






7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 104276位读者 | 引用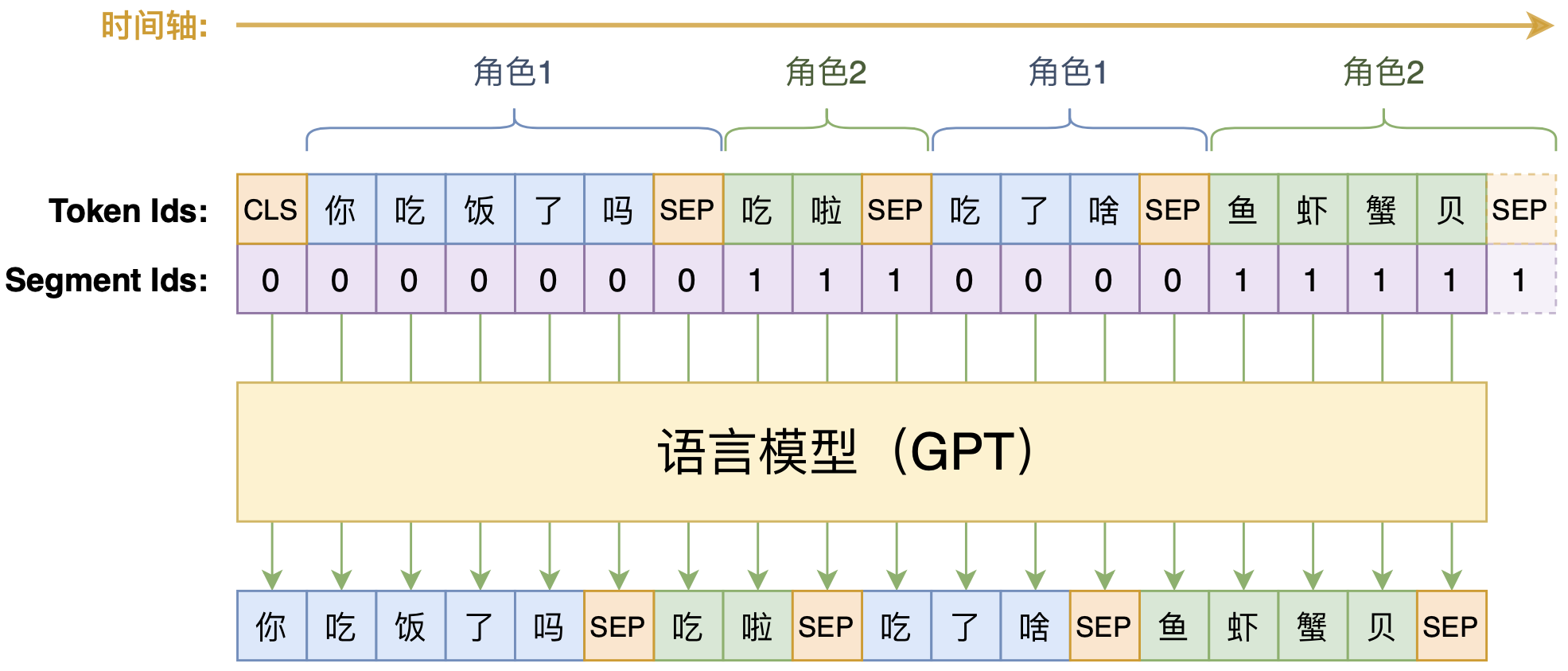
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 64614位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
23
Jun
从采样看优化:可导优化与不可导优化的统一视角
By 苏剑林 | 2020-06-23 | 57103位读者 | 引用不少读者都应该知道,损失函数与评测指标的不一致性是机器学习的典型现象之一,比如分类问题中损失函数用交叉熵,评测指标则是准确率或者F1,又比如文本生成中损失函数是teacher-forcing形式的交叉熵,评测指标则是BLEU、ROUGE等。理想情况下,当然是评测什么指标,我们就去优化这个指标,然而评测指标通常都是不可导的,而我们多数都是使用基于梯度的优化器,这就要求最小化的目标必须是可导的,这是不一致性的来源。
前些天在arxiv刷到了一篇名为《MLE-guided parameter search for task loss minimization in neural sequence modeling》的论文,顾名思义,它是研究如何直接优化文本生成的评测指标的。经过阅读,笔者发现这篇论文很有价值,事实上它提供了一种优化评测指标的新思路,适用范围并不局限于文本生成中。不仅如此,它甚至还包含了一种理解可导优化与不可导优化的统一视角。
采样视角
首先,我们可以通过采样的视角来重新看待优化问题:设模型当前参数为$\theta$,优化目标为$l(\theta)$,我们希望决定下一步的更新量$\Delta\theta$,为此,我们先构建分布
\begin{equation}p(\Delta\theta|\theta)=\frac{e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha}}{Z(\theta)},\quad Z(\theta) = \int e^{-[l(\theta + \Delta\theta) - l(\theta)]/\alpha} d(\Delta\theta)\end{equation}
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 93241位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 159007位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 115797位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
本文的问答生成模型示意图
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 67676位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
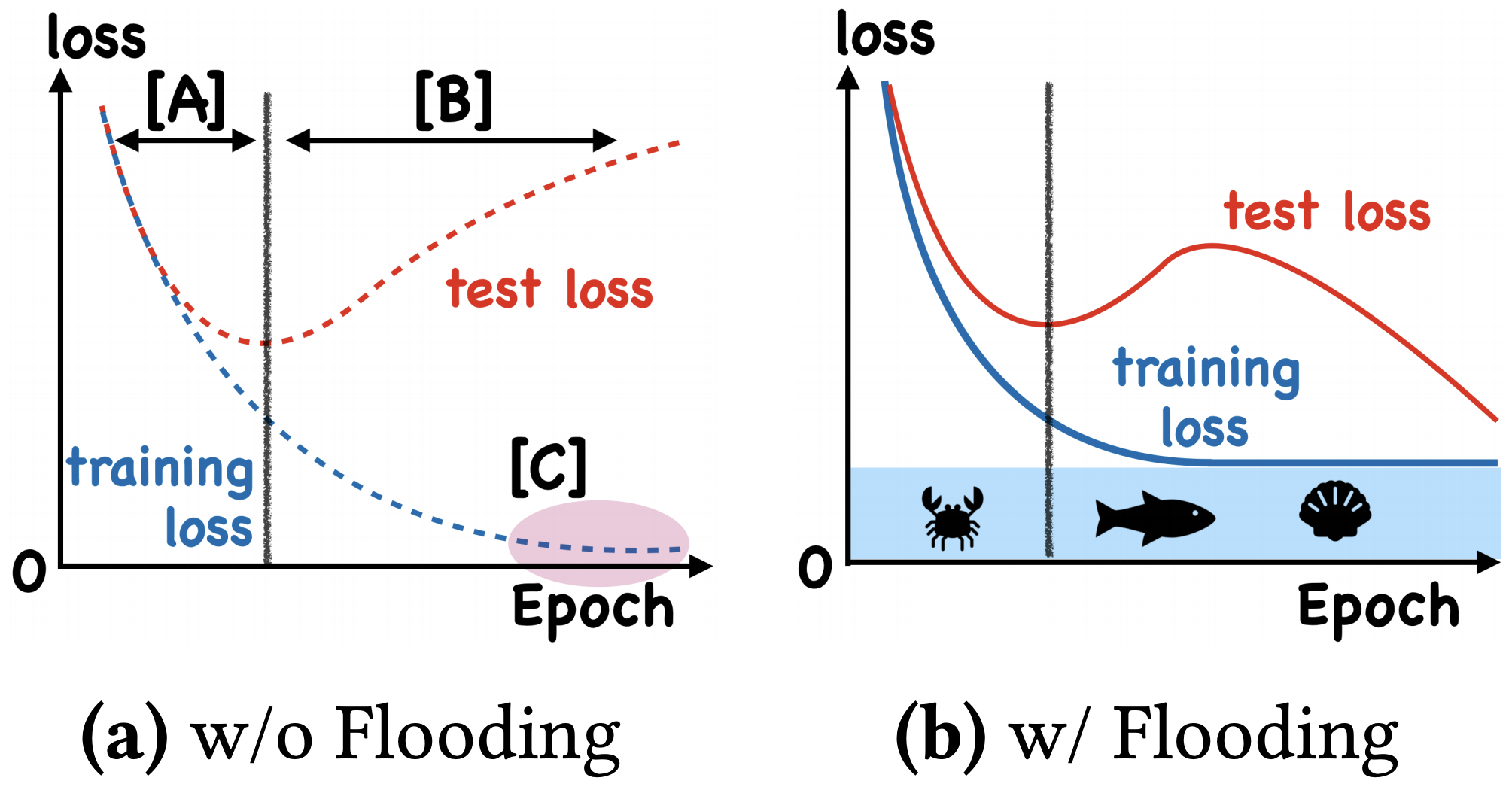
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
14
Aug
L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸
By 苏剑林 | 2020-08-14 | 36502位读者 | 引用L2正则是机器学习常用的一种防止过拟合的方法(应该也是一道经常遇到的面试题)。简单来说,它就是希望权重的模长尽可能小一点,从而能抵御的扰动多一点,最终提高模型的泛化性能。但是读者可能也会发现,L2正则的表现通常没有理论上说的那么好,很多时候加了可能还有负作用。最近的一篇文章《Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations》从“权重尺度偏移”这个角度分析了L2正则的弊端,并提出了新的WEISSI正则项。整个分析过程颇有意思,在这里与大家分享一下。
相关内容
这一节中我们先简单回顾一下L2正则,然后介绍它与权重衰减的联系以及与之相关的AdamW优化器。
L2正则的理解
为什么要添加L2正则?这个问题可能有多个答案。有从Ridge回归角度回答的,有从贝叶斯推断角度回答的,这里给出从扰动敏感性的角度的理解。

最近评论