






31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 106757位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 55970位读者 | 引用生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
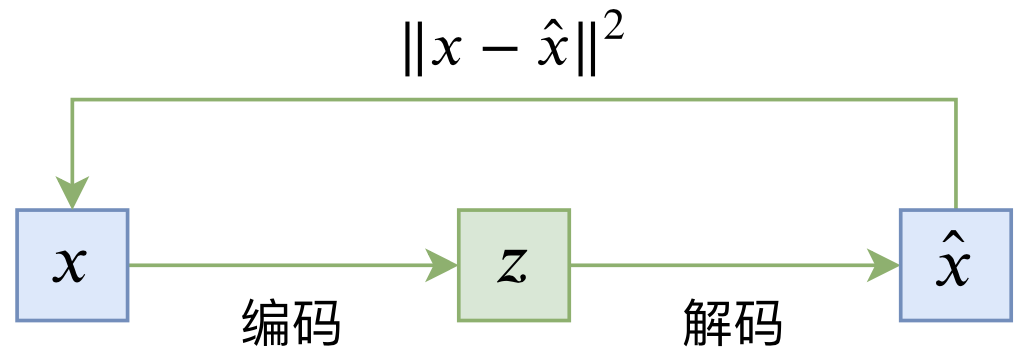
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 66280位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
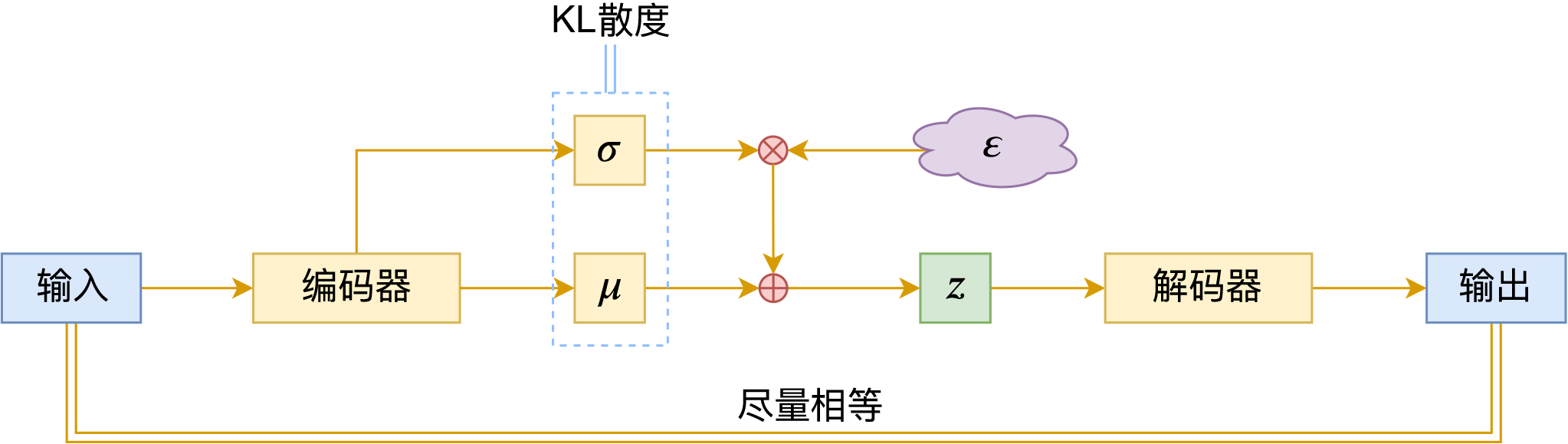
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 131313位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 59521位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
6
Nov
VQ的又一技巧:给编码表加一个线性变换
By 苏剑林 | 2024-11-06 | 4450位读者 | 引用在《VQ的旋转技巧:梯度直通估计的一般推广》中,我们介绍了VQ(Vector Quantization)的Rotation Trick,它的思想是通过推广VQ的STE(Straight-Through Estimator)来为VQ设计更好的梯度,从而缓解VQ的编码表坍缩、编码表利用率低等问题。
无独有偶,昨天发布在arXiv上的论文《Addressing Representation Collapse in Vector Quantized Models with One Linear Layer》提出了改善VQ的另一个技巧:给编码表加一个线性变换。这个技巧单纯改变了编码表的参数化方式,不改变VQ背后的理论框架,但实测效果非常优异,称得上是简单有效的经典案例。
6
Feb
[SETI-50周年]送给外星人的礼物
By 苏剑林 | 2011-02-06 | 34781位读者 | 引用转载自2011年1月的《天文爱好者》 作者:钟晚晴
生命出现是天体演化的必然结果

探索地外文明
15世纪时,欧洲的文艺复兴运动引起了人们宇宙观的大革命。哥白尼学说的主要传播者之一,意大利思想家布魯诺毫不含糊地宣扬日心说并且提及“外星人”是否存在问题,他这样写到:“宇宙中存在着无数的太阳,存在着无数绕自己太阳运转的地球,就像我们的七个行星绕着我们的太陌运转似的……。在这些世界上居住着各种生物。”科学大师伽利略率先把望远镜指向星空,继而几百年以来有了一系列天文发现。太空视野的大幵阔常引发人类这样的追问:除了地球之外,茫茫宇宙中还存在别的文明星球吗?如果存在,能否找到人类的知音一智慧生命?
科学家通过研究地球化石发现,早在35亿年前地球上就已有了一种发育得比较高级的单细胞生物,即蓝藻类;根据恒星演化理论以及对地球上古老岩石和陨星物质分析知道,太阳和地球的形成比这种生物的出现至少还要早约十几亿年左右。太阳系自原始星云形成后大约经过50亿年地球上才有人类。此外,科学考察表明,在最近五亿年来(根据化石考查)已经有过五次生命大灭绝,人类是五亿年来最后一次灭绝以后从猿进化而来。天体的环境变化往往决定着许许多多生命的命运,例如6500万年前恐龙的绝灭,据说就是遭遇了寒冷的冰期或地球被一颗直径十几千米的小天体撞击的结果。
从20世纪初以来,天文学的研究成果是显著的,例如关于银河系的许多发现,河外星系及宇宙膨胀的发现,特别是后来发现类星体、星际分子、脉冲星、河外星系超新星爆发等等。在进入空间科学和电子计算机科学时代以来,人们对宇宙天体的研究更加深入,每年都有许多新的天体被发现、探究。
4
Aug


最近评论