






21
Feb
大自然的隐身术——保护色
By 苏剑林 | 2010-02-21 | 36336位读者 | 引用
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 83250位读者 | 引用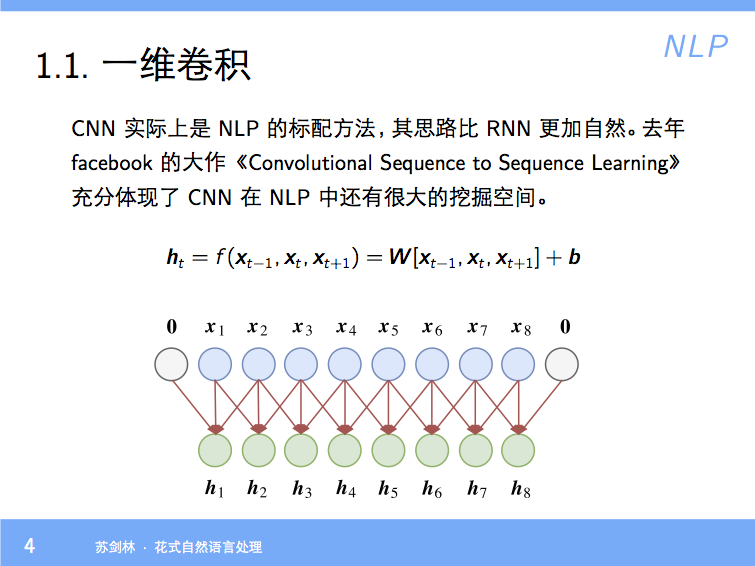
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 39078位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。

淡白口蘑
达尔文的进化学说告诉我们,自然界总是在众多的生物中挑出最能够适应环境的物种,赋予它们更高的生存几率,久而久之,这些物种经过亿万年的“优胜劣汰”,进化成了今天的千奇百怪的生物。无疑,经过长期的选择,优良的形状会被累积下来,换句话讲,这些物种在某些环境适应能力方面已经达到最优或近乎最优的状态(又是一个极值问题了)。好,现在我们来考虑蘑菇。
蘑菇是一种真菌生物,一般生长在阴暗潮湿的环境中。喜欢湿润的它自然也不希望散失掉过多的水分,因此,它努力地调整自身的形状,使它的“失水”尽可能地少。假设单位面积的蘑菇的失水速度是一致的,那么问题就变成了使一个给定体积的立体表面积尽可能少的问题了。并且考虑到水平各向同性生长的问题,理想的蘑菇形状应该就是一个平面图形的旋转体。那么这个旋转体是什么呢?聪明的你是否想到了是一个球体(的一部分)呢?
11
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(二)
By 苏剑林 | 2015-12-11 | 85069位读者 | 引用上集回顾
在第一篇中,笔者介绍了“熵”这个概念,以及它的一些来龙去脉。熵的公式为
$$S=-\sum_x p(x)\log p(x)\tag{1}$$
或
$$S=-\int p(x)\log p(x) dx\tag{2}$$
并且在第一篇中,我们知道熵既代表了不确定性,又代表了信息量,事实上它们是同一个概念。
说完了熵这个概念,接下来要说的是“最大熵原理”。最大熵原理告诉我们,当我们想要得到一个随机事件的概率分布时,如果没有足够的信息能够完全确定这个概率分布(可能是不能确定什么分布,也可能是知道分布的类型,但是还有若干个参数没确定),那么最为“保险”的方案是选择使得熵最大的分布。
最大熵原理
承认我们的无知
很多文章在介绍最大熵原理的时候,会引用一句著名的句子——“不要把鸡蛋放在同一个篮子里”——来通俗地解释这个原理。然而,笔者窃以为这句话并没有抓住要点,并不能很好地体现最大熵原理的要义。笔者认为,对最大熵原理更恰当的解释是:承认我们的无知!
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 56888位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
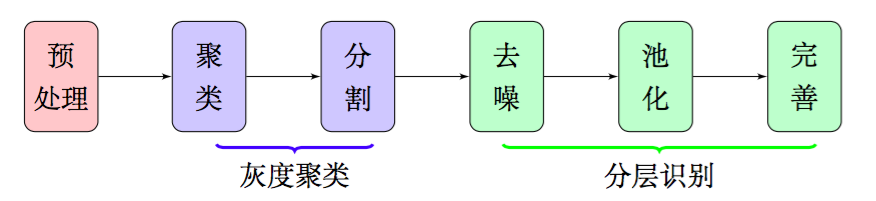
图2:特征提取大概流程
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 59419位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。

最近评论