剑林 | 2016-06-09 | 22172位读者 | 引用路径积分方法为解决某些随机问题带来了新视角.
一个例子:股票价格模型
考虑有风险资产(如股票),在$t$时刻其价格为$S_t$,考虑的时间区间为$[0,T]$,0表示初始时间,$T$表示为到期日. $S_t$看作是随时间变化的连续时间变量,并服从下列随机微分方程:
$$dS_t^0=rS_t^0 dt;\quad dS_t=S_t(\mu dt+\sigma dW_t).\tag{70}$$
其中,$\mu$和$\sigma$是两个常量,$W_t$是一个标准布朗运动.
关于$S_t$的方程是一个随机微分方程,一般解决思路是通过随机微积分. 随机微积分有别于一般的微积分的地方在于,随机微积分在做一阶展开的时候,不能忽略$dS_t^2$项,因为$dW_t^2=dt$. 比如,设$S_t=e^{x_t}$,则$x_t=\ln S_t$
$$\begin{aligned}dx_t=&\ln(S_t+dS_t)-\ln S_t=\frac{dS_t}{S_t}-\frac{dS_t^2}{2S_t^2}\\
=&\frac{S_t(\mu dt+\sigma dW_t)}{S_t}-\frac{[S_t(\mu dt+\sigma dW_t)]^2}{2S_t^2}\\
=&\mu dt+\sigma dW_t-\frac{1}{2}\sigma^2 dW_t^2\quad(\text{其余项均低于}dt\text{阶})\\
=&\left(\mu-\frac{1}{2}\sigma^2\right) dt+\sigma dW_t\end{aligned}
,\tag{71}$$
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 404475位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。

最近评论