






4
May
记录一次半监督的情感分析
By 苏剑林 | 2017-05-04 | 66472位读者 | 引用本文是一次不怎么成功的半监督学习的尝试:在IMDB的数据集上,用随机抽取的1000个标注样本训练一个文本情感分类模型,并且在余下的49000个测试样本中,测试准确率为73.48%。
思路
本文的思路来源于OpenAI的这篇文章:
《OpenAI新研究发现无监督情感神经元:可直接调控生成文本的情感》
文章里边介绍了一种无监督(实际上是半监督)做情感分类的模型的方法,并且实验效果很好。然而文章里边的实验很庞大,对于个人来说几乎不可能重现(在4块Pascal GPU花了1个月时间训练)。不过,文章里边的思想是很简单的,根据里边的思想,我们可以做个“山寨版”的。思路如下:
我们一般用深度学习做情感分类,比较常规的思路就是Embedding层+LSTM层+Dense层(Sigmoid激活),我们常说的词向量,相当于预训练了Embedding层(这一层的参数量最大,最容易过拟合),而OpenAI的思想就是,为啥不连LSTM层一并预训练了呢?预训练的方法也是用语言模型来训练。当然,为了使得预训练的结果不至于丢失情感信息,LSTM的隐藏层节点要大一些。
30
Mar
文本情感分类(四):更好的损失函数
By 苏剑林 | 2017-03-30 | 166332位读者 | 引用文本情感分类其实就是一个二分类问题,事实上,对于分类模型,都会存在这样一个毛病:优化目标跟考核指标不一致。通常来说,对于分类(包括多分类),我们都会采用交叉熵作为损失函数,它的来源就是最大似然估计(参考《梯度下降和EM算法:系出同源,一脉相承》)。但是,我们最后的评估目标,并非要看交叉熵有多小,而是看模型的准确率。一般来说,交叉熵很小,准确率也会很高,但这个关系并非必然的。
要平均,不一定要拔尖
一个更通俗的例子是:一个数学老师,在努力提高同学们的平均分,但期末考核的指标却是及格率(60分及格)。假如平均分是100分(也就意味着所有同学都考到了100分),那么自然及格率是100%,这是最理想的。但现实不一定这么美好,平均分越高,只要平均分还没有达到100,那么及格率却不一定越高,比如两个人分别考40和90,那么平均分就是65,及格率只有50%;如果两个人的成绩都是60,平均分就是60,及格率却有100%。这也就是说,平均分可以作为一个目标,但这个目标并不直接跟考核目标挂钩。
那么,为了提升最后的考核目标,这个老师应该怎么做呢?很显然,首先看看所有学生中,哪些同学已经及格了,及格的同学先不管他们,而针对不及格的同学进行补课加强,这样一来,原则上来说有很多不及格的同学都能考上60分了,也有可能一些本来及格的同学考不够60分了,但这个过程可以迭代,最终使得大家都在60分以上,当然,最终的平均分不一定很高,但没办法,谁叫考核目标是及格率呢?
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 532435位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 765474位读者 | 引用
22
Jun
文本情感分类(一):传统模型
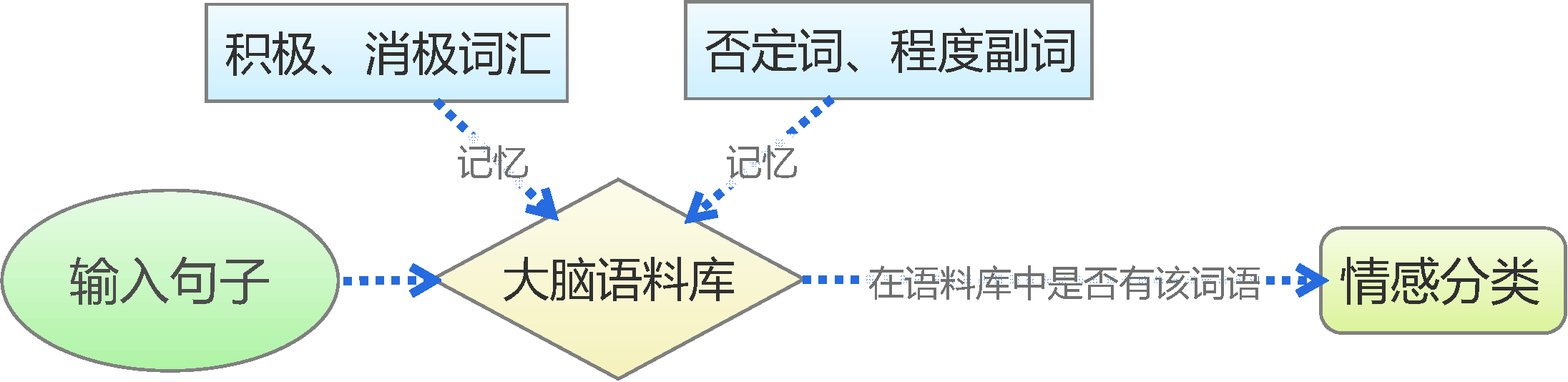
By 苏剑林 | 2015-06-22 | 309526位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
人的最简单的判断思维

最近评论