






25
May
从重参数的角度看离散概率分布的构建
By 苏剑林 | 2022-05-25 | 16615位读者 | 引用一般来说,神经网络的输出都是无约束的,也就是值域为$\mathbb{R}$,而为了得到有约束的输出,通常是采用加激活函数的方式。例如,如果我们想要输出一个概率分布来代表每个类别的概率,那么通常在最后加上Softmax作为激活函数。那么一个紧接着的疑问就是:除了Softmax,还有什么别的操作能生成一个概率分布吗?
在《漫谈重参数:从正态分布到Gumbel Softmax》中,我们介绍了Softmax的重参数操作,本文将这个过程反过来,即先定义重参数操作,然后去反推对应的概率分布,从而得到一个理解概率分布构建的新视角。
问题定义
假设模型的输出向量为$\boldsymbol{\mu}=[\mu_1,\cdots,\mu_n]\in\mathbb{R}^n$,不失一般性,这里假设$\mu_i$两两不等。我们希望通过某个变换$\mathcal{T}$将$\boldsymbol{\mu}$转换为$n$元概率分布$\boldsymbol{p}=[p_1,\cdots,p_n]$,并保持一定的性质。比如,最基本的要求是:
\begin{equation}{\color{red}1.}\,p_i\geq 0 \qquad {\color{red}2.}\,\sum_i p_i = 1 \qquad {\color{red}3.}\,p_i \geq p_j \Leftrightarrow \mu_i \geq \mu_j\end{equation}
1
Jun
如何训练你的准确率?
By 苏剑林 | 2022-06-01 | 27592位读者 | 引用最近Arxiv上的一篇论文《EXACT: How to Train Your Accuracy》引起了笔者的兴趣,顾名思义这是介绍如何直接以准确率为训练目标来训练模型的。正好笔者之前也对此有过一些分析,如《函数光滑化杂谈:不可导函数的可导逼近》、《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》等, 所以带着之前的研究经验很快完成了论文的阅读,写下了这篇总结,并附上了最近关于这个主题的一些新思考。
失实的例子
论文开头指出,我们平时用的分类损失函数是交叉熵或者像SVM中的Hinge Loss,这两个损失均不能很好地拟合最终的评价指标准确率。为了说明这一点,论文举了一个很简单的例子:假设数据只有$\{(-0.25,-1),(0,-1),(0.25,,1)\}$三个点,$-1$和$1$分别代表负类和正类,待拟合模型是$f(x)=x-b$,$b$是参数,我们希望通过$\text{sign}(f(x))$来预测类别。如果用“sigmoid + 交叉熵”,那么损失函数就是$-\log \frac{1}{1+e^{-l \cdot f(x)}}$,$(x,l)$代表一对标签数据;如果用Hinge Loss,则是$\max(0, 1 - l\cdot f(x))$。
15
Jul
不成功的尝试:将多标签交叉熵推广到“n个m分类”上去
By 苏剑林 | 2022-07-15 | 24724位读者 | 引用可能有读者留意到,这次更新相对来说隔得比较久了。事实上,在上周末时就开始准备这篇文章了,然而笔者低估了这个问题的难度,几乎推导了整整一周,仍然还没得到一个完善的结果出来。目前发出来的,仍然只是一个失败的结果,希望有经验的读者可以指点指点。
在文章《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个多标签分类损失函数,它能自动调节正负类的不平衡问题,后来在《多标签“Softmax+交叉熵”的软标签版本》中我们还进一步得到了它的“软标签”版本。本质上来说,多标签分类就是“$n$个2分类”问题,那么相应的,“$n$个$m$分类”的损失函数又该是怎样的呢?
这就是本文所要探讨的问题。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 142616位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
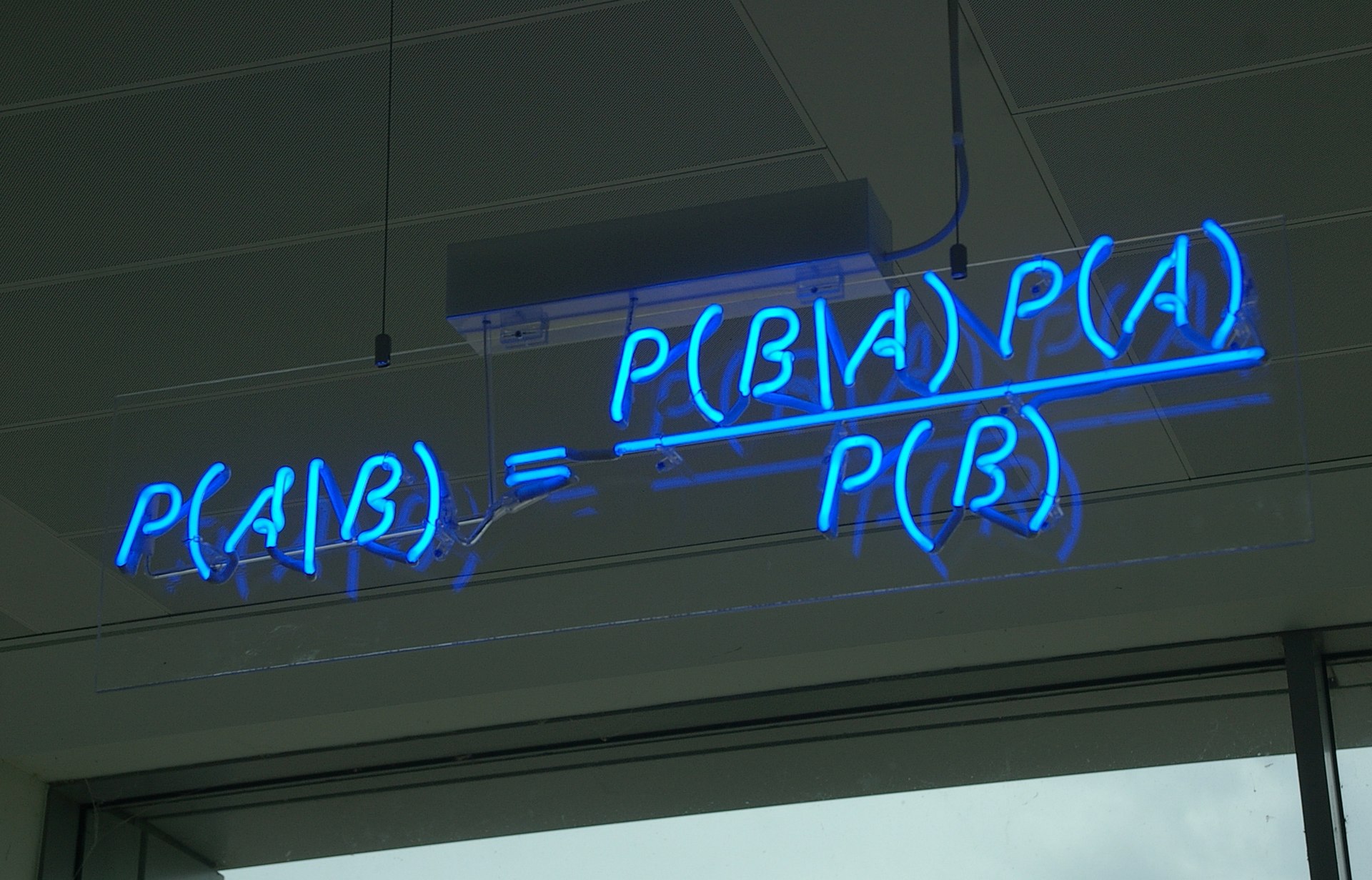
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 39611位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 129841位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 217146位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 77919位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。

最近评论